一、简介
Dundas公司于1992年成立于加拿大多伦多,原本是一家专注于数据可视化技术的公司,主要业务为向其他公司提供数据可视化组件外包开发服务。在1994年至2009年十多年的时间里,Dundas相继推出了Dundas Chart、Dundas Gauge、Dundas Map和Dundas Calendar这4款优秀的数据可视化产品。在享受了多年Dundas公司提供的数据可视化服务之后,微软终于在2007年把这4款产品都收购了,并把它们的技术和代码运用到自己的产品中,包括ASP.NET、Window Form、SharePoint和SQL Server Reporting Services等。能得到微软的青睐,足以说明Dundas公司在数据可视化领域的地位。
到2009年,Dundas公司又推出了Dundas dashboard,这是一款基于Web的图形仪表板设计工具,已经具备了BI产品的雏形。到了2015年,Dundas公司总算摆脱了数据可视化外包公司的尴尬地位,推出了Dundas BI,正式进入到了BI领域。

因为Dundas公司是做数据可视化出身的,所以Dundas BI的强项依旧是可视化部分,而在cube构建和数据分析方面,Dundas BI不得不依赖于第三方数仓。这种局面一直持续到2019年, Dundas推出了自己的In-Memory Engine,支持构建内存数仓,Dundas BI才算补足了自己最后一块短板,从此插上了牛逼的翅膀开始腾飞。在2020年Gartner发布的年度BI及分析平台魔力象限报告中,Dundas BI第一次进入到了魔力象限,其pixel-perfect的能力亦备受赞赏,说明Dundas BI优异的数据可视化能力为自己加分不少。

二、产品架构
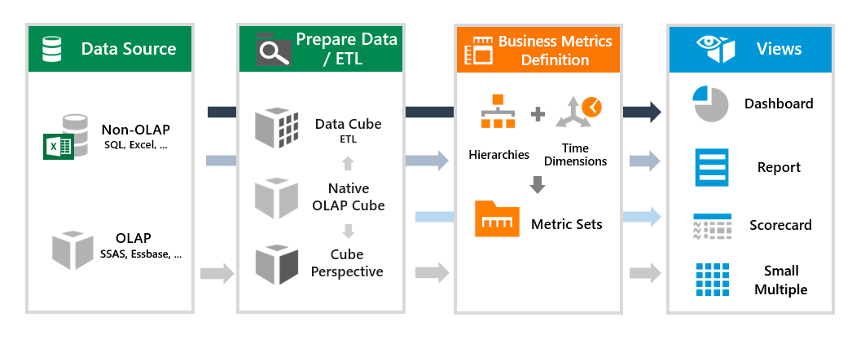
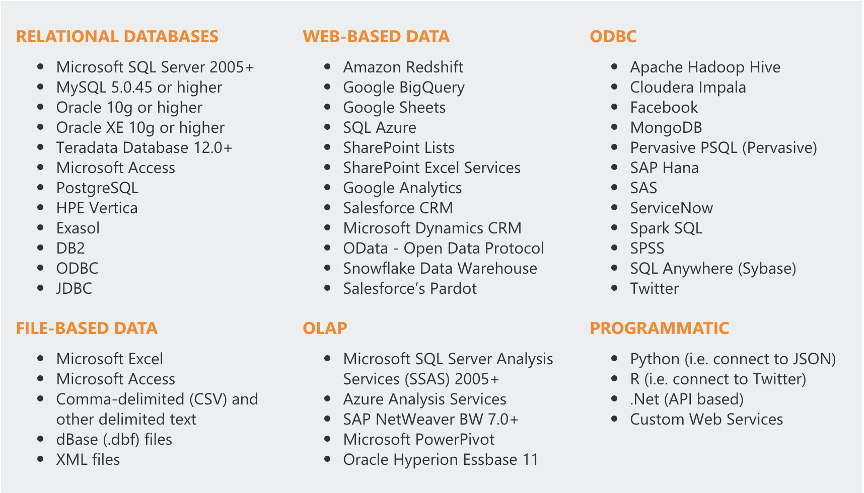
Dundas BI的架构分为4层,最底下是数据源,数据源可以是RDBMS、OLAP、 平面文件、大数据存储、API数据源以及程式化数据源,一共支持50多种。值得一提的是,这50多种数据源还包括了谷歌云、亚马逊云的多种云上数据库产品,这也反映了Dundas BI的数据源适配及生态融合能力还是很强大的。
在数据源之上,是数据预聚合层或者叫数据集层。数据预聚合层从数据源中加载好数据,利用各种数据清洗工具完成数据的清洗和转换工作,并根据预定义好的数据集模型完成数据的预计算,并将预计算的结果数据保存在数仓或者内存中。在查询的时候,查询请求就不需要下发到数据源,而是直接从预聚合层中获取结果数据,加快数据查询的速度。在推出In-Memory Engine之前,这一层的工作只能交由第三方数仓去完成,这就使得Dundas BI不是一个完整的BI产品,没有办法独立完成OLAP操作,在推出了In-Memory Engine后,这一层的工作就可以交给In-Memory Engine完成。同时,Dundas依旧保留了与第三方数仓的对接能力,同时支持In-Memory Engine中内存数据集导出至数仓以及从数仓加载数据集回内存,这大大增加了Dundas BI数据集选择的灵活性,成为了Dundas BI的又一大特色。
再往上便是指标定义层。Dundas BI在指标定义层中完成对度量和维度的排序、分组、过滤等设置,并定义了数据的显示格式和缺失补全规则。指标定义层输出的产物是一个个指标集,指标集可以由用户根据自己的业务需求定义,也可以由Dundas BI根据数据集自动生成。
最上面的是视图层,视图层就是各种可视化服务组件,包括仪表板、报表、记分卡、看板等等。视图层的可视化组件可以轻松地被嵌入到其他业务系统,也可以导出和分享,并且支持评论、推送等服务,用户大部分的数据消费都是在视图层中完成的。这一层是Dundas BI做的最出色的部分,也是Dundas BI的主要卖点,其收入的70%都是来自于为其他公司提供报表嵌入支持服务。
三、产品特性
1.敏捷性和专业性相结合
1)适配多样化数据源
Dundas BI可以适配50多种数据源,既包括RDBMS、OLAP等结构化数据,也包括平面文件、大数据存储、API数据源以及程式化数据源等非结构化数据。
2)支持拖拽式分析,支持MDX查询,支持图表脚本
在Dundas BI中,可以不写一行查询语句,仅以拖拽和点击的方式,就可以完成一份报表制作。对于专业数据分析人士,Dundas BI则支持MDX查询语句,可以实现复杂的OLAP查询操作。Dundas BI还提供了自己的脚本语言DundasScript,可以利用DundasScript为图表编写脚本,完成复杂的数据分析工作。
3)强大的可视化能力
Dundas拥有25年的数据可视化技术积淀,在Dundas BI上提供了记分卡、表格、图表、计量器、地图、树图、微线图、指标卡、关系图等上百种可视化组件,充分满足用户的可视化需求。除了组件类型丰富,Dundas BI还可以根据数据集和指标集自动推荐合适的可视化图表,实现数据表达的智能化。对于具备自主设计报表能力的高阶用户,Dundas BI也提供了良好的支持,在Dundas BI中,用户可以使用HTML5和CSS设计自己的报表,可定制化程度非常高,这也是Dundas BI能宣称pixel-perfect的底气所在。

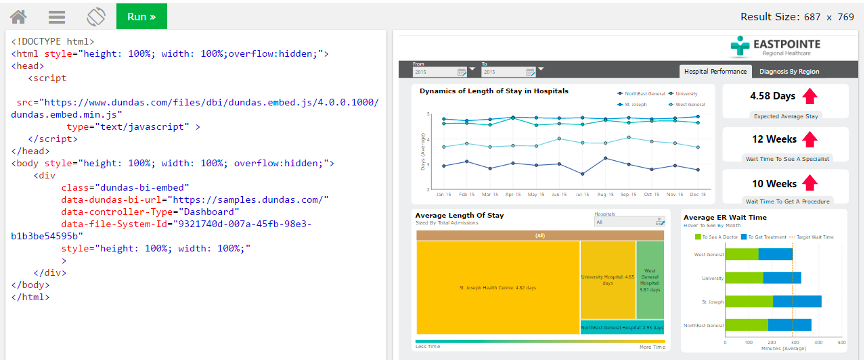
2.适应线上线下
1)多终端支持
Dundas除了提供桌面软件外,还可以通过web浏览器以online的方式使用,为了适应智能手机的发展,Dundas还提供了专门的手机app。因为Dundas的图表都是基于HTML5制作的,并且提供了良好的自适应能力,所以即使不安装app,也可以在手机浏览器上实现报表的创建、浏览和分享,甚至可以完成一些简单的数据分析操作,可谓十分方便。
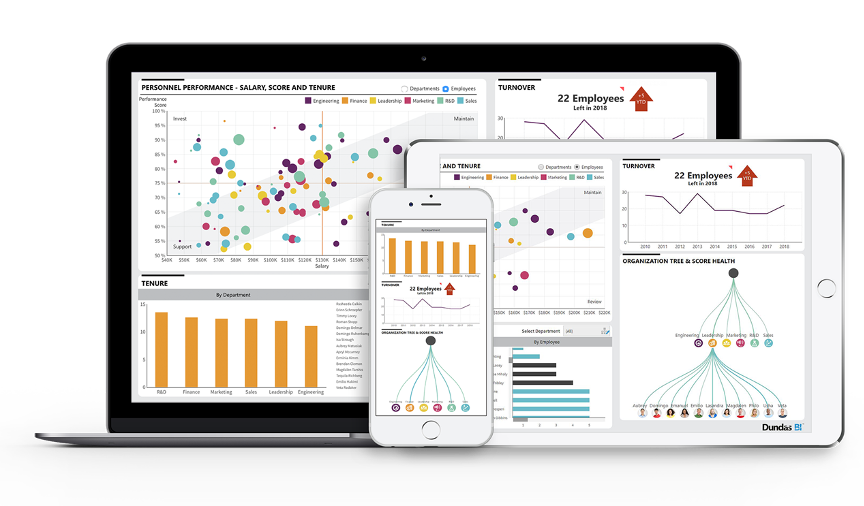
2)可以在报表数据上直接编辑数据,实现所见即所得
Dundas BI的图表是动态的,除了能够完成上卷/下钻、联动、跳转操作外,在有数据写入权限时,还能够在报表上填报和修改数据,所见即所得,非常直观。
3)报表提供在线评论功能,实现数据交流
有时候数据往往只能展示事实,但却无法讲出完整的故事,而且通过数据传递信息的方式是单向的,信息只能由数据提供者传递给数据查看者,中间缺乏互动。为了解决这个问题,Dundas BI为图表提供了评论功能,用户可以对可视化出来的数据进行评论,如提出问题或作出解释,其他人还可以对这些提问或解释进行回复,以此来实现数据展示过程中的交流互动,增强数据交流的效果。
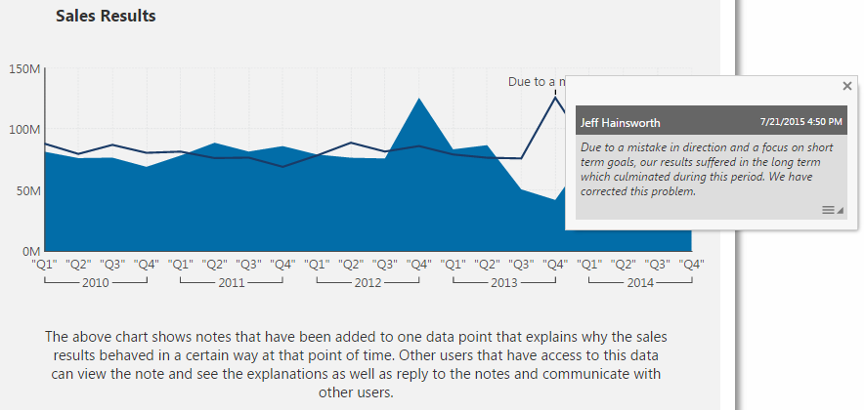
4)支持报表导出和幻灯片生成,可发布到IM工具和FTP
虽然Dundas BI的线上报表可以被方便地访问,但是在许多特定的场景下,用户还是希望报表能够离线保存。为此,Dundas BI支持将报表导出成PDF和图片,导出的离线数据还可以直接发送到IM工具和FTP上。Dundas BI还有一大特色便是它的报表可以直接生成幻灯片,幻灯片可以投到各种显示设备上,并且能够根据设备屏幕的大小自动调整报表尺寸,极大地满足了演讲场合的需求。
3.灵活的cube支持
前面已经说过,Dundas BI最初只能借助第三方数仓完成cube构建,后来Dundas又开发了自己的In-Memory Engine用以支持内存cube构建。此外,Dundas BI还支持direct模式,数据不落地,直接将查询请求发送到源数据库,由源数据库完成聚合并加载到内存中完成可视化。由此Dundas BI便支持了3种cube接入方式。为了进一步增加cube接入的灵活性,Dundas BI还支持定义cube视图,以及将现有cube和其他源数据表进行关联的功能,以此提供对第三方数仓中cube的修改能力。
4.便捷的系统管理和灵活的部署方式
1)对接Windows账号体系,同时支持其他SSO系统
Dundas BI深度融合微软生态体系,可以无缝对接微软系的各种平台和系统,包括Windows账号体系。为了更加方便地被集成进其它现有系统从而提供报表嵌入服务,Dundas BI很早就支持对接其它SSO系统,以满足不同客户的接入需要。
2)支持SaaS化部署和多租户模式
区别于其它以单机软件形式提供服务的传统BI软件,Dundas BI可以作为SaaS产品部署在云上,既支持亚马逊云、微软云和谷歌云等公共云,也可以部署在私有云中。Dundas BI还天然支持多租户模式,更加适应云上生产环境。
3)支持独立部署
除了作为SaaS产品部署在云上,Dundas BI仍然保留了独立部署的输出方式,以满足业务未上云客户的需要。用户可以下载单机软件并购买一定规格的license,激活后便可以使用对应的软件服务。
5.强大的开放集成能力
Dundas公司作为一家提供数据可视化外包服务起家的公司,从一开始就非常注重产品的开放集成能力,在与微软的长期合作中,其自然而然就融合到了微软的BI生态体系内,支持所有的微软BI相关产品,包括SQL Server、Microsoft Analysis Services、Microsoft IIS等等。Dundas BI还支持便捷分享,报表可以轻松地嵌入到第三方系统中。Dundas BI还提供了丰富的开放API,涵盖权限管理、报表管理、数据管理、数据分发、文件系统、分析脚本管理等功能,利用这套开放API, Dundas BI可以更加无缝地嵌入到客户的业务系统中。
四、In-Memory Engine
In-Memory Engine是Dundas公司在2019年推出的内存cube技术,并申请了专利。
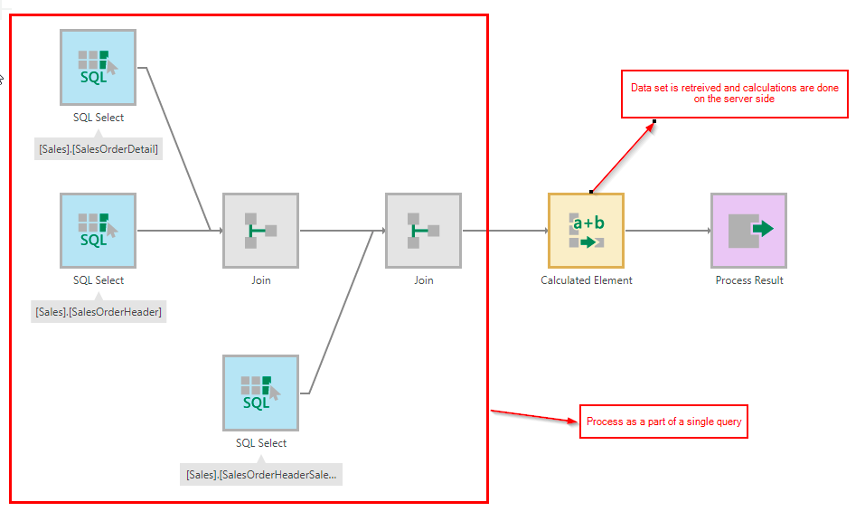
In-Memory Engine会先根据构建好的cube,利用Dundas提供的工具把数据源中的数据清洗好,并按照不同维度组合完成预聚合,将结果存放到内存中,加快数据的访问速度。同时支持将内存中的计算结果持久化到数仓中,以便在下次使用时直接加载到内存。
In-Memory Engine采用一种数学上的超图结构来组织内存中的数据,这种超图结构使得Dundas不需要在内存中存储维度所有粒度的聚合结果,即可完成对不同粒度聚合结果的查询,减小内存使用量。
五、DundasScript
DundasScript是Dundas自己开发的一套脚本语言,可以认为是C#的一个子集,在语法上和C#非常类似,且支持C#中的许多标准工具类。

虽然DundasScript在语法上表现为一个C#的子集,且支持C#中的标准工具类,但DundasScript是一个支持动态类型的脚本语言,在DundasScript中可以不声明变量的类型,也可以在一个作用域内多次定义相同命名的变量,这些特性使得DundasScript更像是python、JavaScript等脚本语言。
// Create a new string:
string foo = new string("Hello world");
if (someCondition)
{
// From now on, foo is an int, not a string!
int foo = 10;
}在Dundas中可以利用DundasScript完成数据清洗以及包括计算字段定义、桥梁参数定义、第三方数仓接入、占位符定义、自定义计算公式等其他数据操作。下面是一个利用DundasScript完成自定义字段的例子:
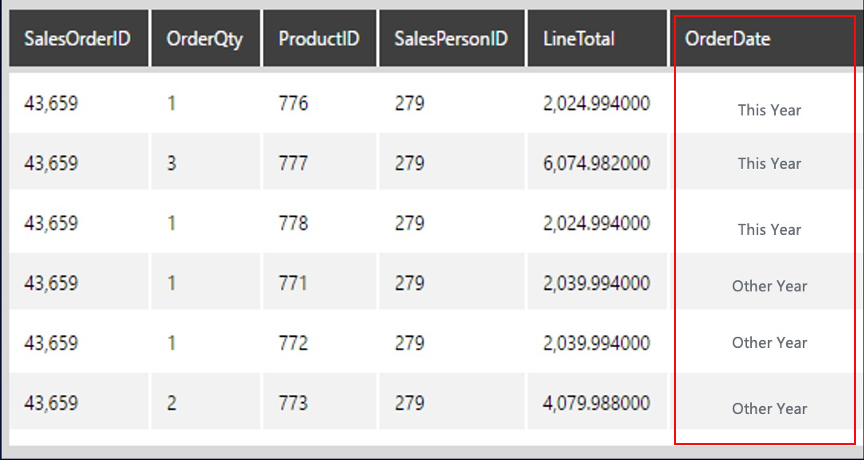
DateTime date1 = $OrderDate$;
int i = date1.Year;
string s = "";
if (i == 2020)
{
s = "This Year";
}
else
{
s = "Other Year";
}
return s;在这个例子中,首先对cube中的OrderDate字段进行了引用,把它引用到date1这个DateTime类型的变量中,然后取date1的年部分,并对他的值做判断,如果为2020年,则返回“This Year”,否则返回“Other Year”。
六、总结
Dundas公司在数据可视化领域所积累的技术沉淀,使得其产品在可视化方面的能力几乎是其他BI产品无法超越的,这也成为了Dundas BI的核心卖点。Dundas公司也非常善于抓住这一卖点,瞄准细分市场,主打报表嵌入服务,并为客户提供一对一的嵌入开发服务,这种服务为其带来了70%的年收入。
但Dundas公司也明白数据可视化只是BI产品的一部分,如果一直抱着数据可视化技术吃老本,那么就永远都无法摆脱数据可视化外包公司的地位。为此,Dundas在cube建设上投入了大量精力,构建了自己的In-Memory Engine,从此弥补了自己一直以来的短板,让Dundas BI成为了一个完整的BI产品。同时还保留了第三方数仓的接入能力,这便给Dundas BI的cube选择提供了灵活性,反而成为了它的一大特色。
另外,Dundas BI作为微软技术栈中的产品,虽然可以对接亚马逊云、谷歌云等云厂商的数据源,但是产品本身一直以来都只能部署在windows系统上,这阻碍了它进一步向市场推广。不过这种局面随着Dundas BI最新版本可以部署在linux系统上而得到改善,这一点在Gartner的报告中也有提到。
参考链接:
产品官网:
用户文档:https://www.dundas.com/support/learning/documentation/
开发者文档:https://www.dundas.com/support/developer/
学习资源:https://www.dundas.com/resources
演示视频:
Data Cleansing with Data Cubes
Creating Custom Categorical Hierarchies
Creating and Using Filters on a Dashboard