查找和排序-实验报告
代码托管地址
实验-1
实验要求
完成教材P302 Searching.Java ,P305 Sorting.java中方法的测试
不少于10个测试用例,提交测试用例设计情况(正常,异常,边界,正序,逆序),用例数据中要包含自己学号的后四位
提交运行结果图(可多张)
实验步骤
- 在书上已写好的类的基础上添加测试用例
测试结果
正常
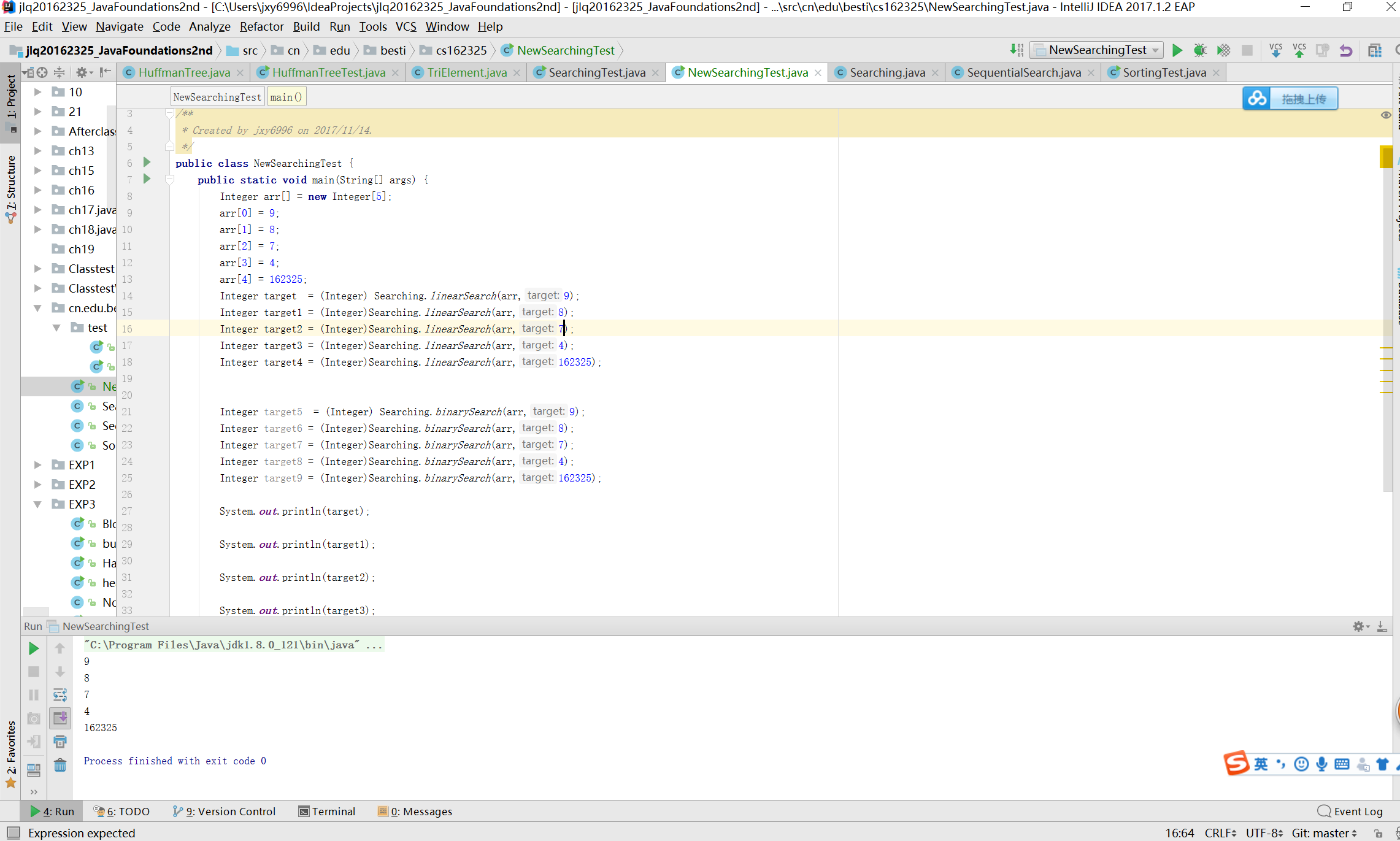
异常
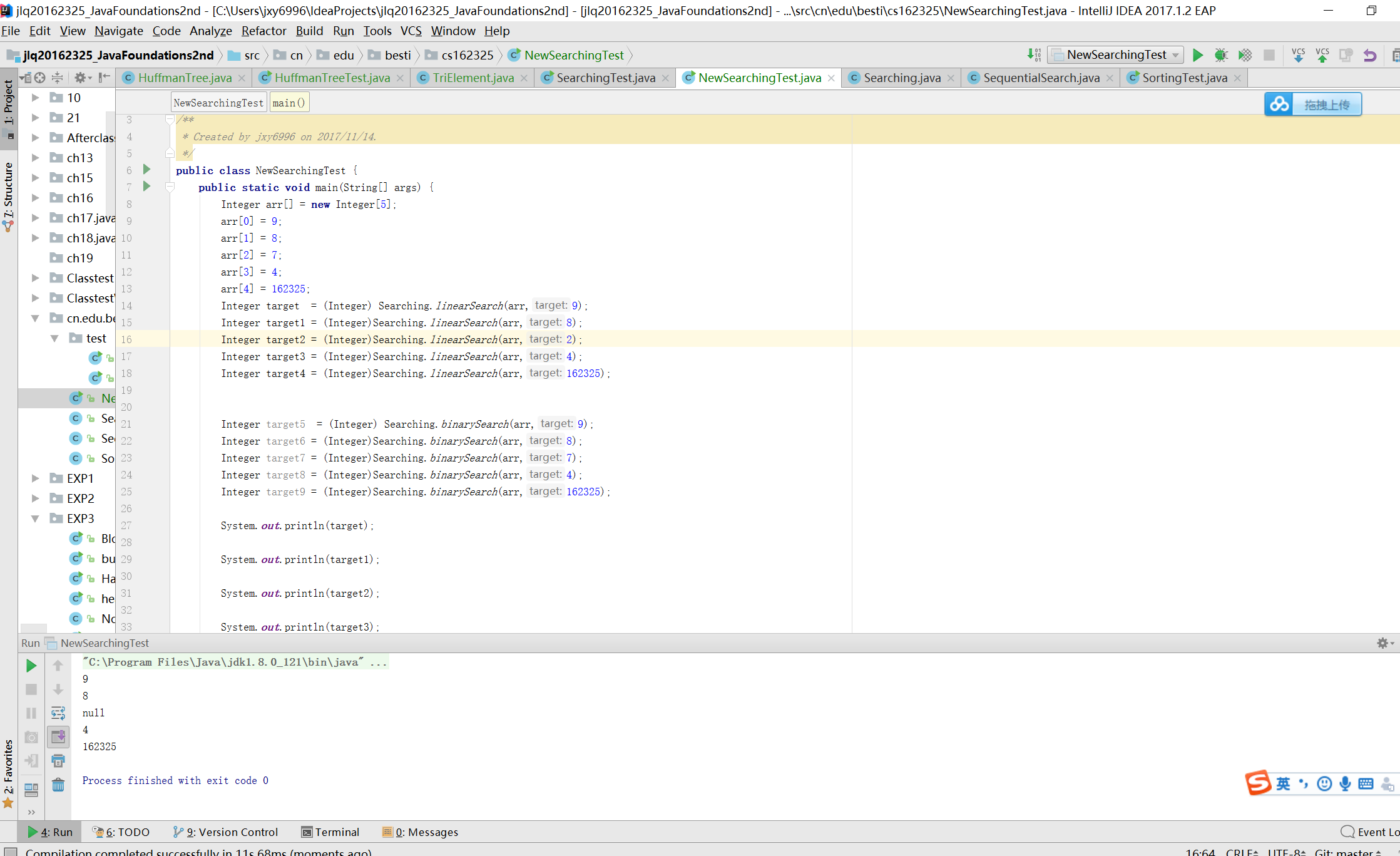
正序
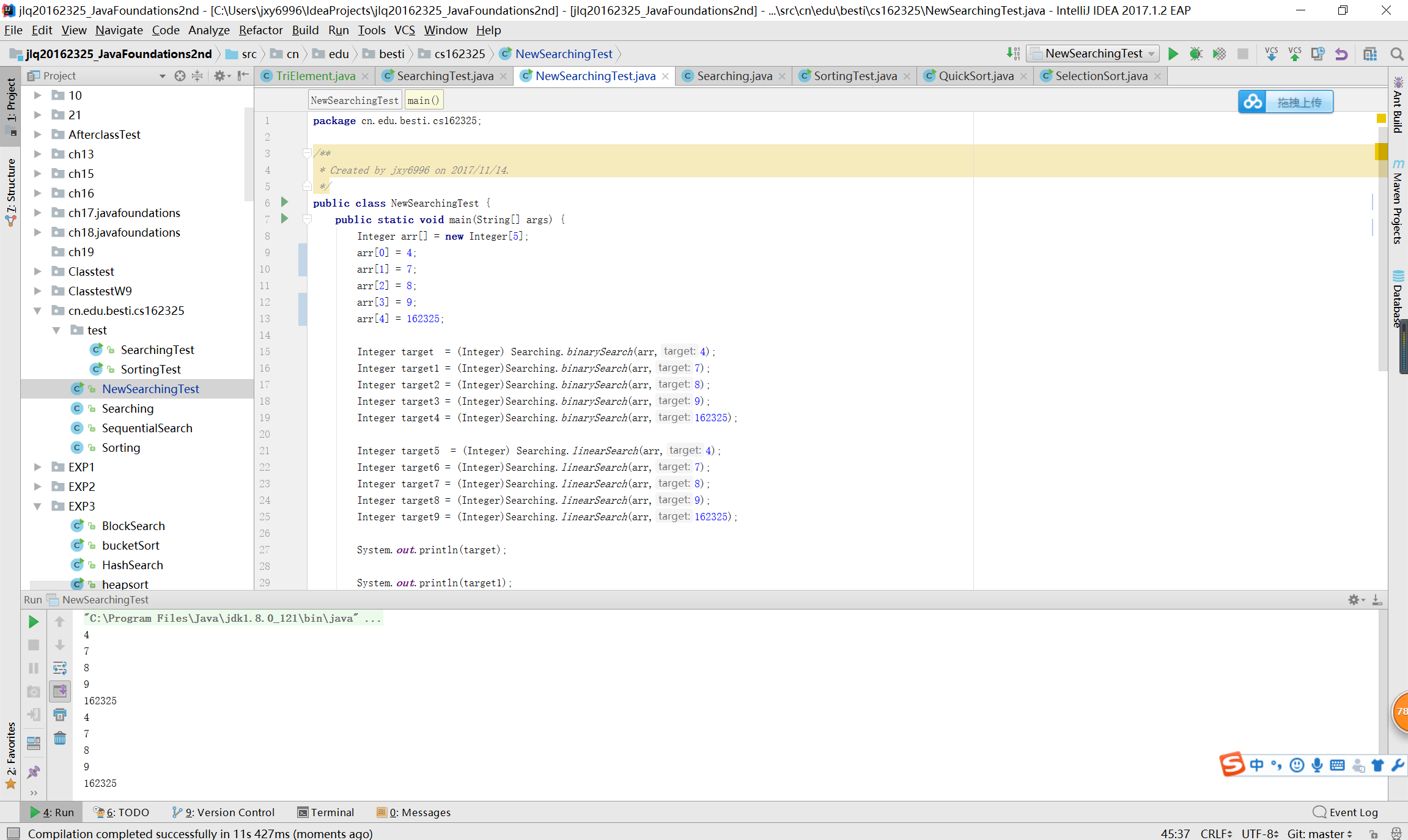
逆序
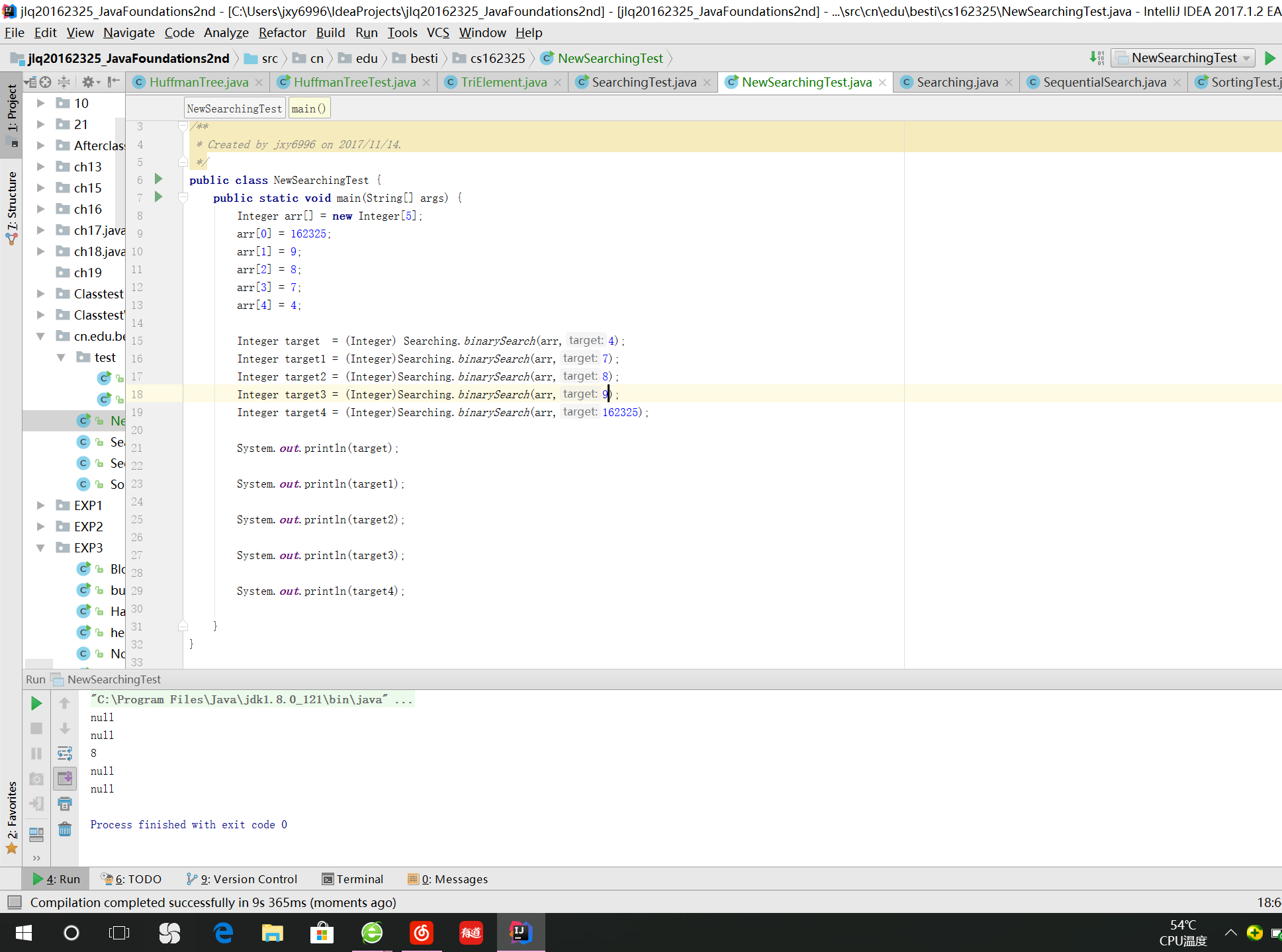
实验-2
实验要求
重构你的代码
把Sorting.java Searching.java放入 cn.edu.besti.cs1623.(姓名首字母+四位学号) 包中
把测试代码放test包中
重新编译,运行代码,提交编译,运行的截图(IDEA,命令行两种)
- 创建后,直接拖动新package里,改一下import
IDEA
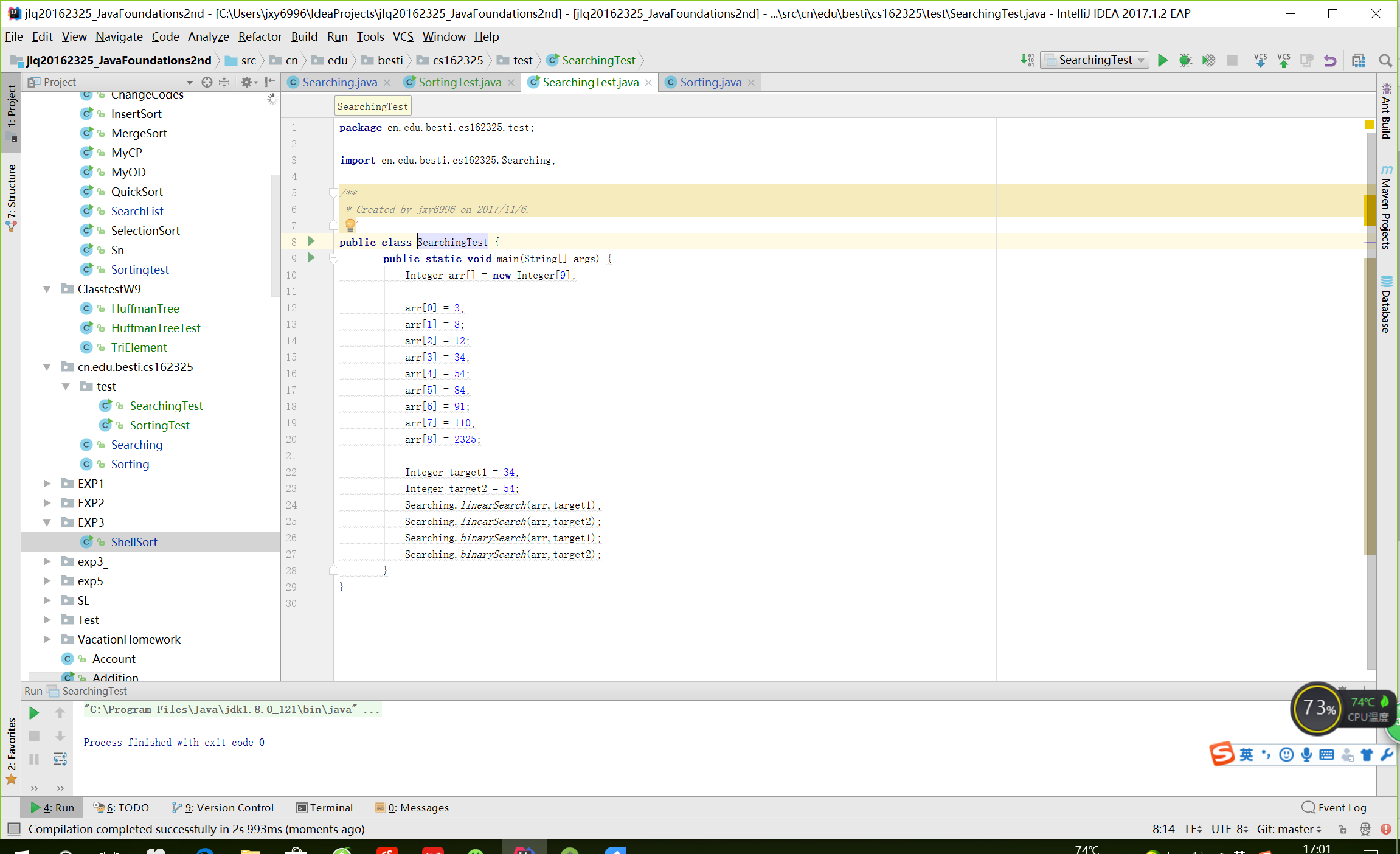
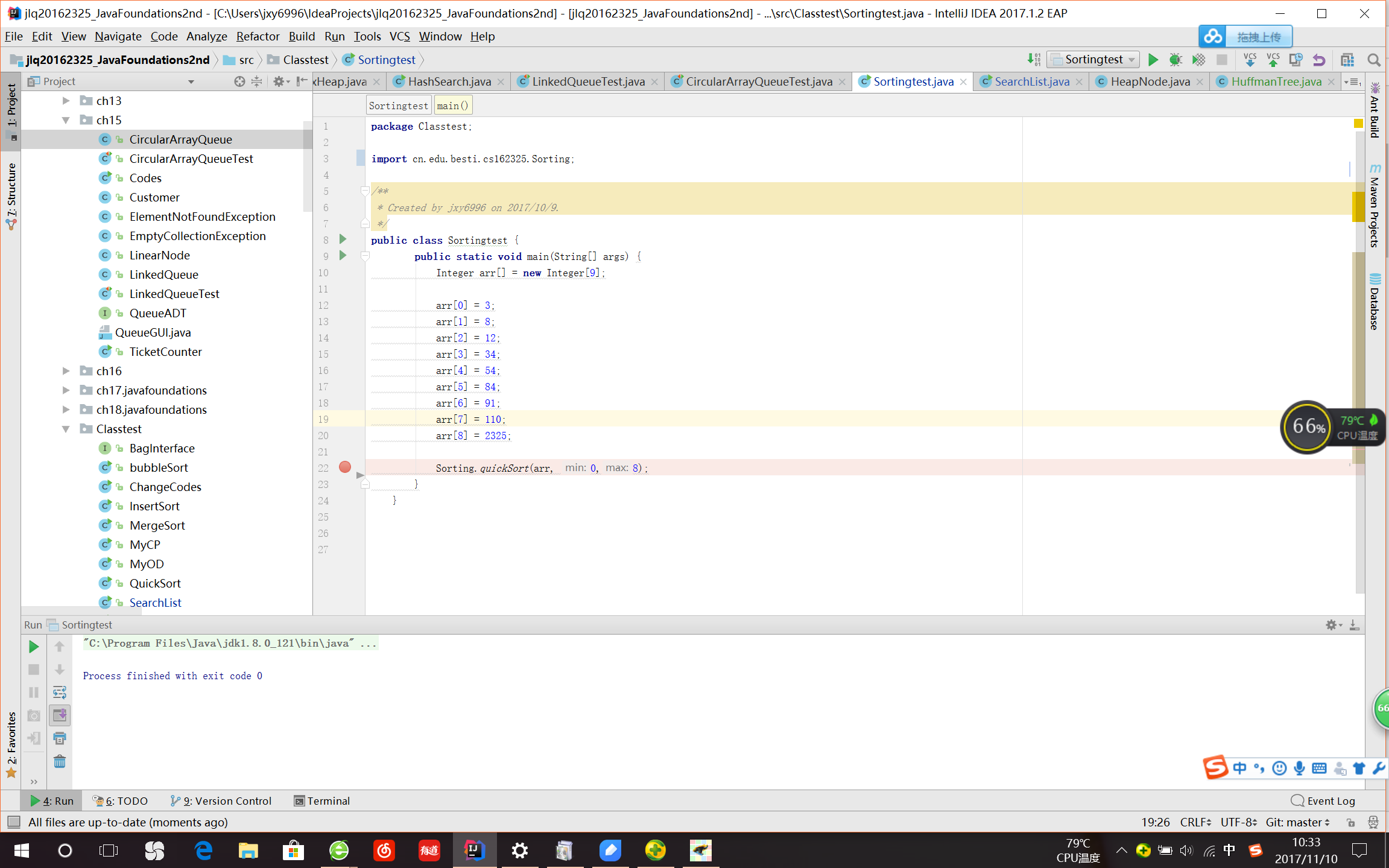
命令行
原本装的虚拟机在系统更新后消失了,IDEA里的终端又用不了,按照在新版 Win10 中启用 Linux Bash 环境_百度经验的步骤操作,可是遇到了错误代码:x80070005,上网搜了下,但win10 0x80070005 拒绝访问怎么办 解决教程_西西软件资和Win8.1无法安装应用并显示0x80070005错误_百度经验均未能解决问题,打算再去问问老师,或者有必要的话,我抽个时间重装一下虚拟机。
实验-3
实验要求
参考http://www.cnblogs.com/maybe2030/p/4715035.html 在Searching中补充查找算法并测试
提交运行结果截图
实验步骤
- 七大查找方法中顺序查找和二分查找已经完成了,现要对剩下的五种查找方法进行实现并测试
测试结果
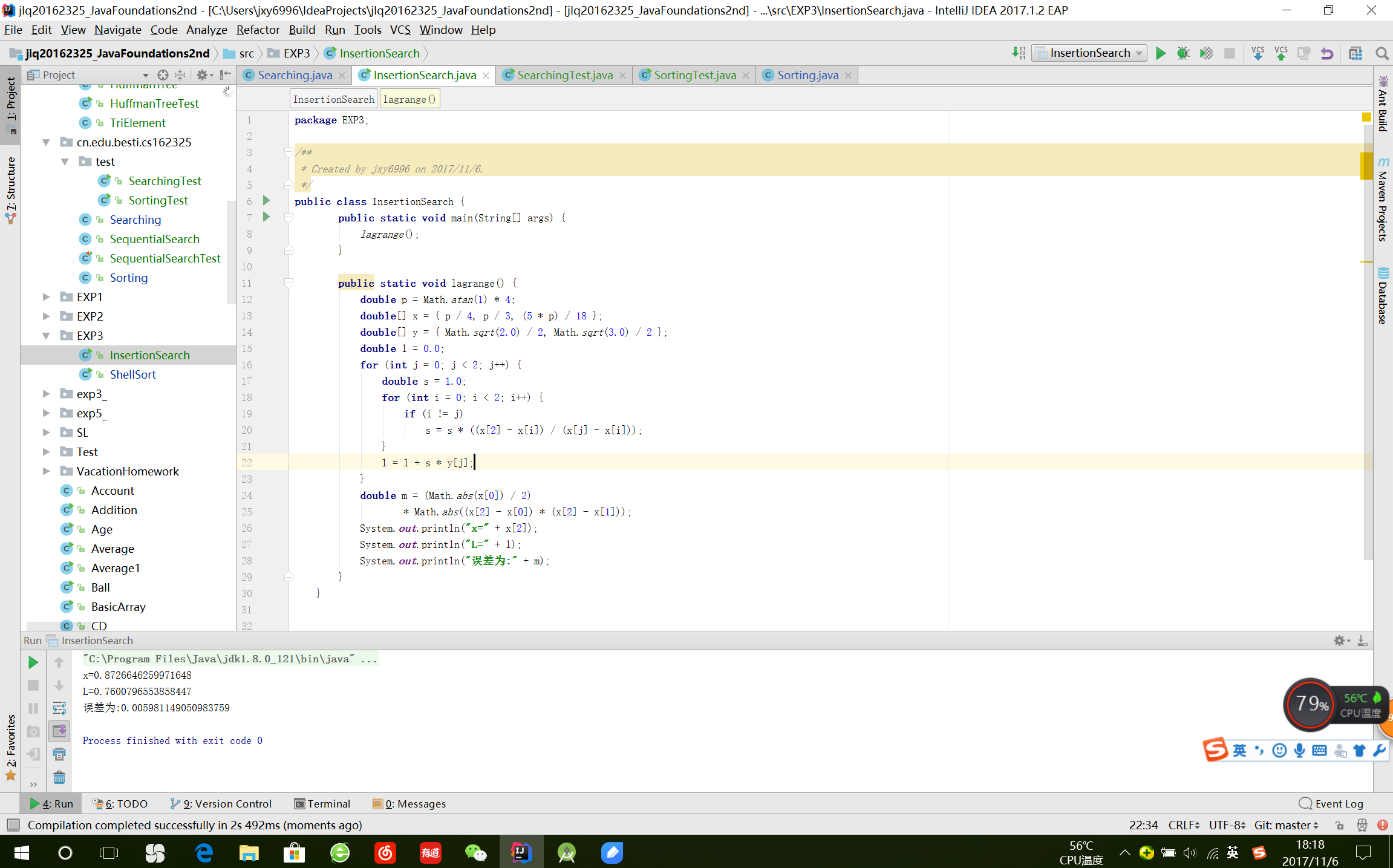
插值查找
- 用三点 lagrange 插值算法实现,用余项公式求误差;
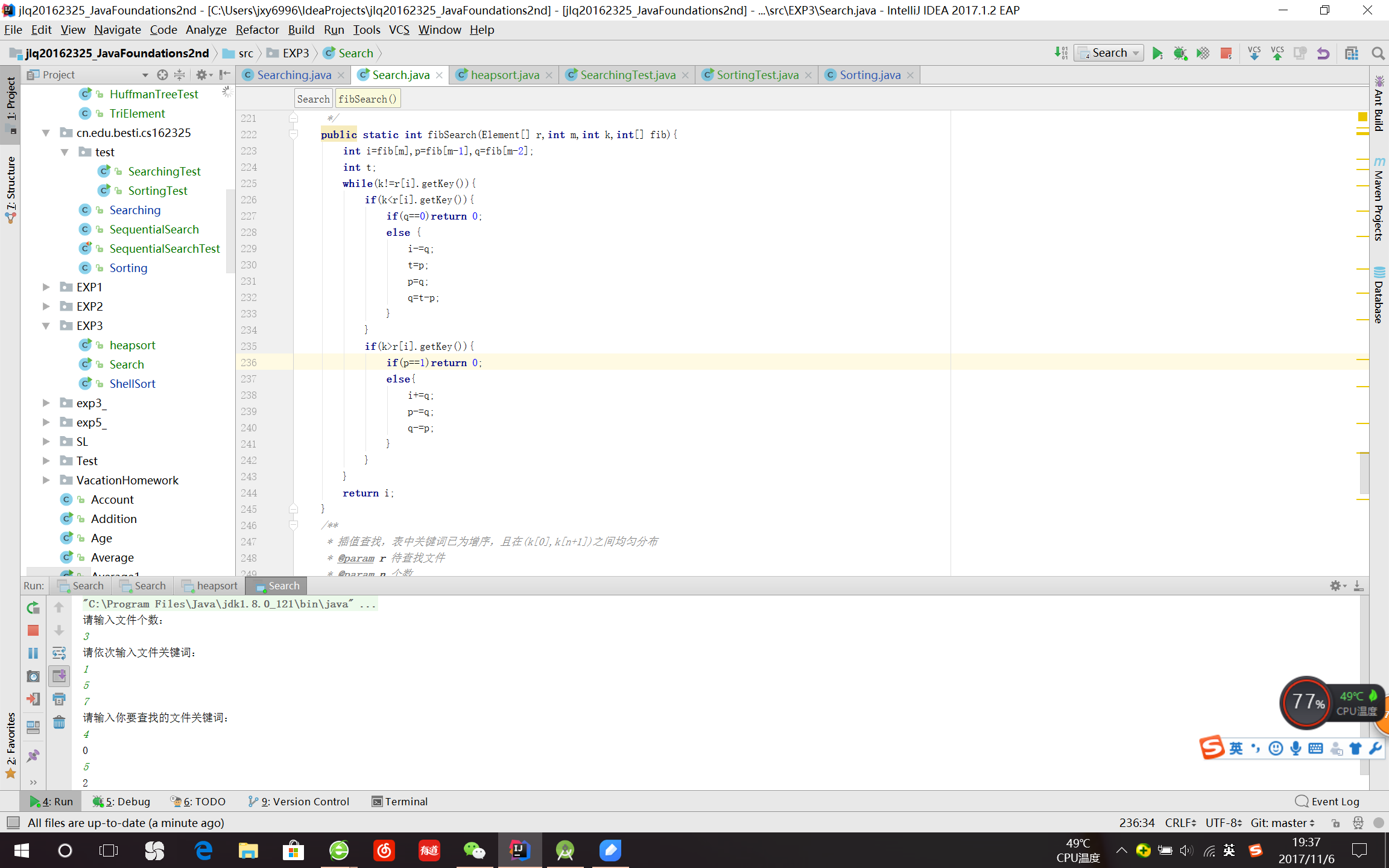
斐波那契查找
- 斐波那契查找,算法假定n+1是一个斐波那契数,即n+1=f[m+1]
T(k)表示k阶斐波那契树,若k=0或1则此树就是0;若k>=2;则树T(k)根为f[k]
左子树为T[k-1],右子树为阶数为k-2且所有结点之编号都增加f[k]的斐波那契树
树表查找
- 由于二叉搜索树定义上的特殊性,只需根据输入的 key 值从根开始进行比较,若小于根的 key 值,则与根的左子树比较,大于根的key值与根的右子树比较,以此类推,找到则返回相应节点,否则返回 null。
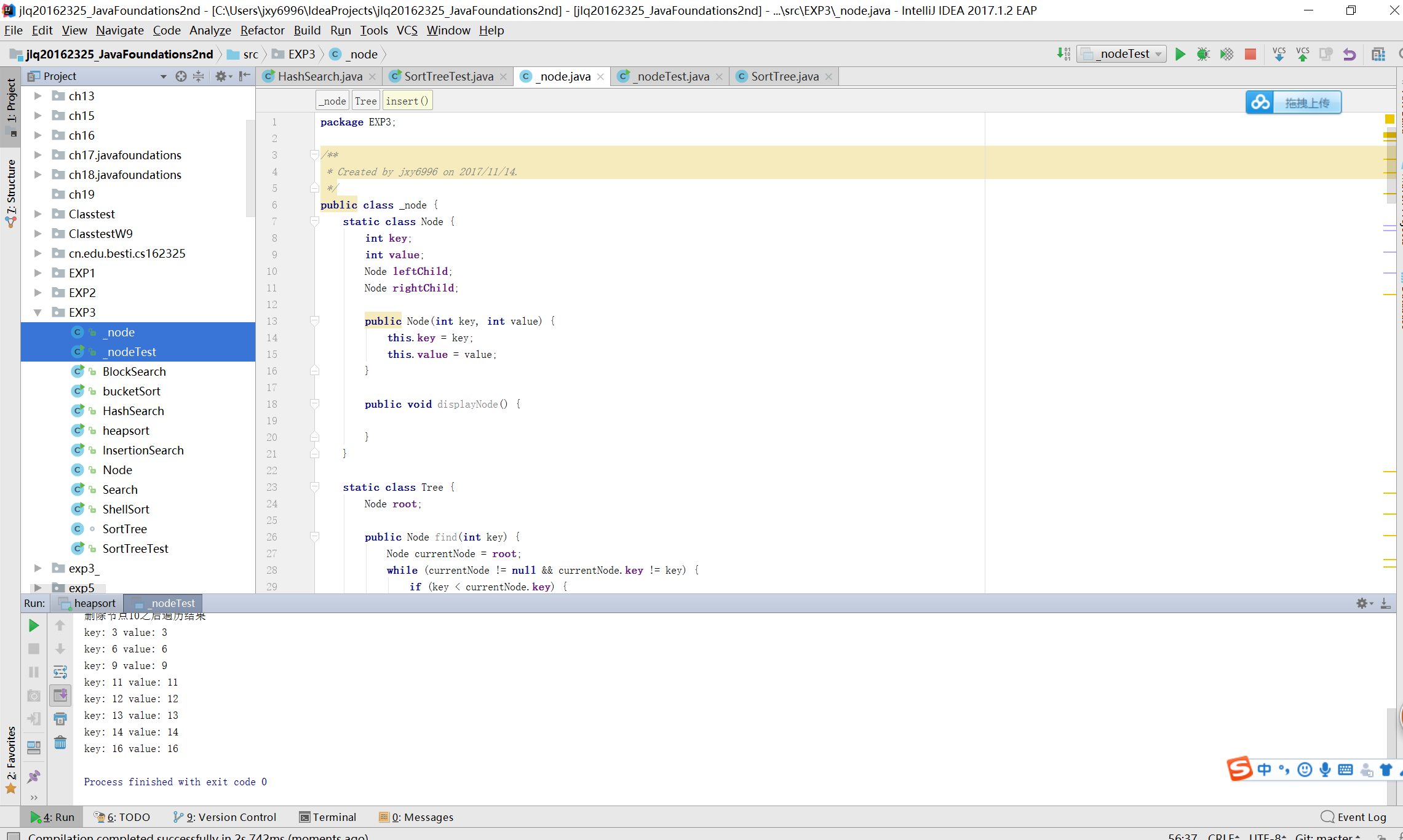
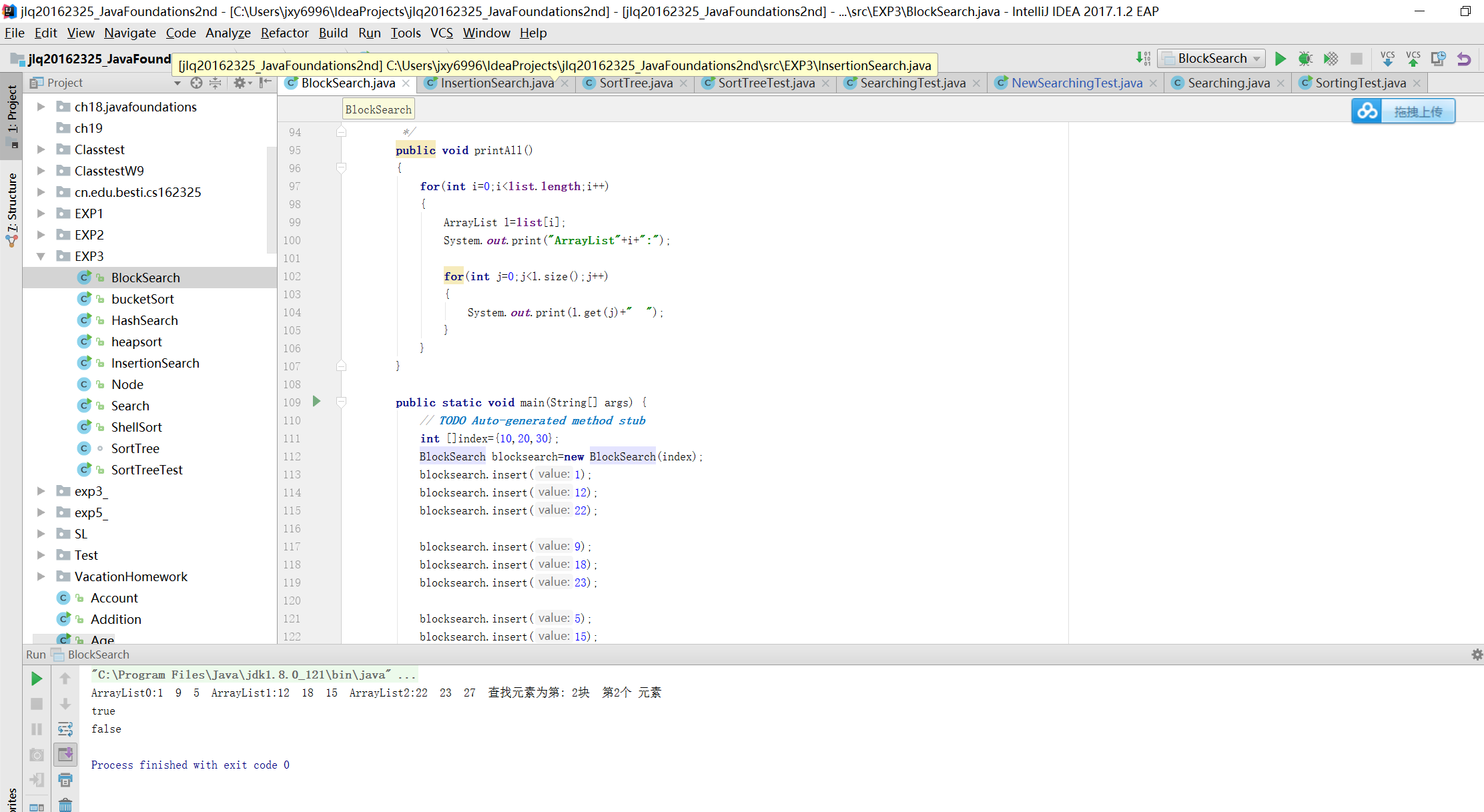
分块查找
- 分块查找要求把一个数据分为若干块,每一块里面的元素可以是无序的,但是块与块之间的元素需要是有序的。(对于一个非递减的数列来说,第i块中的每个元素一定比第i-1块中的任意元素大)
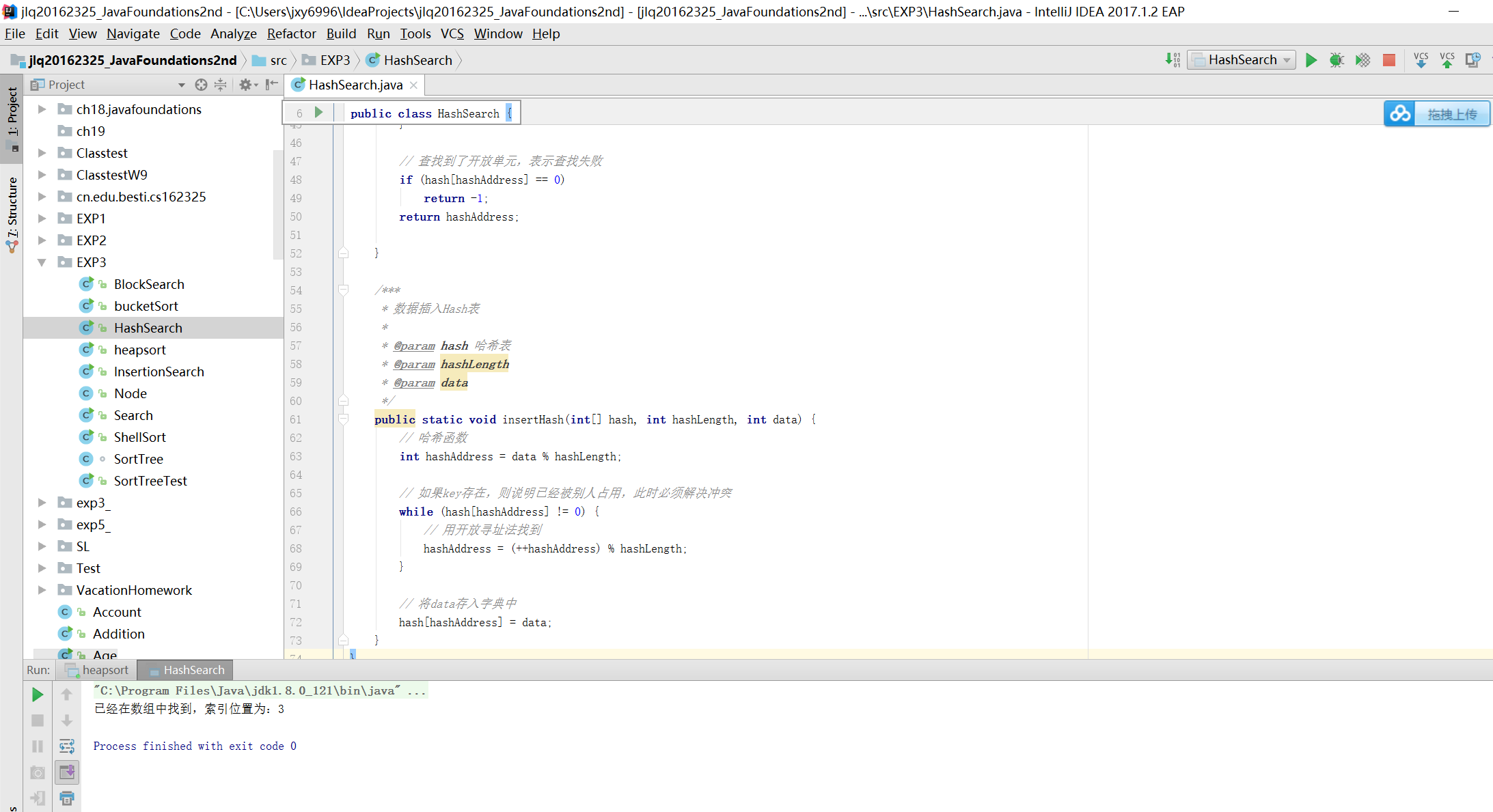
哈希查找
-
哈希查找是通过计算数据元素的存储地址进行查找的一种方法。O(1)的查找,即所谓的秒杀。哈希查找的本质是先将数据映射成它的哈希值。哈希查找的核心是构造一个哈希函数,它将原来直观、整洁的数据映射为看上去似乎是随机的一些整数。
-
哈希查找的操作步骤:
用给定的哈希函数构造哈希表;
根据选择的冲突处理方法解决地址冲突;
在哈希表的基础上执行哈希查找。
实验-4
实验要求
补充实现课上讲过的排序方法:希尔排序,堆排序,桶排序,二叉树排序等
测试实现的算法(正常,异常,边界)
提交运行结果截图
推送相关代码到码云上
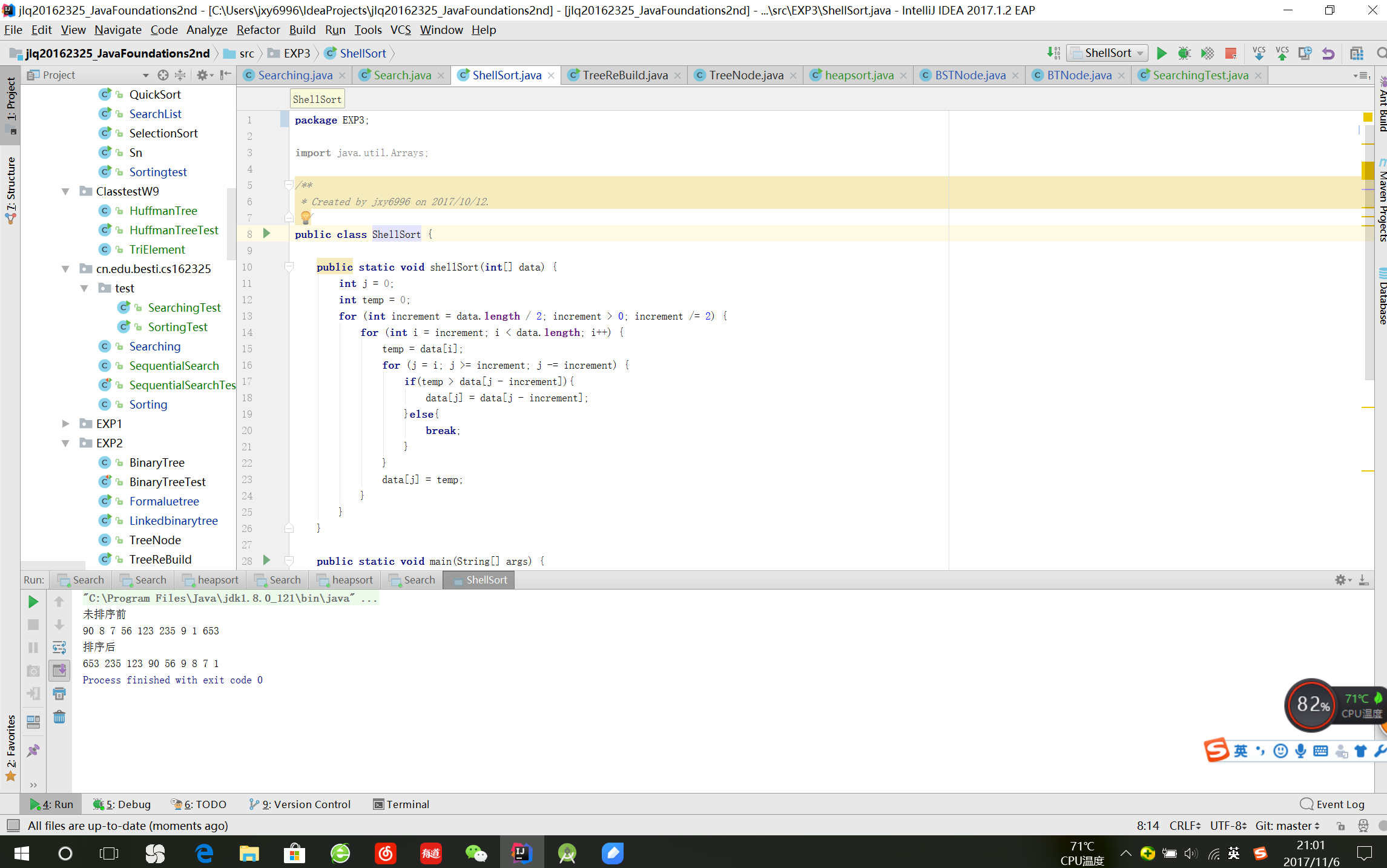
希尔排序
- Shell排序算法的核心思想 —— 分组插入排序。改变步长,用每种步长把数据划分成相应的分组;然后对每个组内的数据进行排序。
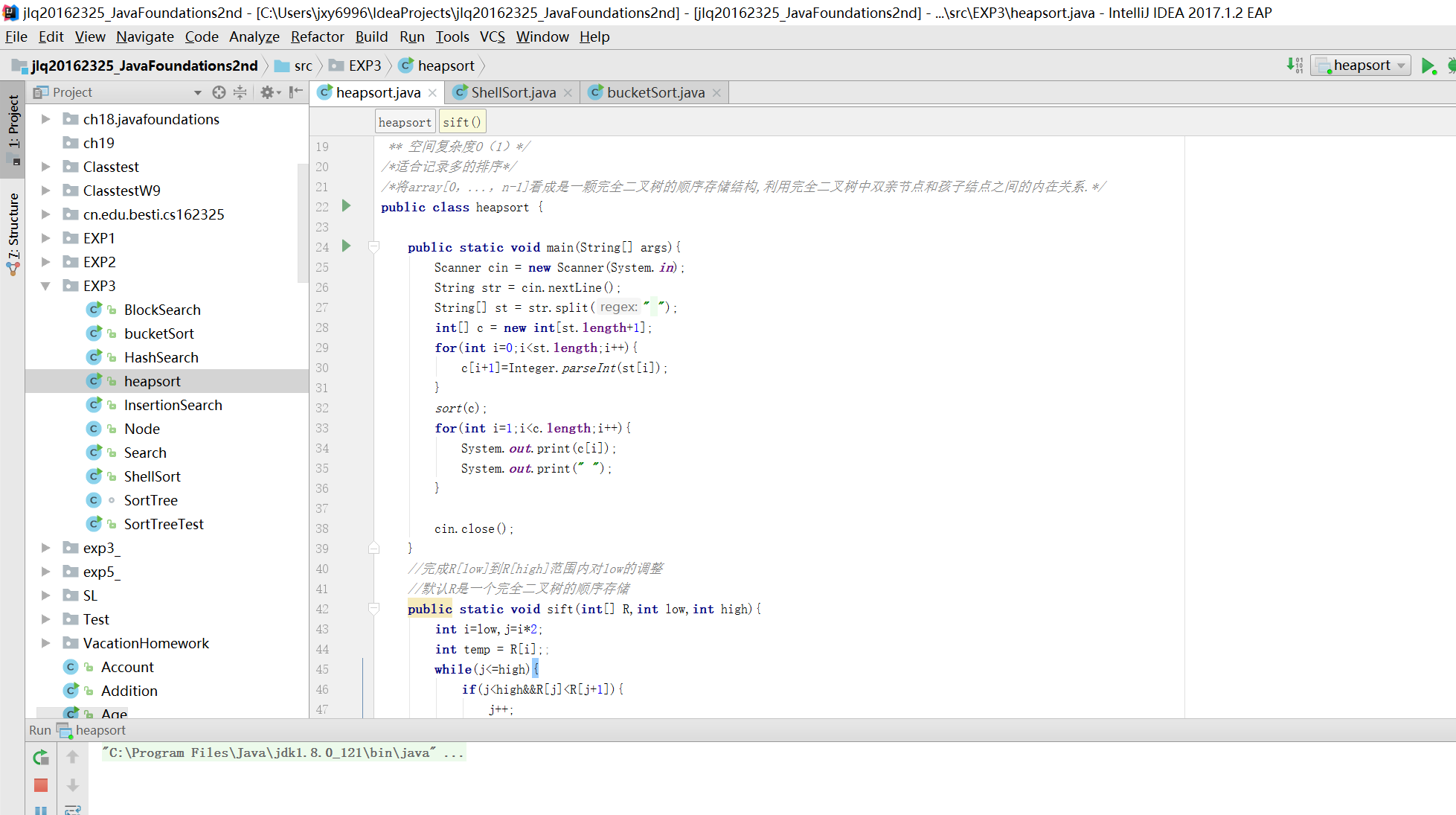
堆排序
- 思想:堆的根节点值最大(最小),将无序序列调整成一个堆,就能找出这个序列的最大值(最小值),将找出的值交换到序列的最后或最前,
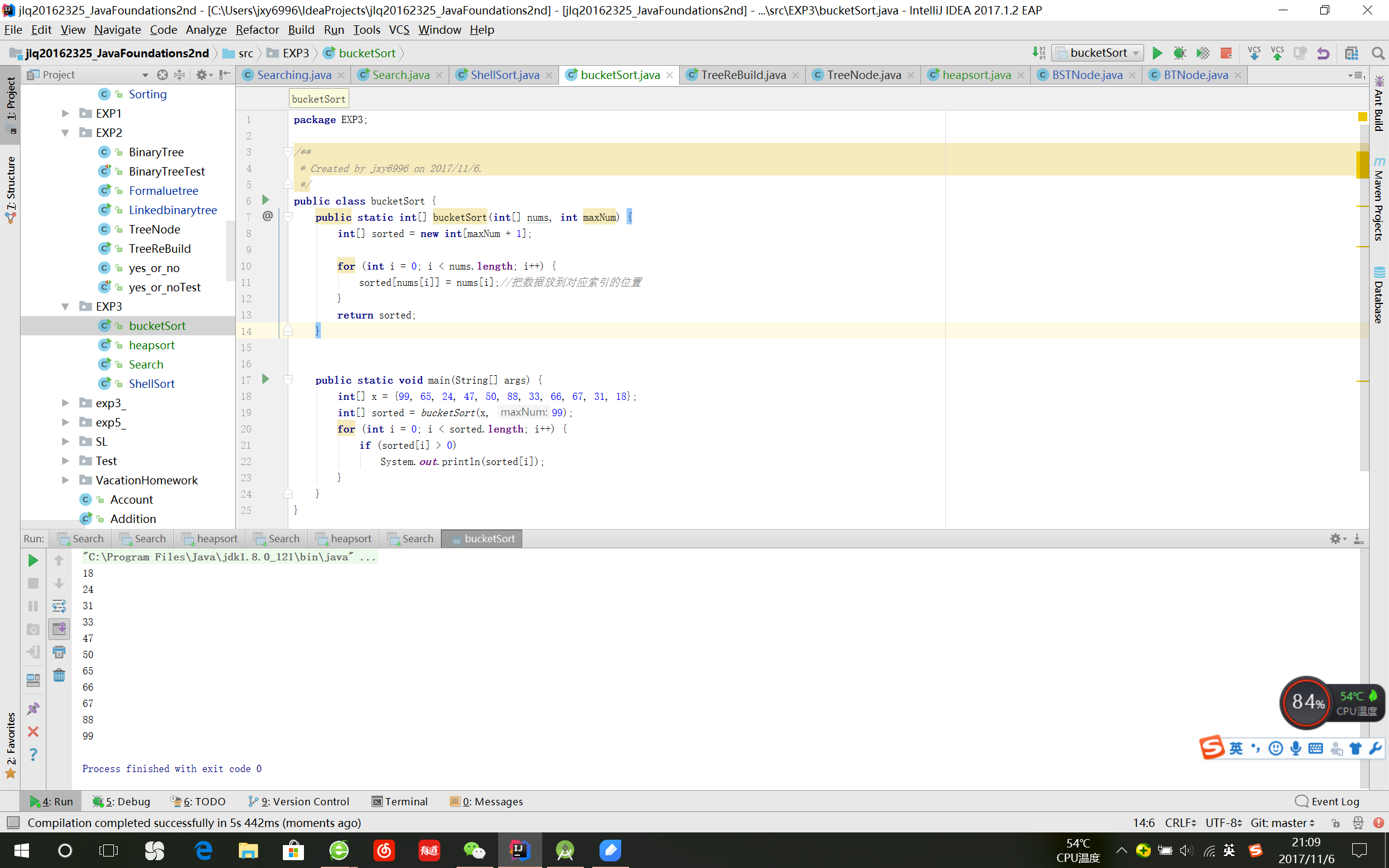
桶排序
- 桶排序是在已知数据的范围的条件下,创建若干个桶,根据相应的比较规则将待排数据落入各个对应的桶中,最后扫描桶来实现排序。
这个概念是从http://www.cnblogs.com/hapjin/p/5534262.html摘取的。
桶排序更接近于一种标记,当某个数出现了,就在对应的桶中mark一下。
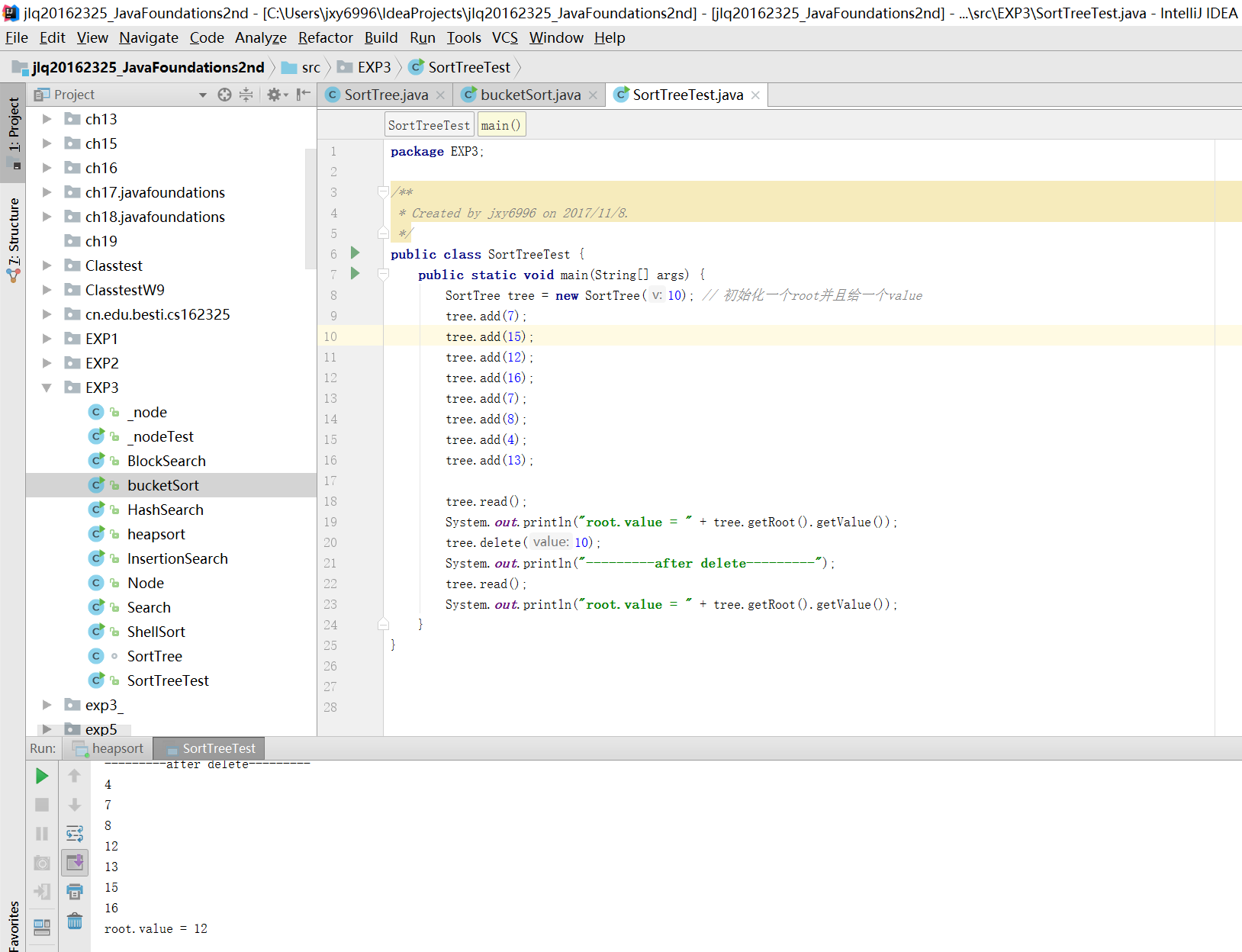
二叉树排序
- 基本操作:
(1)二叉排序树的查找;(2)二叉排序树的插入;(3)二叉树的中序遍历;(4)初始化栈;(5)出栈和入栈。(6)动态内存管理。
实验总结
- 这次实验是在原来测试的基础上,结合后面学到的知识加以拓展应用。在边做边查资料的过程中,补充了不少知识。