本文的重点是把openJDK中多种主流垃圾回收器拉到一起,并对他们的特征、关注点、优劣势做对比分析,以期能在生产时间中根据业务场景选择合适的垃圾回收器。由于本文并非介绍各种垃圾回收器的内部实现细节,所以对垃圾回收器的工作过程只做整体描述。
openJDK中主流的垃圾回收器
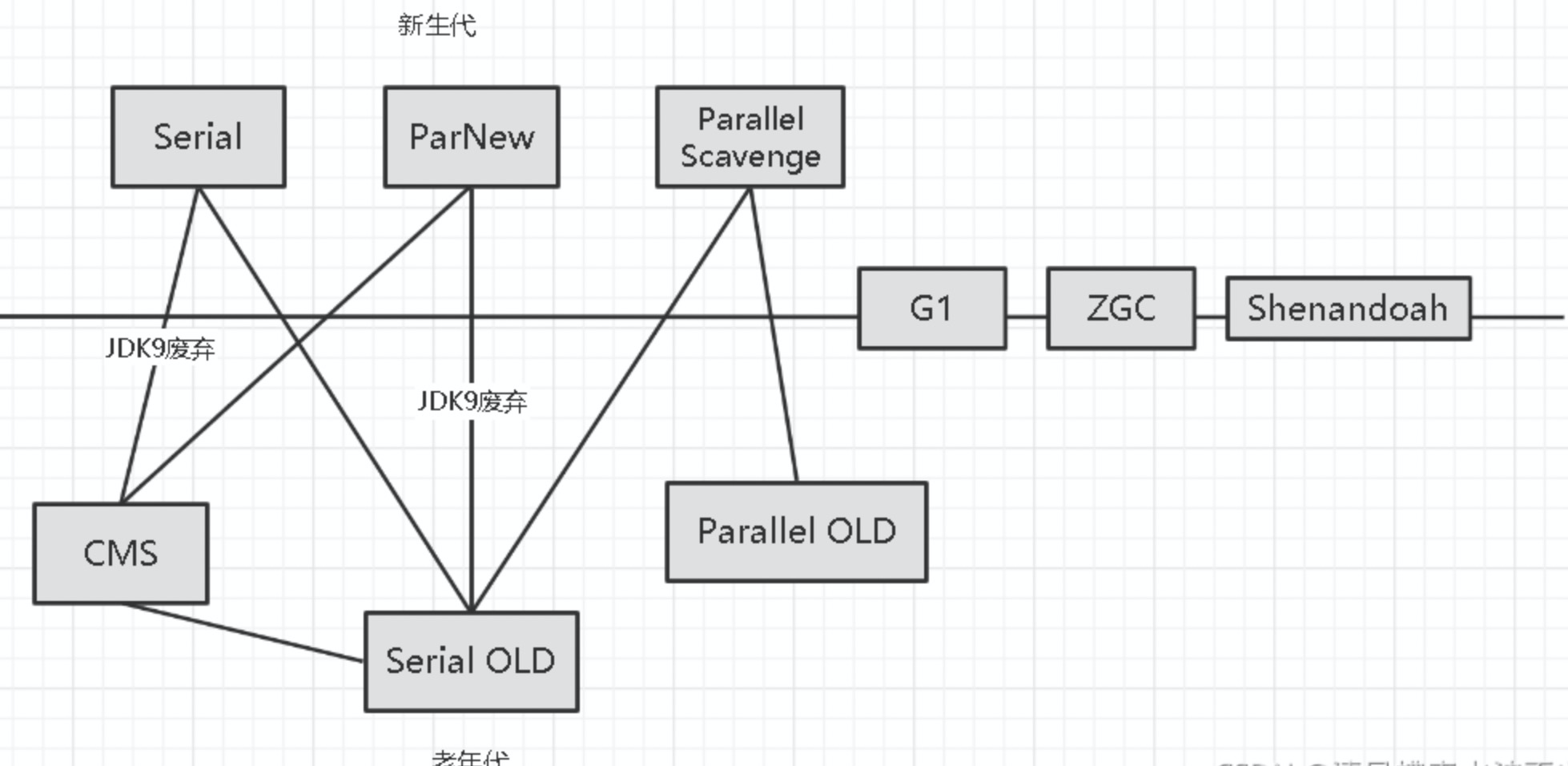
截止到JDK12,openJDK支持的主流垃圾回收期如上图所示。其他比较小众的垃圾回收期虽然也很重要(如Epsilon),但由于用得比较少,所以没有画出来,在此略过。
Serial和Serial Old收集器
看名字就知道,这是单线程垃圾回收器。Serial负责新生代,Serial Old负责老年代。他们的工作过程很简单:垃圾达到一定内存上限,就把用户线程停下来(当然要在用户线程的安全区域内),用一个GC线程去回收垃圾。

ParNew和ParallelOld收集器
也是看名字就知道,这是多线程并发的垃圾回收器。他们和erial和Serial Old收集器的工作除了可以用多个线程做GC外,几乎没什么差别。
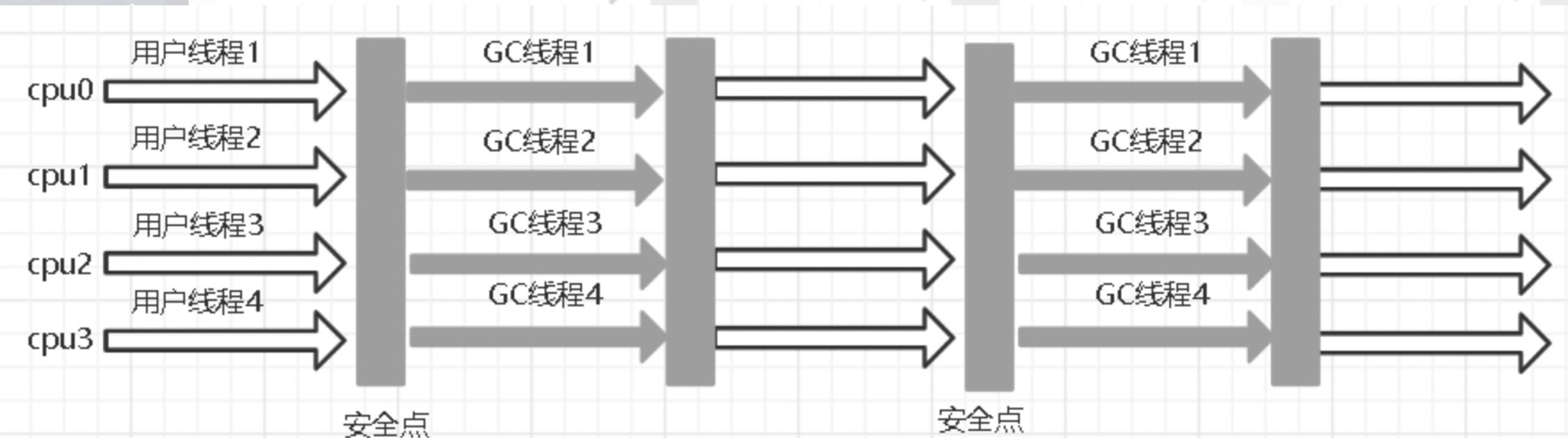
Parallel Scavenge收集器
这是新生代的收集器,相比其他新生代收集器,他的关注点是“最大吞吐量”(GC时间/程序运行时间总),也就是说,它不是很关注一次性把用户线程停顿多久,但是一段时间内花在GC上的时时间占总时长的百分比要控制在一个阈值内。
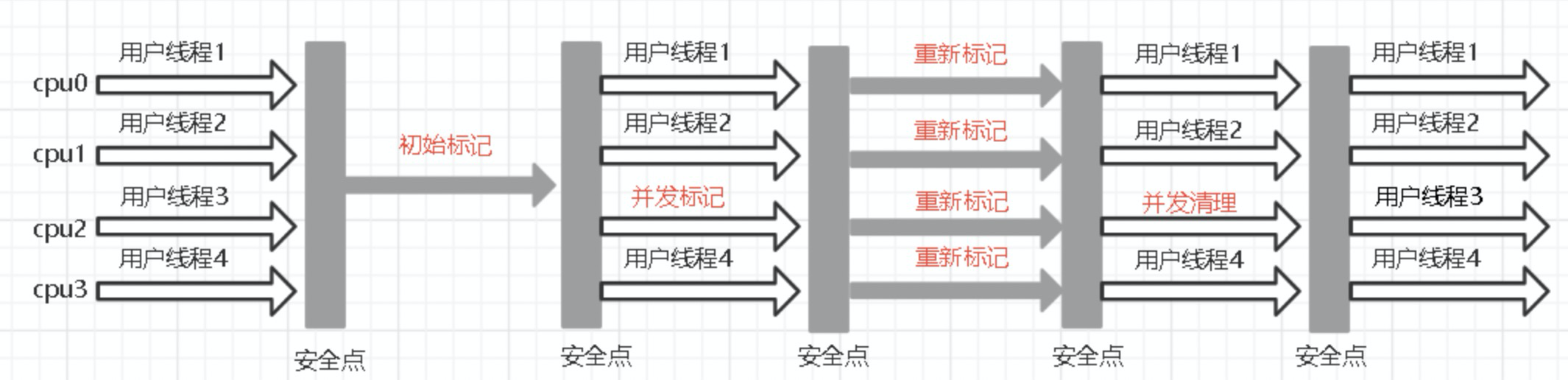
CMS收集器
全称是 ConCurrent Mark Sweep,看名字就只知道它采用标记-清理算法做GC。用于老年代对象GC,实际上,只有CMS的GC会只发生在老年代(Major GC),其他的老年代GC发生时,都是Full GC,整个堆一起回收的。
这是openJDK中第一款可以做到与用户线程并发的垃圾回收器,它关注的是用户线程停顿时间。用户线程停顿时间越短,反映在程序外部,程序的响应速度越高、延时越低。
它的过程大致如下:
- 初始标记。根据OopMap找到程序中的GC Root,这个过程的时长和堆大小无关,只和程序本身有关,所以比较快。这个过程需要停顿用户线程。
- 并发标记。从GC Root触发,根据引用关系可达性,搜索整个对象引用图。这个过程是和用户线程同时进行的。
- 重新标记。采用增量更新(采用写屏障的方式记录新产生了那些引用)的方式,重新标记在并发标记阶段新产生的引用关系。这个过程也是需要停顿用户线程的。
- 并发清楚。采用清除的方式,把不可达的对象原地清除掉,这时候会留下一段段不连续的内存碎片。因为原地清除不可达对象,没有移动存活对象(内存地址不会变,引用不需要更新),同时不可达的对象肯定不会再次被用户线程引用了,所以这个过程可以放心的和用户线程同时进行。
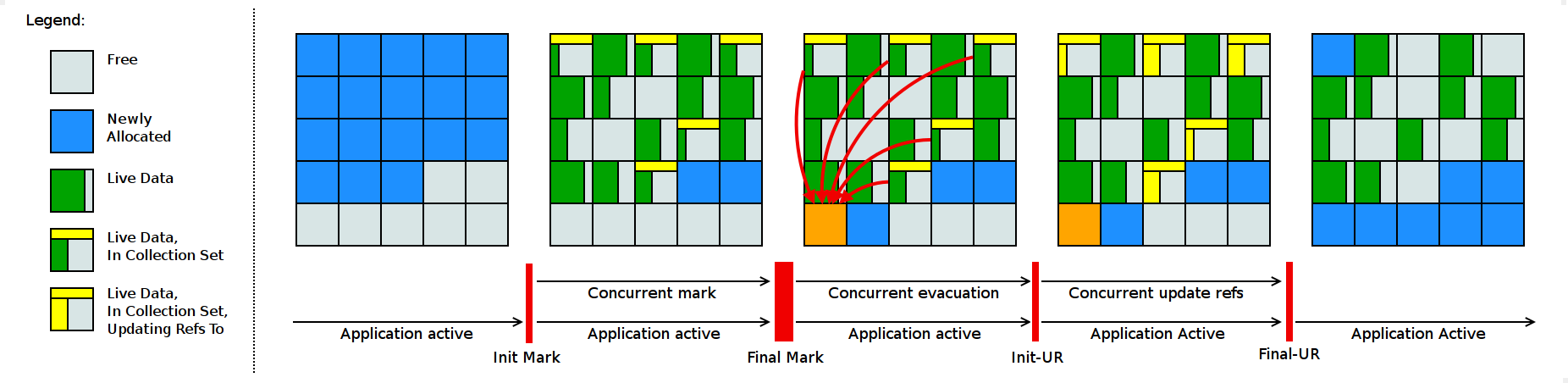
G1 收集器
G1收集器简单地把堆分成新生代和老年代两个部分,而是先对分成一个个Region,再给这些Region分配不同的角色,比如哪些Region作为Eden区,哪些是survivor区。
G1最大的特定是可以承诺最大停顿时间(一定范围内,即使到一百多毫秒),当最大停顿时间要求较短时,G1就会把要收集的目标Region范围(collection set,简称CSet))减小,一次少收集写Region,停顿时间允许大些,它就一次多收集写Region。
因为G1也是分代的,那么它也分为两种模式来确定CSet:
- Young GC:选定所有young gen里的region作为Cset。通过收集数据动态控制young gen的region个数来控制young GC的开销(下次少安排点新生代Region,YGC不就快点了吗?)。
- Mixed GC:选定所有young gen里的region,外加根据global concurrent marking统计得出收集收益高的若干old gen region作为Cset。在用户指定的开销目标范围内尽可能选择收益高的old gen region。
G1的工作过程分为以下几个阶段: - 初始标记。这个阶段和YoungGC一起做,设置两个TAMS(top-at-mark-start)变量(NTAMS和PTAMS)的值,所有在TAMS之上的对象在这个并发周期内会被识别为隐式存活对象,并且把survivor区内的对象一起纳入GC ROOT,将它们全部的字段压入扫描栈(marking stack)中等待后续扫描。这个阶段要暂停用户线程。
- 并发标记。不断从扫描栈(marking stack)取出引用递归扫描整个堆里的对象图。每扫描到一个对象就会对其标记,并将其字段压入扫描栈。重复扫描过程直到扫描栈清空。这个阶段用户线程并发。
- 最终标记。扫描原始快照(SATB,采用写屏障的方式记录取消了哪些引用)出发的引用图,标记对象。这个过程需要暂停用户线程。
- 清理阶段。采用并行copying(或者叫scavenging)算法把CSet里每个region里的活对象拷贝到新的region里,并且把旧Region回收。因为涉及对象拷贝和引用指针更新,这个过程需要暂停用户线程。这个阶段是和YGC一起完成的。在GC log里会留下[GC pause (mixed)] 。

从全局上看,G1正常是这样一个过程:young GC与mixed GC之间视情况切换,背后定期做做全局并发标记。Initial marking默认搭在young GC上执行;当全局并发标记正在工作时,G1不会选择做mixed GC,反之如果有mixed GC正在进行中G1也不会启动initial marking。
在正常工作流程中没有full GC的概念,old gen的收集全靠mixed GC来完成(Cset 由mixed gc来回收)。如果mixed GC实在无法跟上程序分配内存的速度,导致old gen填满无法继续进行mixed GC,就会切换到G1之外的serial old GC来收集整个GC heap,这个和CMS是类似的。
可以参考R大的文章:https://hllvm-group.iteye.com/group/topic/44381
Shenandoah收集器
Shenandoah收集器可以看成是G1的改进版,他们拥有相同的堆内存布局,在初始标记、并发标记等阶段的思路也基本一致,甚至还共享了许多代码。
- Shenandoah对G1最主要的改进是引入了转发指针(Brooks Point)和读屏障从而可以做到对象移动时不停顿用户线程,从而使得清理阶段最耗时的阶段可以与用户线程并发。
- 采用邻接矩阵做记忆集(remember Set),减少维护消耗。
- 同时,Shenandoah现阶段是不区分新生代和老年代的,这也是与G1的区别。
Shenandoah的GC过程如下: - 初始标记。标记GC ROOT,时长取决于GC ROOT的大小。需要停顿用户线程。
- 并发标记。根据引用追踪整个对象引用图。与用户线程并发。
- 最终标记。扫描SATB,确定回收集里有哪些Region。需要停顿用户线程。
- 并发清理。把没有一个存活对象的Region(称为immediate garbage regions)清理掉。
- 并发回收。将存活对象复制到其他区域。这个过程与G1最大的区别是可以与用户线程并发。
- 初始化引用更新。基本上没做啥,就是为了确保并发回收线程都跑完了,并且让用户线程也停下,以便下个阶段做引用更新。
- 并发更新引用。先行扫描堆,把引用全部更新到新的位置上去,这个过程可以与用户线程并发。
- 最终引用更新。更新GC ROOT的引用,释放回收集的Region,需要暂停用户线程。
- 并发清除。完成了上面各个步骤,留下了一些immediate garbage regions,一把清理掉。
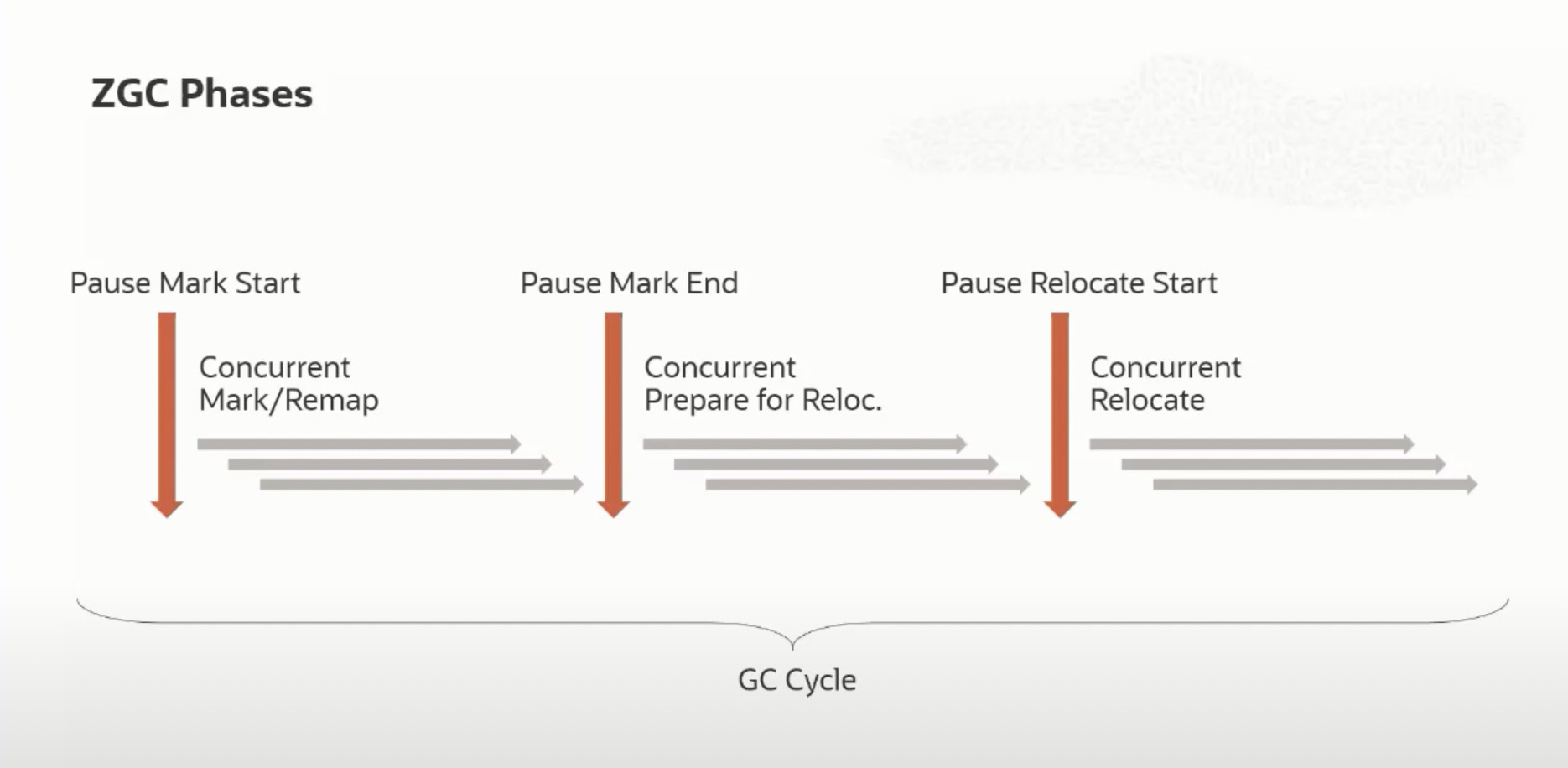
ZGC收集器
ZGC是openJDK中最新的收集器,目前还没有正式商用化。ZGC除了三个短暂的和堆大小无关的停顿之外,整个GC过程几乎都是和用户线程并发的。ZGC使用染色指针来标记对象的存活状态、finalizable状态和指针引用的有效性,因此无需单独维护记忆集,在移动对象后也可以不急于更新指针。
ZGC不使用写屏障,而是采用读屏障,在读取一个对象时,采用读屏障去判断染色指针的remap位,如果为0,说明指针是脏指针,需要在转发表上找到新地址,并且把指针更新到新地址上,再回复remap位为1。如果remap为1,说明指正已经是新的了,直接读取对象即可。
ZGC的工作过程大致可以分为以下几步:
- 开始标记。扫描栈,标记根节点。这个过程很短暂,需要停顿用户线程。
- 并发标记、重映射,从根节点出发,沿着对象图标记存活对象,把标记结果mark到染色指针上(marked0和marked1位),同时根据上一次relocate后的染色指针结果更新对象引用(通过判断染色指针的remap位,如果为0说明被移动过,从转发表上获取新地址,把引用更新到新地址上,并且把remap未恢复到1)。这个过程和用户线程并发。
- 结束标记。重新标记(相当于cms的remark),这时候暂停一下,也保证了所有标记线程都标记完了。很短暂。
- 重分配准备。根据标染色指针的marked0和marked1位可以很清楚的知道哪些对象是存活的,把它所在的region标记出来叫做重分配集。同时完成一些类卸载、弱引用处理等工作。这个过程是并发的。
- 开始重分配。扫描栈上的GC root,并且把在重分配集中的Root对象复制到新地址,并更新引用。也就是说,根对象是特殊对待的,会在一个专门的、暂停的过程中完成重分配。这个过程是暂停的。
- 并发重分配。把重分配集中的所有剩余对象(Root对象已经在上一阶段处理完)复制到新地址,并且在转发表中记录下他们的新旧地址关系。把染色指针的remap位置为0。
分类
是否可以和用户线程并行
关注点
思路转变
优缺点
参考
https://www.oracle.com/technetwork/tutorials/tutorials-1876574.html
https://wiki.openjdk.java.net/display/zgc
https://www.baeldung.com/jvm-zgc-garbage-collector
https://hllvm-group.iteye.com/group/topic/44381?page=2