HashMap深度解析
一、什么是哈希表
数据结构中的线性存储有数组和链表两大阵营,在实际应用中我们会根据我们的需求来选择存储方式。我们知道数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难。链表呢,弥补了数组的不足,却又失去了数组的优点,链表的存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N),所以它寻址困难,插入和删除容易。
如果我们需要一种既寻址较快,又插入、删除较方便的数据结构该怎么办呢?我们可否结合两个的优点呢,这就是我们要介绍的哈希表了。
哈希表((Hash table,也叫做散列表)既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。哈希表有多种实现方式,接下来介绍一种最常用的一种方法——拉链法,我们可以理解为“链表的数组” ,如图:
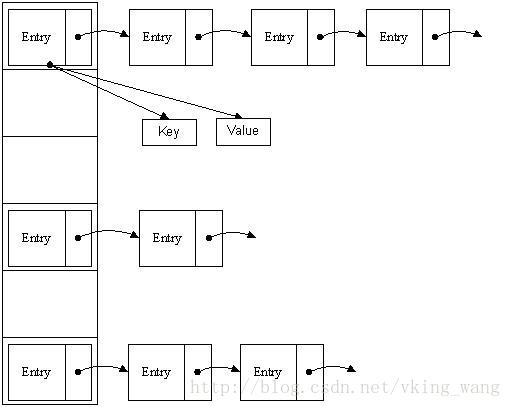
哈希表将数组和链表相结合,在把链表作为数组元素来存储,在链表节点上存储数据,hash表里可以存储元素的位置称为“桶”,即数组元素。
我们结合一个实例具体讲一下他的存储原理:
假设我们要存储一堆数据,我们通过Hash算法得到这些数据的Hash值,然后我们再根据其Hash值放入到数组里某个位置的链表中,具体位置的下标为hash(key)%array.length。
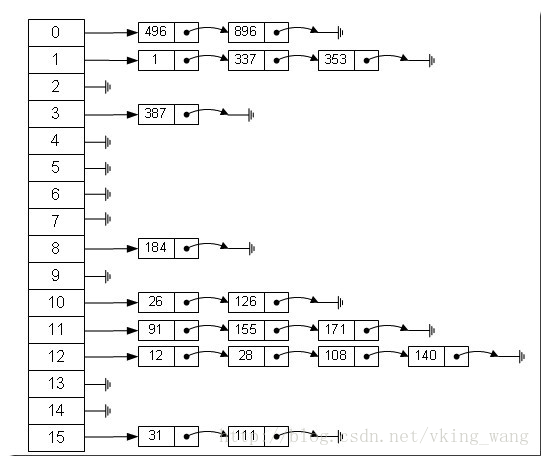
定义一个长度为16的数组,每个元素存储链表的头结点,比如对于Hash值是12、28、108、140的几个元素,因为12%16=12, 28%16=12, 108%16=12, 140%16=12。所以都存储在数组下标为12的位置。具体如下图所示:
二、简单提一下哈希(Hash)算法
哈希算法(哈希函数),即散列函数。它是一种单向密码体制,即它是一个从明文到密文的不可逆的映射,只有加密过程,没有解密过程。同时,哈希函数可以将任意长度的输入经过变化以后得到固定长度的输出。哈希函数的这种单向特征和输出数据长度固定的特征使得它可以生成消息或者数据典型的哈希算法包括 MD2、MD4、MD5 和 SHA-1。
三、HashMap
首先我们看一下HashMap的源码
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;//值为16,创建hash表时数组的大小
static final int MAXIMUM_CAPACITY = 1 << 30;//值为1073741824,表示hash表中数组最大长度
static final float DEFAULT_LOAD_FACTOR = 0.75f;//负载因子
static final Entry<?,?>[] EMPTY_TABLE = {};
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
transient int size; //当前hash表中记录的数量
源码中几个hash表的属性:
容量(capacity):hash表中桶的数量,即数组长度
初始化容量(initial capacity):创建hash表时桶的数量。HashMap和HashSet都允许再构造器中指定初始化容量。
尺寸(size):当前hash表中记录的数量。
负载椅子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的hash表,以此类推。轻负载的hash表具有冲突少、适宜插入和查询的特点,但是使用Iterator迭代较慢。
我们再看一下hash表的桶中链表的结点类——Entry类
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
可见,我们的HashMap就是完全根据我们的哈希表来实现的。
四、HashMap的存值
1、存值put方法
首先计算得到该数据key的hash值,然后根据把该hash值对数组长度进行取模,得到哈希表桶的数组下标,然后再拿该数据的key遍历对应桶内的链表,如果链表上已经有了该key值的数据,则进行value覆盖,否则添加一个新节点。 该数据一般为该链表的首节点(存储速度快)。实现代码如下:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value); //null总是放在数组的第一个链表中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//遍历链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//如果key在链表中已存在,则替换为新value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
2、hash表的扩充——再散列rehash过程
如果数据量较多时,链表的长度较长了,查询操作的性能将下降。这时呢,我们将进行hash表的扩充。
扩充方案(rehashing):默认的负载因子为0.75,如果size/capacity>0.75 时,将会创建原来桶数量两倍大小的hash表,并且将原来的hash表里的数据重新映射到新的hash表中。
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
//重新计算index
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
3、HashMap的哈希冲突解决
我么在看一些资料时经常提到哈希冲突,首先我们来明确一下什么叫哈希冲突。比如:数组的长度是5。这时有一个数据是6。那么如何把这个6存放到长度只有5的数组中呢。按照取模法,计算6%5,结果是1,那么就把6放到数组下标是1的位置。那么,7就应该放到2这个位置。到此位置,哈希冲突还没有出现。这时,有个数据是11,按照取模法,11%5=1,也等于1。那么原来数组下标是1的地方已经有数了,是6。这时又计算出1这个位置,那么数组1这个位置,就必须储存两个数了。这时,就叫哈希冲突。
常见的哈希冲突解决方案有开放地址法、拉链法、再散列(多重散列)、建立一个公共溢出区等。很明显,我们的HashMap采用的是拉链法。
五、HashMap的取值
1、取值get方法
先获取key的hash值,找到对应的桶,再遍历桶中的链表得到数据。
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
//先定位到数组元素,再遍历该元素处的链表
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
2、null key的存取
null key总是存放在Entry[]数组的第一个元素。
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
private V getForNullKey() {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
-----亓慧杰