内容目录:
- rabbitMQ
- python操作mysql,pymysql模块
- Python ORM框架,SQLAchemy模块
- Paramiko
- 其他with上下文切换
rabbitMQ
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
1、基本安装配置使用
安装
ubuntu系统上安装rabbitmq sudo apt install erlang sudo apt install rabbitmq-server #拷贝配置文件,否则连接rabbitmq会报错 cp /usr/share/doc/rabbitmq-server/rabbitmq.config.example.gz /etc/rabbitmq/ cd /etc/rabbitmq/ gunzip rabbitmq.config.example.gz /etc/init.d/rabbitmq-server start #启动 centos上 安装配置epel源 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 安装erlang $ yum -y install erlang 安装RabbitMQ $ yum -y install rabbitmq-server service rabbitmq-server start/stop python操作的客户端需要安装pika模块来操作rabbitmq python3 -m pip install pika
使用
基于queue方式实现的消费者和生产者模型
import queue
import threading
import time
message = queue.Queue(10)
def producer(i):#生产者方法
while True:
message.put('生产--'+str(i)) #添加到队列
time.sleep(1)
def consumer(i):#消费者方法
msg = message.get() #从队列中取消息
print(msg)
for i in range(3):#创建2个任务线程来生产
t = threading.Thread(target=producer, args=(i,))
t.start()
for i in range(10):#创建5个消费者任务来消费
t = threading.Thread(target=consumer, args=(i,))
t.start()
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
生产者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters
(host='192.168.139.137')) #创建连接
channel = connection.channel() #创建频道
channel.queue_declare(queue='hello') #定义队列名,和订阅者的一致
channel.basic_publish(exchange='',routing_key='hello',
body='Hello World!')#发布消息
print(" [x] Sent 'Hello World!'")
connection.close()
消费者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters
(host='192.168.139.137')) #建立连接
channel = connection.channel()#创建频道
channel.queue_declare\
(queue='hello') #定义一个rabbitMQ下的一个队列名,与发布者一致
def callback(ch, method, properties, body):#回调函数
print(" [x] Received %r" % body)
channel.basic_consume(callback,
queue='hello',
no_ack=True)#指定队列名核函数准备执行接收消息
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()#开始接收消息
2、acknowledgment 消息不丢失
no-ack = False,如果消费者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
我们在操作中只需在订阅者上添加no-ack=False设置就行,生产者不变
消费者代码:
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters
(host='192.168.139.137')) #建立连接
channel = connection.channel()#创建频道
channel.queue_declare\
(queue='hello') #定义一个rabbitMQ下的一个队列名
def callback(ch, method, properties, body):#回调函数
print(" [x] Received %r" % body)
time.sleep(3)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)#此处设置no_ack=False
# 表示中途断开rabbitmq会将将改任务添加到队列中
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()#开始接收消息
3、durable 消息不丢失
生产者
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters
(host='192.168.139.137')) #创建连接
channel = connection.channel() #创建频道
channel.queue_declare(queue='hello',
durable=True) #定义队列名,和接收者的一致
channel.basic_publish(exchange='',routing_key='hello',
properties=pika.BasicProperties
(delivery_mode=2),#make message persistent
body='Hello World!') #发布消息
print(" [x] Sent 'Hello World!'")
connection.close()
消费者
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters
(host='192.168.139.137')) #建立连接
channel = connection.channel()#创建频道
channel.queue_declare(queue='hello',
durable=True) #定义一个rabbitMQ下的一个队列名
def callback(ch, method, properties, body):#回调函数
print(" [x] Received %r" % body)
time.sleep(3)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello',
no_ack=False)#此处设置no_ack=False
# 表示中途断开rabbitmq会将将改任务添加到队列中
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()#开始接收消息
4、消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者2去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
订阅者代码和发布者均取消durable=True部分,测试时候只要开启多个订阅者执行就能看到第一个订阅者收第一个消息,第二个订阅者接收第二条消息。。。
消费者


import pika import time connection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.139.137')) #建立连接 channel = connection.channel()#创建频道 #channel.queue_declare(queue='hello',durable=True) #定义一个rabbitMQ下的一个队列名 channel.queue_declare(queue='hello') #定义一个rabbitMQ下的一个队列名 def callback(ch, method, properties, body):#回调函数 print(" [x] Received %r" % body) time.sleep(3) print('ok') ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(callback,queue='hello',no_ack=False)#此处设置no_ack=False 表示中途断开rabbitmq会将将改任务添加到队列中 print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()#开始接收消息
生产者
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.139.137')) #创建连接 channel = connection.channel() #创建频道 # channel.queue_declare(queue='hello',durable=True) #定义队列名,和接收者的一致 channel.queue_declare(queue='hello') #定义队列名,和接收者的一致 channel.basic_publish(exchange='',routing_key='hello', properties=pika.BasicProperties(delivery_mode=2),#make message persistent body='Hello World!') #发布消息 print(" [x] Sent 'Hello World!'") connection.close()
5、发布订阅
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
exchange type = fanout
测试过程中可以执行多个订阅者代码窗口,执行发布者代码发布消息,所有打开的订阅者窗口都会收到消息。
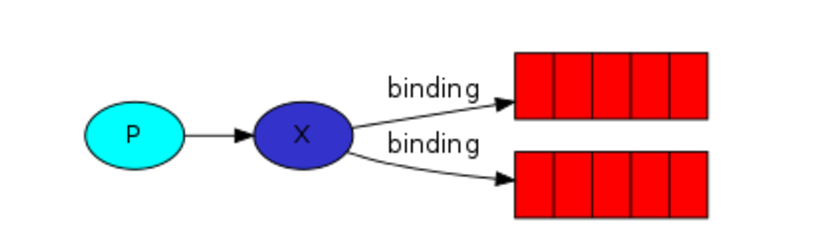
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.62.168'))#建立连接 channel = connection.channel()#创建频道 channel.exchange_declare(exchange='logs', type='fanout')#定义exchange,类型为fanout,fanout即为后端多个队列情况 message = ' '.join(sys.argv[1:]) or "info: Hello World!"#发送的消息 channel.basic_publish(exchange='logs', routing_key='', body=message) print(" [x] Sent %r" % message) connection.close()
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.62.168'))#建立rabbitMQ连接 channel = connection.channel() channel.exchange_declare(exchange='logs', type='fanout')#定义exchange由exchange来指定后端队列 result = channel.queue_declare(exclusive=True)#后端队列随机命名 queue_name = result.method.queue#队列名字 channel.queue_bind(exchange='logs', queue=queue_name)#将exchange和队列进行绑定 print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True)#调用callback函数 channel.start_consuming()#执行
6、关键字发送
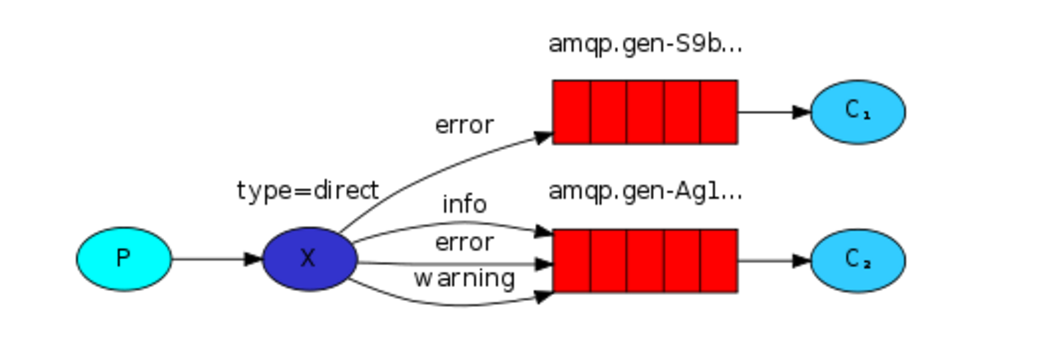
上面的事例中,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
exchange type = direct
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.62.168')) # 建立rabbitMQ连接 channel = connection.channel()#创建频道 channel.exchange_declare(exchange='direct_logs', type='direct')#关键字匹配type类型为direct severity = sys.argv[1] if len(sys.argv) > 1 else 'info' ''' 如果输入的参数长度大于1则将第一个参数传给serverity,否则小于1的话将inf传给serverity ''' message = ' '.join(sys.argv[2:]) or 'Hello World!' #将第二个参数传做字符串拼接传给message,或者将Hello World传给message channel.basic_publish(exchange='direct_logs', routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.62.168')) # 建立rabbitMQ连接 channel = connection.channel() channel.exchange_declare(exchange='direct_logs', type='direct') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue severities = sys.argv[1:]#执行时候需要传代参数,如果不对的话提示如下说明并推出程序,输入的参数做为关键字 if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0]) sys.exit(1) for severity in severities:#对输入的参数关键字进行循环,如果匹配上关键字就输出 channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
7、模糊匹配
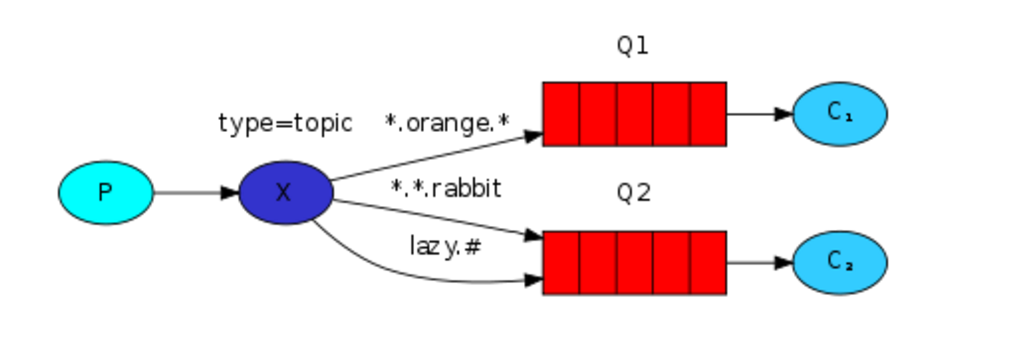
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
exchange type = topic
- # 表示可以匹配 0 个 或 多个 单词
- * 表示只能匹配 一个 单词
发送者路由值 队列中 test.jabe.com test.* -- 不匹配 test.jabe.com test.# -- 匹配
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.62.168')) # 建立rabbitMQ连接 channel = connection.channel()#创建频道 channel.exchange_declare(exchange='topic_logs', type='topic')#模糊匹配type类型为topic routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host='192.168.62.168')) # 建立rabbitMQ连接 channel = connection.channel() channel.exchange_declare(exchange='topic_logs', type='topic') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
pymysql模块
pymsql是Python中操作MySQL的模块,其使用方法和MySQLdb(py2中)几乎相同。
安装pymysql模块,在py2中模块名为MySQLdb
安装
python3 -m pip install pymysql
使用
1、执行SQL
#!/usr/bin/env python # -*- coding:utf-8 -*- import pymysql # 创建连接 conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') # 创建游标 cursor = conn.cursor() # 执行SQL,并返回收影响行数 effect_row = cursor.execute("update hosts set host = '1.1.1.2'") # 执行SQL,并返回受影响行数 #effect_row = cursor.execute("update hosts set host = '1.1.1.2' where nid > %s", (1,)) # 执行SQL,并返回受影响行数 #effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)]) # 提交,不然无法保存新建或者修改的数据 conn.commit() # 关闭游标 cursor.close() # 关闭连接 conn.close()
2、获取新创建数据自增ID
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') cursor = conn.cursor() cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)]) conn.commit() cursor.close() conn.close() # 获取最新自增ID new_id = cursor.lastrowid
3、获取查询数据
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') cursor = conn.cursor() cursor.execute("select * from hosts") # 获取第一行数据 row_1 = cursor.fetchone() # 获取前n行数据 # row_2 = cursor.fetchmany(3) # 获取所有数据 # row_3 = cursor.fetchall() conn.commit() cursor.close() conn.close() ''' 注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如: cursor.scroll(1,mode='relative') # 相对当前位置移动 cursor.scroll(2,mode='absolute') # 相对绝对位置移动 '''
4、fetch数据类型
关于默认获取的数据是元组类型,如果想要或者字典类型的数据,即:
import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') # 游标设置为字典类型 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) r = cursor.execute("call p1()") result = cursor.fetchone() conn.commit() cursor.close() conn.close()
SQLAchemy模块
QLAlchemy是Python编程语言下的一款ORM框架,该框架建立在数据库API之上,使用关系对象映射进行数据库操作,简言之便是:将对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
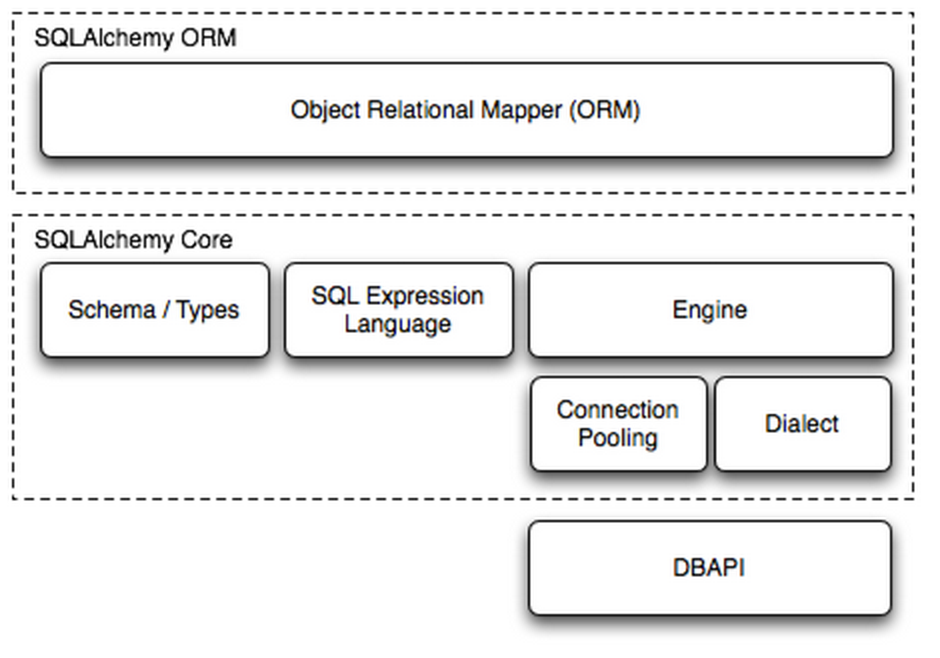
Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
步骤一:
使用 Engine/ConnectionPooling/Dialect 进行数据库操作,Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句。
from sqlalchemy import create_engine
engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5)
engine.execute(
"INSERT INTO ts_test (a, b) VALUES ('2', 'v1')"
)
engine.execute(
"INSERT INTO ts_test (a, b) VALUES (%s, %s)",
((555, "v1"),(666, "v1"),)
)
engine.execute(
"INSERT INTO ts_test (a, b) VALUES (%(id)s, %(name)s)",
id=999, name="v1"
)
result = engine.execute('select * from ts_test')
result.fetchall()
事务操作
from sqlalchemy import create_engine engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) # 事务操作 with engine.begin() as conn: conn.execute("insert into table (x, y, z) values (1, 2, 3)") conn.execute("my_special_procedure(5)") conn = engine.connect() # 事务操作 with conn.begin(): conn.execute("some statement", {'x':5, 'y':10})
注:查看数据库连接:show status like 'Threads%';
步骤二:
使用 Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 进行数据库操作。Engine使用Schema Type创建一个特定的结构对象,之后通过SQL Expression Language将该对象转换成SQL语句,然后通过 ConnectionPooling 连接数据库,再然后通过 Dialect 执行SQL,并获取结果。
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, ForeignKey
metadata = MetaData()
user = Table('user', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(20)),
)
color = Table('color', metadata,
Column('id', Integer, primary_key=True),
Column('name', String(20)),
)
engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5)
metadata.create_all(engine)
# metadata.clear()
# metadata.remove()
增删改查操作
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, ForeignKey metadata = MetaData() user = Table('user', metadata, Column('id', Integer, primary_key=True), Column('name', String(20)), ) color = Table('color', metadata, Column('id', Integer, primary_key=True), Column('name', String(20)), ) engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) conn = engine.connect() # 创建SQL语句,INSERT INTO "user" (id, name) VALUES (:id, :name) conn.execute(user.insert(),{'id':7,'name':'seven'}) conn.close() # sql = user.insert().values(id=123, name='wu') # conn.execute(sql) # conn.close() # sql = user.delete().where(user.c.id > 1) # sql = user.update().values(fullname=user.c.name) # sql = user.update().where(user.c.name == 'jack').values(name='ed') # sql = select([user, ]) # sql = select([user.c.id, ]) # sql = select([user.c.name, color.c.name]).where(user.c.id==color.c.id) # sql = select([user.c.name]).order_by(user.c.name) # sql = select([user]).group_by(user.c.name) # result = conn.execute(sql) # print result.fetchall() # conn.close()
注:SQLAlchemy无法修改表结构,如果需要可以使用SQLAlchemy开发者开源的另外一个软件Alembic来完成。
步骤三:
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。根据类创建对象,对象转换成SQL,执行SQL。
from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String from sqlalchemy.orm import sessionmaker from sqlalchemy import create_engine engine = create_engine("mysql+mysqldb://root:123@127.0.0.1:3306/s11", max_overflow=5) Base = declarative_base() class User(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String(50)) # 寻找Base的所有子类,按照子类的结构在数据库中生成对应的数据表信息 # Base.metadata.create_all(engine) Session = sessionmaker(bind=engine) session = Session() # ########## 增 ########## # u = User(id=2, name='sb') # session.add(u) # session.add_all([ # User(id=3, name='sb'), # User(id=4, name='sb') # ]) # session.commit() # ########## 删除 ########## # session.query(User).filter(User.id > 2).delete() # session.commit() # ########## 修改 ########## # session.query(User).filter(User.id > 2).update({'cluster_id' : 0}) # session.commit() # ########## 查 ########## # ret = session.query(User).filter_by(name='sb').first() # ret = session.query(User).filter_by(name='sb').all() # print ret # ret = session.query(User).filter(User.name.in_(['sb','bb'])).all() # print ret # ret = session.query(User.name.label('name_label')).all() # print ret,type(ret) # ret = session.query(User).order_by(User.id).all() # print ret # ret = session.query(User).order_by(User.id)[1:3] # print ret # session.commit()
Paramiko模块
paramiko模块,基于SSH用于连接远程服务器并执行相关操作。
1、安装模块
python3 -m pip install paramiko
2、使用
SSHClient
用于连接远程服务器并执行基本命令
import paramiko ssh = paramiko.SSHClient() # 创建SSH对象 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())# 允许连接不在know_hosts文件中的主机 ssh.connect(hostname='192.168.139.137',port=22,username='jabe',password='1234')# 连接服务器 stdin,stdout,stderr = ssh.exec_command('ls')# 执行命令 resault = stdout.read()# 获取命令结果 print(str(resault,encoding='utf-8')) #打印 ssh.close()
import paramiko transport = paramiko.Transport(('192.168.139.137', 22)) transport.connect(username='jabe', password='1234') ssh = paramiko.SSHClient() ssh._transport = transport stdin, stdout, stderr = ssh.exec_command('df') resault = stdout.read()# 获取命令结果 print(str(resault,encoding='utf-8')) transport.close()
SFTPClient
用于连接远程服务器并执行上传下载
基于用户名密码上传下载:
import paramiko transport = paramiko.Transport(('192.168.139.137',22)) transport.connect(username='jabe',password='1234') sftp = paramiko.SFTPClient.from_transport(transport) #sftp.put('s1.py', '/tmp/test.py') # 将s1.py 上传至服务器 /tmp/test.py sftp.get('/tmp/test.py', 'download.py') # 将remove_path 下载到本地 local_path transport.close()
基于公钥密钥上传下载:
import paramiko private_key = paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa') transport = paramiko.Transport(('hostname', 22)) transport.connect(username='wupeiqi', pkey=private_key ) sftp = paramiko.SFTPClient.from_transport(transport) # 将location.py 上传至服务器 /tmp/test.py sftp.put('/tmp/location.py', '/tmp/test.py') # 将remove_path 下载到本地 local_path sftp.get('remove_path', 'local_path') transport.close()
简单应用
import paramiko import uuid class SSHConnection(object): def __init__(self, host='172.16.103.191', port=22, username='wupeiqi',pwd='123'): self.host = host self.port = port self.username = username self.pwd = pwd self.__k = None def create_file(self): file_name = str(uuid.uuid4()) with open(file_name,'w') as f: f.write('sb') return file_name def run(self): self.connect() self.upload('/home/wupeiqi/tttttttttttt.py') self.rename('/home/wupeiqi/tttttttttttt.py', '/home/wupeiqi/ooooooooo.py) self.close() def connect(self): transport = paramiko.Transport((self.host,self.port)) transport.connect(username=self.username,password=self.pwd) self.__transport = transport def close(self): self.__transport.close() def upload(self,target_path): # 连接,上传 file_name = self.create_file() sftp = paramiko.SFTPClient.from_transport(self.__transport) # 将location.py 上传至服务器 /tmp/test.py sftp.put(file_name, target_path) def rename(self, old_path, new_path): ssh = paramiko.SSHClient() ssh._transport = self.__transport # 执行命令 cmd = "mv %s %s" % (old_path, new_path,) stdin, stdout, stderr = ssh.exec_command(cmd) # 获取命令结果 result = stdout.read() def cmd(self, command): ssh = paramiko.SSHClient() ssh._transport = self.__transport # 执行命令 stdin, stdout, stderr = ssh.exec_command(command) # 获取命令结果 result = stdout.read() return result ha = SSHConnection() ha.run()
# 对于更多限制命令,需要在系统中设置 /etc/sudoers Defaults requiretty Defaults:cmdb !requiretty
with上下文切换
with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
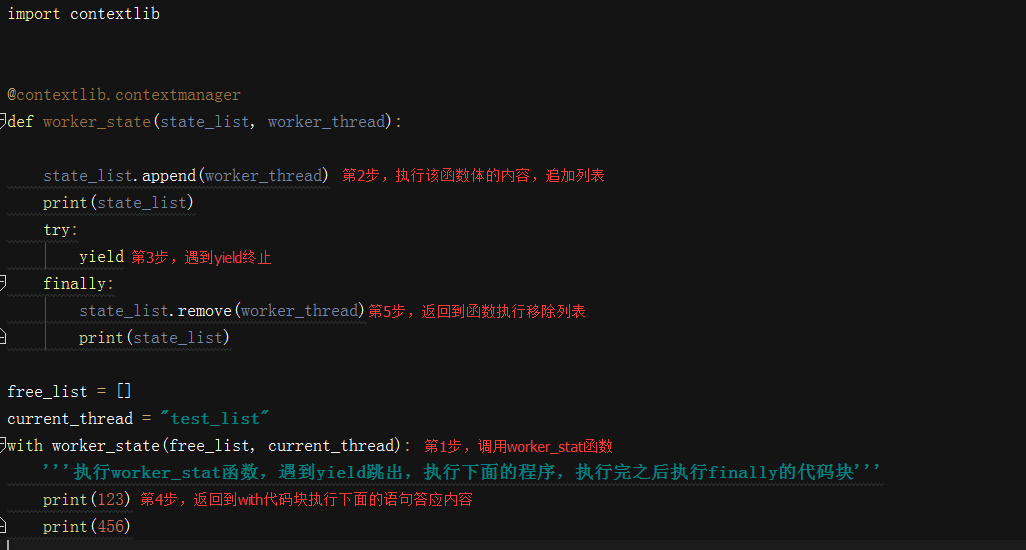
import contextlib @contextlib.contextmanager def worker_state(state_list, worker_thread): state_list.append(worker_thread) print(state_list) try: yield finally: state_list.remove(worker_thread) print(state_list) free_list = [] current_thread = "test_list" with worker_state(free_list, current_thread): '''执行worker_stat函数,遇到yield跳出,执行下面的程序,执行完之后执行finally的代码块''' print(123) print(456)
执行顺序如图所示
我们可以将socket做成with形式,其他的类似功能都可以这样来实现,用完之后自动关闭
import contextlib
import socket
@contextlib.contextmanager
def context_socket(host, port):
sk = socket.socket()
sk.bind((host,port))
sk.listen(5)
try:
yield sk
finally:
sk.close()
with context_socket('127.0.0.1', 8888) as sock:#将函数的yield以前的部分集成到sock中,
print(sock)
参考url:
http://www.cnblogs.com/wupeiqi/articles/5132791.html
http://www.cnblogs.com/wupeiqi/articles/5699254.html