spark04
join leftOuterjoin rightOuterJoin cogroup
|
scala> var arr = Array(("zhangsan",200),("lisi",300),("wangwu",350)) arr: Array[(String, Int)] = Array((zhangsan,200), (lisi,300), (wangwu,350)) scala> var arr1 = Array(("zhangsan",10),("lisi",15),("zhaosi",20)) arr1: Array[(String, Int)] = Array((zhangsan,10), (lisi,15), (zhaosi,20)) scala> sc.makeRDD(arr,3) res0: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at makeRDD at <console>:27 scala> sc.makeRDD(arr1,3) res1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at makeRDD at <console>:27 scala> scala> scala> res0 join res1 res2: org.apache.spark.rdd.RDD[(String, (Int, Int))] = MapPartitionsRDD[4] at join at <console>:33 scala> res2.mapValues(t=>t._1*t._2) res3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[5] at mapValues at <console>:35 scala> res3.collect res4: Array[(String, Int)] = Array((zhangsan,2000), (lisi,4500)) scala> res0 leftOuterJoin res1 res5: org.apache.spark.rdd.RDD[(String, (Int, Option[Int]))] = MapPartitionsRDD[8] at leftOuterJoin at <console>:33 scala> res5.mapValues(t=>t._1*t._2.getOrElse(0)) res6: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[9] at mapValues at <console>:35 scala> res6.collect res7: Array[(String, Int)] = Array((zhangsan,2000), (wangwu,0), (lisi,4500)) scala> scala> res0 rightOuterJoin res1 res8: org.apache.spark.rdd.RDD[(String, (Option[Int], Int))] = MapPartitionsRDD[12] at rightOuterJoin at <console>:33 scala> res8.mapValues(t=>t._1.getOrElse(0)*t._2) res9: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[13] at mapValues at <console>:35 scala> res9.collect res10: Array[(String, Int)] = Array((zhangsan,2000), (lisi,4500), (zhaosi,0)) scala> scala> res0 cogroup res1 res11: org.apache.spark.rdd.RDD[(String, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[15] at cogroup at <console>:33 scala> res11.mapValues(t=>t._1.sum*t._2.sum) res12: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[16] at mapValues at <console>:35 scala> res12.collect res13: Array[(String, Int)] = Array((zhangsan,2000), (wangwu,0), (lisi,4500), (zhaosi,0)) |
cartesian笛卡儿积
|
scala> var arr = Array(1,2,3,4,5,6) arr: Array[Int] = Array(1, 2, 3, 4, 5, 6) scala> var arr1 = Array("a","b","c") arr1: Array[String] = Array(a, b, c) scala> sc.makeRDD(arr,3) res14: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[17] at makeRDD at <console>:27 scala> sc.makeRDD(arr1,3) res15: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[18] at makeRDD at <console>:27 scala> res14 cartesian res15 res16: org.apache.spark.rdd.RDD[(Int, String)] = CartesianRDD[19] at cartesian at <console>:33 scala> res16.collect res17: Array[(Int, String)] = Array((1,a), (2,a), (1,b), (2,b), (1,c), (2,c), (3,a), (4,a), (3,b), (4,b), (3,c), (4,c), (5,a), (6,a), (5,b), (6,b), (5,c), (6,c)) |
repartition == coalesce
修改分区
|
scala> var arr = Array(1,2,3,4,5,6,7,8,9) arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) scala> sc.makeRDD(arr,3) res18: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[20] at makeRDD at <console>:27 scala> res18.partitions.size res19: Int = 3 scala> res18.repartition(4) res20: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[24] at repartition at <console>:29 scala> res20.partitions.size res21: Int = 4 scala> res18.repartition(2) res22: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[28] at repartition at <console>:29 scala> res22.partitions.size res23: Int = 2 |
repartition任意的改变分区
|
scala> res18.coalesce(2) res24: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[29] at coalesce at <console>:29 scala> res24.partitions.size res25: Int = 2 scala> res18.coalesce(6) res26: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[30] at coalesce at <console>:29 scala> res26.partitions.size res27: Int = 3 |
coalesce只能缩小分区不能增加分区数量

repartition底层调用的是coalesce,但是coalesce中加入的是shuffle=true
所以repartition含有shuffle流程

repartition存在shuffle
repartition = coalesce(true)
repartition存在shuffle coalesce不存在shuffle
最后一个rdd的分区数量才是这个阶段的task任务的个数
|
scala> var arr = Array(1,2,3,4,5,6) arr: Array[Int] = Array(1, 2, 3, 4, 5, 6) scala> sc.makeRDD(arr,3) res35: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[35] at makeRDD at <console>:27 scala> res35.repartition(4) res36: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[39] at repartition at <console>:29 scala> res36.collect res37: Array[Int] = Array(6, 4, 2, 1, 3, 5) |
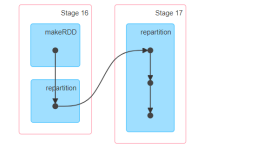
DAG有向无环图中,按照stage进行切分(shuffle流程),总共的task数量
stage中的所有的task任务的总和,每个stage中最后一个rdd的分区数量的和
aggreagte aggregateByKey
|
scala> res41.aggregate(10)(_+_,_+_) res42: Int = 85 scala> res41.aggregate(0)(_+_,_+_) res43: Int = 45 |
每个分区单独加一次,整体聚合加一次
第二个聚合函数是全体聚合
|
scala> var arr = Array(("a",1),("a",2),("a",5),("a",6),("b",3),("b",4)) arr: Array[(String, Int)] = Array((a,1), (a,2), (a,5), (a,6), (b,3), (b,4)) scala> sc.makeRDD(arr,2) res45: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[43] at makeRDD at <console>:27 scala> res45.aggregateByKey(0)(_+_,_+_) res46: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[44] at aggregateByKey at <console>:29 scala> res46.collect res47: Array[(String, Int)] = Array((b,7), (a,14)) scala> res45.aggregateByKey(10)(_+_,_+_) res48: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[45] at aggregateByKey at <console>:29 scala> res48.collect res49: Array[(String, Int)] = Array((b,17), (a,34)) |
aggregateByKey()全局聚合函数,初始化值每个分区加一次,但是全局聚合不加
aggregate是行动类算子 aggregateByKey是转换类算子
算子分为两类
行动类和转换类算子
行动类算子立即执行 转换类算子不会执行 转换类算子含有shuffle和没有shuffle
如果是shuffle类的算子会切分阶段,没有shuffle的算子都处于一个阶段
RDD的五大特性(重点)

五大特性

- 每个rdd都是默认被分区的。含有一系列的分区列表
- 专门存在一个函数用来处理每一个rdd的分区
- 每个rdd之间存在依赖关系
- 再key-value键值对的形式的rdd上面存在可选择的分区器
- 优先位置进行计算每一个分区/分片
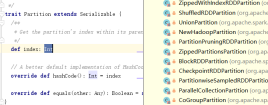

分区是一个特质,其中存在index下标 hashcode方法 equals方法
分区就是一个rdd上面的分岔路,每个路口流动的数据要交给一个task线程进行处理
每个rdd都会存在一个或者多个分区,读取hdfs文件的时候,每个分区对应的是一个block块,其实分区就是记录了数据的位置在哪里,每个分区应该从哪个block中读取数据。
每个分区交给一个executor的一个线程处理
compute函数

每个rdd上面都会存在一个compute方法专门来计算每一个分区中的数据
所有的算子进行数据处理的时候都会交给compute方法进行统一计算
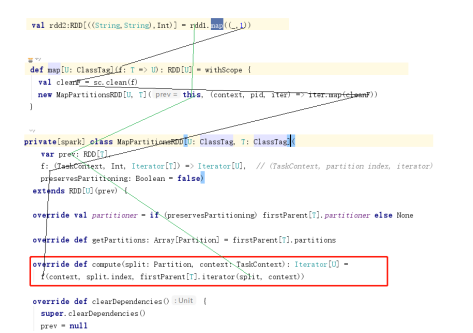
compute方法可以统一处理每一个算子中的逻辑,用compute使用算子中的函数,将rdd每个分区中的数据进行迭代处理
每个rdd之间存在依赖关系
依赖关系存在两种,一对一的(pipeline) 多对多shuffle
什么是依赖关系?算子

每个rdd上面都存在一个获取依赖关系的函数getDependencies

根据两个rdd之间调用的算子不一样产生的依赖关系主要分为两种
宽依赖和窄依赖
存在shuffle的就是宽依赖 没有shuffle的,一对一的就是窄依赖
窄依赖存在两种关系 OneToOne RangeDependency

OneToOneDependency一对一的依赖 map mapValues flatMap...
RangeDependency 只有sortByKey
比如map算子




可以看出map算子就是窄依赖
宽依赖shuffleDependency


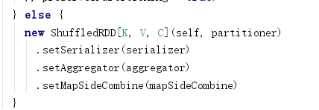
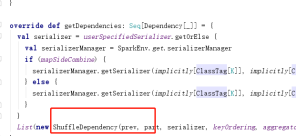
最后可以得到reduceByKey是shuffleDependency
可选择的分区器partitioner必须再k-v得rdd上面存在分区器,默认得rdd上面不存在分区器
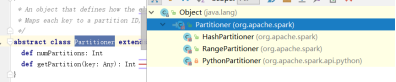
分区器自带得主要分为两种,hashPartitioner rangePartitioner
reduceByKey groupByKey distinct 使用得都是hashPartitioner
sortByKey rangePartitioner 依赖关系也是rangeDependency
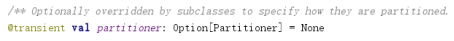
rdd上面自带得属性,分区器partitioner,默认是None
|
scala> sc.makeRDD(Array(1,2,3,4,5,6,7,8,9),3) res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:25 scala> res0.partitioner res1: Option[org.apache.spark.Partitioner] = None scala> scala> sc.makeRDD(Array(("a",1),("a",1),("b",1),("b",1))) res2: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[1] at makeRDD at <console>:25 scala> res2.partitioner res3: Option[org.apache.spark.Partitioner] = None scala> res2.reduceByKey(_+_) res5: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[2] at reduceByKey at <console>:27 scala> res5.partitioner res6: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@18) scala> res5.sortByKey() res7: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[5] at sortByKey at <console>:29 scala> res7.partitioner res8: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.RangePartitioner@1f12d) |
reduceByKey使用的是HashPartitioner所以两个rdd之间得依赖宽依赖shuffleDependency
sortByKey使用得是RangeDependency 所以依赖关系是rangeDependency
|
scala> var arr = Array(1,2,3,4,5,6,7,8,9) arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) scala> arr.zipWithIndex res9: Array[(Int, Int)] = Array((1,0), (2,1), (3,2), (4,3), (5,4), (6,5), (7,6), (8,7), (9,8)) scala> sc.makeRDD(res9,3) res10: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[6] at makeRDD at <console>:29 scala> res10.reduceByKey(_+_) res11: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[7] at reduceByKey at <console>:31 scala> res11.mapPartitionsWithIndex((a,b)=>b.map((a,_))) res12: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[8] at mapPartitionsWithIndex at <console>:33 scala> res12.collect res13: Array[(Int, (Int, Int))] = Array((0,(6,5)), (0,(3,2)), (0,(9,8)), (1,(4,3)), (1,(1,0)), (1,(7,6)), (2,(8,7)), (2,(5,4)), (2,(2,1))) |
reduceByKey使用得hashpartitioner
|
scala> var arr = Array(1,2,10000,20000,30000,40000,5000,60000,70000,8,9000000) arr: Array[Int] = Array(1, 2, 10000, 20000, 30000, 40000, 5000, 60000, 70000, 8, 9000000) scala> sc.makeRDD(arr,3) res17: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[13] at makeRDD at <console>:27 scala> res17.zipWithIndex res18: org.apache.spark.rdd.RDD[(Int, Long)] = ZippedWithIndexRDD[14] at zipWithIndex at <console>:29 scala> res18.sortByKey() res19: org.apache.spark.rdd.RDD[(Int, Long)] = ShuffledRDD[17] at sortByKey at <console>:31 scala> res19.mapPartitionsWithIndex((a,b)=>b.map((a,_))) res20: org.apache.spark.rdd.RDD[(Int, (Int, Long))] = MapPartitionsRDD[18] at mapPartitionsWithIndex at <console>:33 scala> res20.collect res21: Array[(Int, (Int, Long))] = Array((0,(1,0)), (0,(2,1)), (0,(8,9)), (0,(5000,6)), (1,(10000,2)), (1,(20000,3)), (1,(30000,4)), (1,(40000,5)), (2,(60000,7)), (2,(70000,8)), (2,(9000000,10))) |
rangeDependency尽量得保证了数据在数值得范围和数值得个数两个因素上面保证平均
|
scala> res18.sortByKey(true,20) res23: org.apache.spark.rdd.RDD[(Int, Long)] = ShuffledRDD[21] at sortByKey at <console>:31 scala> res23.partitions.size res24: Int = 12 |
sortBykey使用得rangePartitioner,重新分区得时候,如果分区数字比元素得个数还要大,那么重新分区得个数就不能起作用,最少保证一个分区中应该含有一个数据
优先位置

rdd === aa.txt= ===hdfs ===== 2 blk ==== 2 partition ===每个分区得读取文件得位置
找到对应得blk块得位置,在本地进行运算
移动计算比移动数据本身更划算
以上为五个特性(重点)
分区列表
一个compute方法用于计算
依赖关系
在k-v得rdd上存在一个可选择得分区器
优先位置进行计算
自定义分区器:
|
object WordCountPartition { |
老师得访问量,专业得topN,将每个老师对应得专业进行分区,每个分区中都是一个专业得全部老师,然后将分区中得数据进行排序,就可以得到topN
自定partitioner 然后mapPartitions每次遍历一个分区中得数据,得到topN
作业:
分区器得形式进行教师得专业排名?
spark版本得电影推荐算法,每个人最喜欢得类型?
wordcount中得rdd个数
通过println(rdd.toDebugString)

本地模式是5个rdd
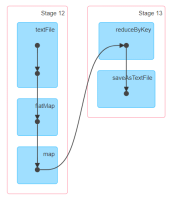
wordcount中存在6个rdd