Task——Transformer

9.1 Transformer
Transformer 是一种新的、基于 attention 机制来实现的特征提取器,可用于代替 CNN 和 RNN 来提取序列的特征。
Transformer 首次由论文 《Attention Is All You Need》 提出,在该论文中 Transformer 用于 encoder - decoder 架构。事实上 Transformer 可以单独应用于 encoder 或者单独应用于 decoder 。
Transformer 相比较 LSTM 等循环神经网络模型的优点:
可以直接捕获序列中的长距离依赖关系。
模型并行度高,使得训练时间大幅度降低。
9.1.1 结构
论文中的 Transformer 架构包含了 encoder 和 decoder 两部分,其架构如下图所示。
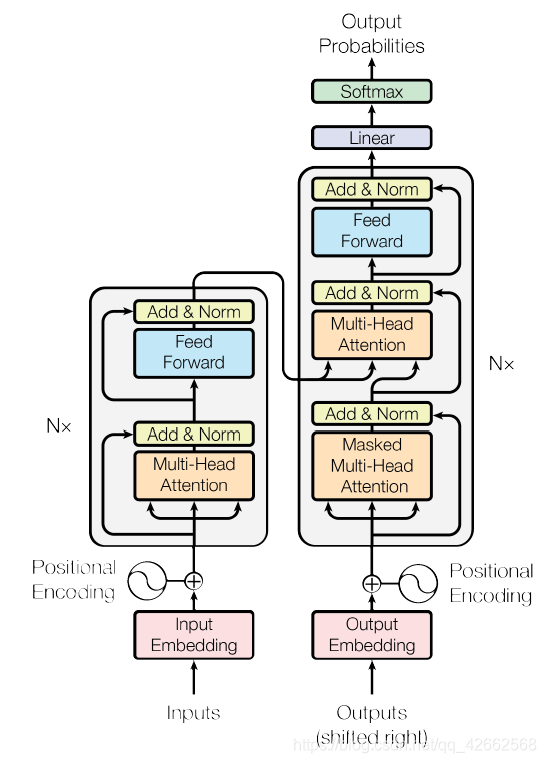
from:https://arxiv.org/pdf/1706.03762.pdf
在 Encoder 中,
- Input 经过 embedding 后,要做 positional encodings,
- 然后是 Multi-head attention,
- 再经过 position-wise Feed Forward,
- 每个子层之间有残差连接。
在 Decoder 中,
- 如上图所示,也有 positional encodings,Multi-head attention 和 FFN,子层之间也要做残差连接,
- 但比 encoder 多了一个 Masked Multi-head attention,
- 最后要经过 Linear 和 softmax 输出概率。
9.1.2 Encoder
- Input 经过 embedding 后,要做 positional encodings,
- 然后是 Multi-head attention,
- 再经过 position-wise Feed Forward,
- 每个子层之间有残差连接。
首先使用嵌入算法将输入的 word 转换为 vector,
最下面的 encoder ,它的输入就是 embedding 向量,
在每个 encoder 内部,
输入向量经过 self-attention,再经过 feed-forward 层,
每个 encoder 的输出向量是它正上方 encoder 的输入,
向量的大小是一个超参数,通常设置为训练集中最长句子的长度。
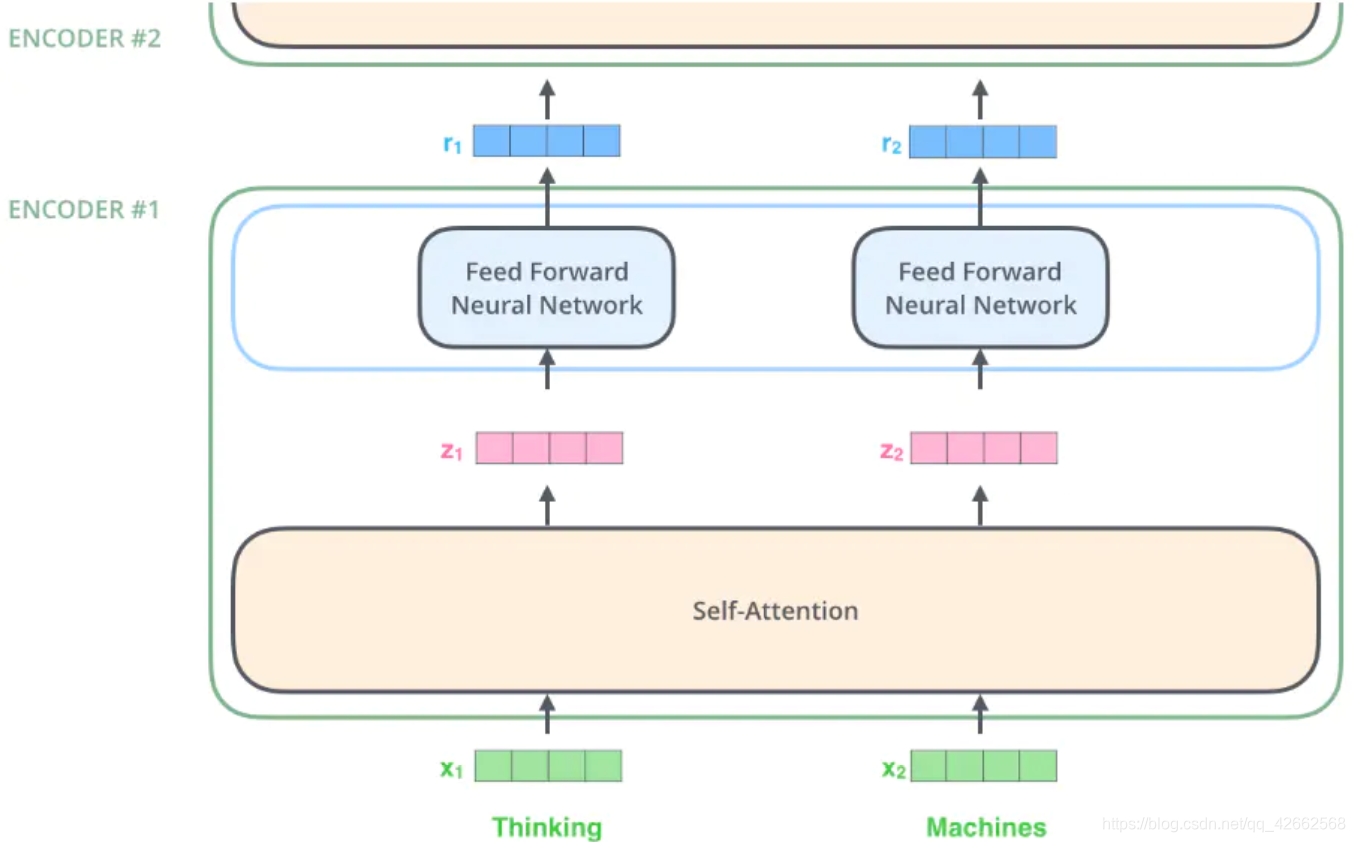
在这里,我们开始看到 Transformer 的一个关键性质,
即每个位置的单词在 encoder 中都有自己的路径,
self-attention 层中的这些路径之间存在依赖关系,
然而在 feed-forward 层不具有那些依赖关系,
这样各种路径在流过 feed-forward 层时可以并行执行。
9.1.3 Decoder
参见文章https://www.jianshu.com/p/e7d8caa13b21
import zipfile
import torch
import requests
from io import BytesIO
from torch.utils import data
import sys
import collections
class Vocab(object): # This class is saved in d2l.
def __init__(self, tokens, min_freq=0, use_special_tokens=False):
# sort by frequency and token
counter = collections.Counter(tokens)
token_freqs = sorted(counter.items(), key=lambda x: x[0])
token_freqs.sort(key=lambda x: x[1], reverse=True)
if use_special_tokens:
# padding, begin of sentence, end of sentence, unknown
self.pad, self.bos, self.eos, self.unk = (0, 1, 2, 3)
tokens = ['', '', '', '']
else:
self.unk = 0
tokens = ['']
tokens += [token for token, freq in token_freqs if freq >= min_freq]
self.idx_to_token = []
self.token_to_idx = dict()
for token in tokens:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
def __len__(self):
return len(self.idx_to_token)
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)):
return self.token_to_idx.get(tokens, self.unk)
else:
return [self.__getitem__(token) for token in tokens]
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices]
else:
return [self.idx_to_token[index] for index in indices]
def load_data_nmt(batch_size, max_len, num_examples=1000):
"""Download an NMT dataset, return its vocabulary and data iterator."""
# Download and preprocess
def preprocess_raw(text):
text = text.replace('u202f', ' ').replace('xa0', ' ')
out = ''
for i, char in enumerate(text.lower()):
if char in (',', '!', '.') and text[i-1] != ' ':
out += ' '
out += char
return out
with open('/home/kesci/input/fraeng6506/fra.txt', 'r') as f:
raw_text = f.read()
text = preprocess_raw(raw_text)
# Tokenize
source, target = [], []
for i, line in enumerate(text.split('
')):
if i >= num_examples:
break
parts = line.split(' ')
if len(parts) >= 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
# Build vocab
def build_vocab(tokens):
tokens = [token for line in tokens for token in line]
return Vocab(tokens, min_freq=3, use_special_tokens=True)
src_vocab, tgt_vocab = build_vocab(source), build_vocab(target)
# Convert to index arrays
def pad(line, max_len, padding_token):
if len(line) > max_len:
return line[:max_len]
return line + [padding_token] * (max_len - len(line))
def build_array(lines, vocab, max_len, is_source):
lines = [vocab[line] for line in lines]
if not is_source:
lines = [[vocab.bos] + line + [vocab.eos] for line in lines]
array = torch.tensor([pad(line, max_len, vocab.pad) for line in lines])
valid_len = (array != vocab.pad).sum(1)
return array, valid_len
src_vocab, tgt_vocab = build_vocab(source), build_vocab(target)
src_array, src_valid_len = build_array(source, src_vocab, max_len, True)
tgt_array, tgt_valid_len = build_array(target, tgt_vocab, max_len, False)
train_data = data.TensorDataset(src_array, src_valid_len, tgt_array, tgt_valid_len)
train_iter = data.DataLoader(train_data, batch_size, shuffle=True)
return src_vocab, tgt_vocab, train_iter
import os
import d2l
os.environ["CUDA_VISIBLE_DEVICES"] = "1"
embed_size, embedding_size, num_layers, dropout = 32, 32, 2, 0.05
batch_size, num_steps = 64, 10
lr, num_epochs, ctx = 0.005, 250, d2l.try_gpu()
print(ctx)
num_hiddens, num_heads = 64, 4
src_vocab, tgt_vocab, train_iter = load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), embedding_size, num_hiddens, num_heads, num_layers,
dropout)
decoder = TransformerDecoder(
len(src_vocab), embedding_size, num_hiddens, num_heads, num_layers,
dropout)
model = d2l.EncoderDecoder(encoder, decoder)
d2l.train_s2s_ch9(model, train_iter, lr, num_epochs, ctx)
cpu
epoch 50,loss 0.048, time 53.3 sec
epoch 100,loss 0.040, time 53.4 sec
epoch 150,loss 0.037, time 53.5 sec
epoch 200,loss 0.036, time 53.6 sec
epoch 250,loss 0.035, time 53.5 sec
model.eval()
for sentence in ['Go .', 'Wow !', "I'm OK .", 'I won !']:
print(sentence + ' => ' + d2l.predict_s2s_ch9(
model, sentence, src_vocab, tgt_vocab, num_steps, ctx))
Go . => !
Wow ! => !
I'm OK . => ça va .
I won ! => j'ai gagné !
参考内容
[1] https://www.jianshu.com/p/e7d8caa13b21.
[2] https://zhuanlan.zhihu.com/p/44121378