import :引入 python 标准库中的模块,这是引入某一模块的方法。
sleep :实现延时,单位为秒。(1000毫秒是1秒)
if __name__ == "__main__":
当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == ‘__main__'之下的代码块不被运行。
range
range() 函数可创建一个整数列表,一般用在 for 循环中。
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
threading
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。
enumerate():多用于在for循环中得到计数,返回的是一个enumerate对象
target:要执行的方法
start(): 开始线程活动(通过Thread类的start方法,可以启动该线程)
run(): 用以表示线程活动的方法。(当线程的run( )方法结束时该线程完成)
global
将变量定义为全局变量。可以通过定义为全局变量,实现在函数内部改变变量值。
append(): 方法用于在列表末尾添加新的对象。
创建锁 :mutex = threading.Lock()
锁定 :mutex.acquire()
释放 : mutex.release()
Process语法结构如下:
target:如果传递了函数的引用,可以任务这个子进程就执行这里的代码
args:给target指定的函数传递的参数,以元组的方式传递
kwargs:给target指定的函数传递命名参数
name:给进程设定一个名字,可以不设定
group:指定进程组,大多数情况下用不到
Process创建的实例对象的常用方法:
start():启动子进程实例(创建子进程)
is_alive():判断进程子进程是否还在活着
join 等待一个进程先执行完后再执行另外一个进程
join([timeout]):是否等待子进程执行结束,或等待多少秒
terminate():不管任务是否完成,立即终止子进程
Process创建的实例对象的常用属性:
name:当前进程的别名,默认为Process-N,N为从1开始递增的整数
pid:当前进程的pid(进程号)
shift+ctrl+t 开启多个终端窗口
ps -aux 查看进程
kill+ PID编码 杀死进程
kill空格-9 kill 强杀
多进程中主进程死了(终端结束),子进程会继续运行
多进程中,主进程和子进程是没有先后顺序Multiprocessing.process 进程多任务
os.getpid 查看pid(进程号)(子进程)
os.getppid 查看pid(进程号)(父进程)
Top /htop 查看系统状态 q退出
传参中:*args 元组 **kwargs 字典
多进程之间不共享全局变量
multiprocessing.Queue(数量) 队列
Queue.full 判断消息列队是否已满
Queue.get 取数据
Queue.empty 判断队列是否为空
Queue.put 写数据
Queue.qsize() 队列长度
multiprocessing.pool 进程池
multiprocessing.Pool常用函数解析:
apply_async(func[, args[, kwds]]) :使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表;
close():关闭Pool,使其不再接受新的任务;
terminate():不管任务是否完成,立即终止;
join():主进程阻塞,等待子进程的退出,必须在close或terminate之后
synchronize 同步
time.time 返回当前时间的时间戳(从1970到现在经过的浮点秒数)
Pool().apply_async(要调用的目标,(传递给目标的参数元祖,))
enumerate 以元组形式返回可迭代对象里元素的索引和元素
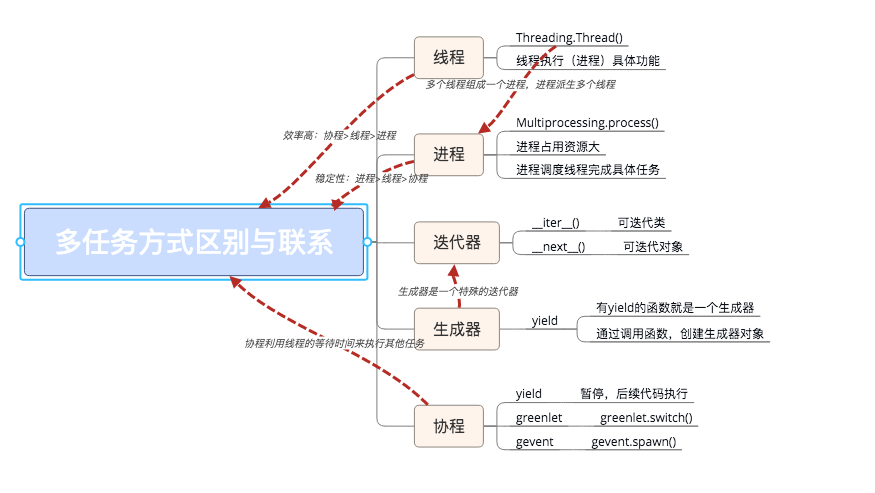
进程、线程、协程对比
请仔细理解如下的通俗描述
- 有一个老板想要开个工厂进行生产某件商品(例如剪子)
- 他需要花一些财力物力制作一条生产线,这个生产线上有很多的器件以及材料这些所有的 为了能够生产剪子而准备的资源称之为:进程
- 只有生产线是不能够进行生产的,所以老板的找个工人来进行生产,这个工人能够利用这些材料最终一步步的将剪子做出来,这个来做事情的工人称之为:线程
- 这个老板为了提高生产率,想到3种办法:
- 在这条生产线上多招些工人,一起来做剪子,这样效率是成倍増长,即单进程 多线程方式
- 老板发现这条生产线上的工人不是越多越好,因为一条生产线的资源以及材料毕竟有限,所以老板又花了些财力物力购置了另外一条生产线,然后再招些工人这样效率又再一步提高了,即多进程 多线程方式
- 老板发现,现在已经有了很多条生产线,并且每条生产线上已经有很多工人了(即程序是多进程的,每个进程中又有多个线程),为了再次提高效率,老板想了个损招,规定:如果某个员工在上班时临时没事或者再等待某些条件(比如等待另一个工人生产完谋道工序 之后他才能再次工作) ,那么这个员工就利用这个时间去做其它的事情,那么也就是说:如果一个线程等待某些条件,可以充分利用这个时间去做其它事情,其实这就是:协程方式
简单总结
- 进程是资源分配的单位
- 线程是操作系统调度的单位
- 进程切换需要的资源很最大,效率很低
- 线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
- 协程切换任务资源很小,效率高
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发