spark02
自定义资源分配
--executor-cores
--executor-memory
--total-executor-cores 最大允许使用多少核数
3台机器 每个机器8cores 1G
|
--executor-cores |
--executor-memory |
--total-executor-cores |
executors |
|
8 |
1G |
3 |
|
|
4 |
1G |
3 |
|
|
4 |
1G |
4 |
1 |
|
4 |
512M |
6 |
|
|
4 |
512M |
8 |
2 |
|
6 |
512M |
3 |
RDD的简介
At a high level, every Spark application consists of a driver program that runs the user’s main function and executes various parallel operations on a cluster. The main abstraction Spark provides is a resilient distributed dataset (RDD), which is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. RDDs are created by starting with a file in the Hadoop file system (or any other Hadoop-supported file system), or an existing Scala collection in the driver program, and transforming it. Users may also ask Spark to persist an RDD in memory, allowing it to be reused efficiently across parallel operations. Finally, RDDs automatically recover from node failures.
RDD是弹性分布式数据集,默认是被分区的(结果文件存在多个),可以并行的在多台机器上进行运行处理,创建方式存在一下几种1.读取hdfs中的文件 2本地集合创建 3转换类算子进行创建。可以将rdd的数据持久化保存在内存中,rdd含有故障恢复功能
弹性:可大可小,故障恢复
分布式:默认rdd是被分区的,数据会在多台机器上运行处理
数据集: 我们使用的时候可以当作是其中含有数据

ctrl+h查看实现类
创建rdd的三种形式
|
sc.textFile("hdfs://master:9000/aaa.txt") res0: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/aaa.txt MapPartitionsRDD[1] at textFile at <console>:25 scala> res0.partitions.size res1: Int = 2 |
读取外部文件的形式产生的rdd
RDD自带分区效果,弹性分布式的数据集,分布式的概念就是一个集合的数据会拆分成多个部分,每个部分交给不同的executor进行执行
|
scala> sc.makeRDD(Array(1,2,3,4,5,6)) res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:25 scala> res0.partitions.size res1: Int = 24 scala> sc.parallelize(Array(1,2,3,4,5,6)) res2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:25 scala> res2.partitions.size res3: Int = 24 |
集合并行化的方式创建的rdd

makerdd底层调用的方法就是parallize方法
|
scala> res2.map(_*10) res4: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[2] at map at <console>:27
scala> res4.partitions.size res5: Int = 24 |
调用转换类算子可以实现产生新的rdd,这种rdd默认情况和原来的rdd的分区数量一致
map flatMap groupBy ....filter
创建方式
读取hdfs文件的情况下,默认分区数量是2
将本地集合并行化的方式产生的rdd,分区数量是最大的集群cores
转换类算子产生的rdd分区数量与原rdd的分区数量一致(默认情况)
创建rdd的分区数量
|
scala> sc.textFile("hdfs://master:9000/flume123") res8: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/flume123 MapPartitionsRDD[6] at textFile at <console>:25 scala> res8.partitions.size res9: Int = 2 scala> sc.textFile("hdfs://master:9000/flume") res10: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/flume MapPartitionsRDD[8] at textFile at <console>:25 scala> res10.partitions.size res11: Int = 5 scala> sc.textFile("hdfs://master:9000/flume") res12: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/flume MapPartitionsRDD[10] at textFile at <console>:25 scala> res12.partitions.size res13: Int = 5 scala> sc.textFile("hdfs://master:9000/result321") res14: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/result321 MapPartitionsRDD[12] at textFile at <console>:25 scala> res14.partitions.size res15: Int = 3 scala> sc.textFile("hdfs://master:9000/seria002") res16: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/seria002 MapPartitionsRDD[14] at textFile at <console>:25 scala> res16.partitions.size res17: Int = 4 |
读取外部文件的时候创建的rdd分区数量默认和Block块的数量一致
如果一个文件只有一个block块,那么这个文件的默认分区数量是2
一个文件在hdfs中存在多少个block块就应该对应多少个分区。因为一个分区对应一个线程进行处理,一个线程对应一个block块,属于本地化处理方式,移动计算比移动数据本身更划算。但是如果block块小于2,那么默认分区数量就是2
|
scala> sc.textFile("hdfs://master:9000/seria002",5) res18: org.apache.spark.rdd.RDD[String] = hdfs://master:9000/seria002 MapPartitionsRDD[16] at textFile at <console>:25 scala> res18.partitions.size res19: Int = 8 |
读取hdfs中文件的时候,如果改变分区数量,那么分区数量会自适配
|
scala> sc.makeRDD(Array(1,2,3,4,5,6),4) res23: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[18] at makeRDD at <console>:25 scala> res23.partitions.size res24: Int = 4 scala> sc.parallelize(Array(1,2,3,4,5,6),4) res25: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[19] at parallelize at <console>:25 scala> res25.partitions.size res26: Int = 4 |
集合并行化的创建方式,可以根据分区数量进行任意修改
|
scala> val func=(x:Int)=>x func: Int => Int = <function1> scala> res25.groupBy(func,3) res33: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[23] at groupBy at <console>:29 scala> res33.partitions.size res34: Int = 3 |
转换类算子转换成的rdd默认分区数量不会做修改,但是会存在一些可以改分区的算子
groupBy sortByKey reduceByKey groupBykey。。。产生shuffle
repartition coalesce
专门做分区修改的
|
scala> res25.partitions.size res35: Int = 4 scala> res25.repartition(5) res36: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[27] at repartition at <console>:27 scala> res36.partitions.size res37: Int = 5 scala> res25.coalesce(2) res38: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[28] at coalesce at <console>:27 scala> res38.partitions.size res39: Int = 2 |
rdd上面的算子
算子分为两种,第一种transformation转换类算子 action行动类算子
转换类算子可以将rdd转换为另一个rdd,不会执行懒加载的
行动类算子 不会转换为新的rdd,会直接运行整个任务
收集collect将多个节点的数据收集到driver中
saveAsTextFile保存结果文件到一个新的介质中
foreach遍历每一个数据
得出一个结果 count reduce
map算子
|
scala> res25.map(_*10) res41: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[29] at map at <console>:27 |
遍历每一个元素,分区数量不会发生改变
mapvalues在scala中遍历每一个value,只能作用于map集合
在spark中作用于RDD[(k,v)]
|
scala> var rdd = sc.makeRDD(Array((1,1),(2,2),(3,3))) rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[30] at makeRDD at <console>:24 scala> rdd.mapValues(_*10) res42: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[31] at mapValues at <console>:27 scala> res42.collect res43: Array[(Int, Int)] = Array((1,10), (2,20), (3,30)) |
mapPartitions遍历每一个分区
|
scala> sc.makeRDD(arr,3) res44: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[32] at makeRDD at <console>:27 scala> res44.map(_*10) res45: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[33] at map at <console>:29 scala> res44.mapPartitions(_*10) <console>:29: error: value * is not a member of Iterator[Int] Error occurred in an application involving default arguments. res44.mapPartitions(_*10) ^ scala> res44.mapPartitions(t=>t.map(_*10)) res47: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[34] at mapPartitions at <console>:29 scala> res47.collect res48: Array[Int] = Array(10, 20, 30, 40, 50, 60, 70, 80, 90) |
map调用的次?有多少元素就调用多少次
mapPartitions 每个分区调用一次,有多少个分区就调用多少次
连接数据库,通过字段查询数据库中的信息,可以通过mapPartitions进行优化,减少创建连接的次数
zipWithIndex
|
scala> res47.zipWithIndex res49: org.apache.spark.rdd.RDD[(Int, Long)] = ZippedWithIndexRDD[35] at zipWithIndex at <console>:31 scala> res49.collect res50: Array[(Int, Long)] = Array((10,0), (20,1), (30,2), (40,3), (50,4), (60,5), (70,6), (80,7), (90,8)) |
与scala中不同的是,zipWithIndex的下标是long类型,因为在spark中的数据量比较大
MapPartitionsWithIndex每次遍历一个分区中的数据并且带有分区编号
|
scala> var arr = Array(1,2,3,4,5,6,7,8,9) arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) scala> sc.makeRDD(arr,3) res51: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[36] at makeRDD at <console>:27 scala> res51.mapPartitionsWithIndex def mapPartitionsWithIndex[U](f: (Int, Iterator[Int]) => Iterator[U],preservesPartitioning: Boolean)(implicit evidence$9: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U] scala> res51.mapPartitionsWithIndex def mapPartitionsWithIndex[U](f: (Int, Iterator[Int]) => Iterator[U],preservesPartitioning: Boolean)(implicit evidence$9: scala.reflect.ClassTag[U]): org.apache.spark.rdd.RDD[U] scala> res51.mapPartitionsWithIndex((a,b)=>b.map((a,_))) res52: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[37] at mapPartitionsWithIndex at <console>:29 scala> res52.collect res53: Array[(Int, Int)] = Array((0,1), (0,2), (0,3), (1,4), (1,5), (1,6), (2,7), (2,8), (2,9))
scala> res51.mapPartitionsWithIndex((n,d)=>d.map((n,_))) res55: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[38] at mapPartitionsWithIndex at <console>:29 scala> res55.collect res56: Array[(Int, Int)] = Array((0,1), (0,2), (0,3), (1,4), (1,5), (1,6), (2,7), (2,8), (2,9)) |
mapPartitionsWithIndex((a,b)=>b.map((a,_))) a分区编号 b这个分区中的所有元素
flatMap算子
在spark中只存在flatMap算子不存在flatten算子
|
scala> var arr = Array("hello jack","hello tom","tom jack") arr: Array[String] = Array(hello jack, hello tom, tom jack) scala> sc.makeRDD(arr,3) res57: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[39] at makeRDD at <console>:27 scala> res57.flatMap(_.split(" ")) res58: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[40] at flatMap at <console>:29 scala> res58.collect res59: Array[String] = Array(hello, jack, hello, tom, tom, jack) |
filter算子
|
scala> var arr = Array(1,2,3,4,5,6,7,8,9) arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9) scala> sc.makeRDD(arr,3) res60: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[41] at makeRDD at <console>:27 scala> res60.filter(_>5) res61: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[42] at filter at <console>:29 scala> res61.collect res62: Array[Int] = Array(6, 7, 8, 9) scala> res60.mapPartitionsWithIndex((a,b)=>b.map((a,_))) res63: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[43] at mapPartitionsWithIndex at <console>:29 scala> res63.collect res64: Array[(Int, Int)] = Array((0,1), (0,2), (0,3), (1,4), (1,5), (1,6), (2,7), (2,8), (2,9)) scala> res61.mapPartitionsWithIndex((a,b)=>b.map((a,_))) res65: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[44] at mapPartitionsWithIndex at <console>:31 scala> res65.collect res66: Array[(Int, Int)] = Array((1,6), (2,7), (2,8), (2,9)) |
filter算子可以过滤掉分区中的数据,但是数据清空后分区依旧存在
groupBy
scala中返回的数据是Map格式的,key是分组的key value是原来数据的一个部分片段
|
scala> var arr = Array(("a",1),("b",1),("a",1)) arr: Array[(String, Int)] = Array((a,1), (b,1), (a,1)) scala> sc.makeRDD(arr,3) res67: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[45] at makeRDD at <console>:27 scala> res67.groupBy(_._1) res69: org.apache.spark.rdd.RDD[(String, Iterable[(String, Int)])] = ShuffledRDD[47] at groupBy at <console>:29 |
在spark中返回数据的类型是迭代器形式
返回值的类型是RDD[k,Iterable[原来的数据]],group by算子可以重新分区
groupByKey按照key进行分组
|
scala> sc.makeRDD(res59,3) res72: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[48] at makeRDD at <console>:33 scala> res72.map((_,1)) res73: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[49] at map at <console>:35 scala> res73.groupBy(_._1) res74: org.apache.spark.rdd.RDD[(String, Iterable[(String, Int)])] = ShuffledRDD[51] at groupBy at <console>:37 scala> res73.groupByKey() res75: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[52] at groupByKey at <console>:37 scala> res73.groupByKey(6) res76: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[53] at groupByKey at <console>:37 scala> res76.partitions.size res77: Int = 6 |
groupByKey分组,分组的结果中key就是分组的key值,value就是原来value的一个集合
reduceByKey按照key值进行合并规约
|
scala> res73.collect res78: Array[(String, Int)] = Array((hello,1), (jack,1), (hello,1), (tom,1), (tom,1), (jack,1)) scala> res73.groupByKey() res79: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[54] at groupByKey at <console>:37 scala> res79.mapValues(_.sum) res80: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[55] at mapValues at <console>:39 scala> res80.collect res81: Array[(String, Int)] = Array((tom,2), (hello,2), (jack,2)) scala> res73.reduceByKey(_+_) res82: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[56] at reduceByKey at <console>:37 scala> res82.collect res83: Array[(String, Int)] = Array((tom,2), (hello,2), (jack,2)) |
reduceBykey可以按照key进行直接聚合
reduceBykey和groupBykey的区别
|
scala> res73.partitions.size res84: Int = 3 scala> res73.reduceByKey(_+_,4) res85: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[57] at reduceByKey at <console>:37 scala> res85.partitions.size res86: Int = 4 |
reduceByKey也可以改变分区数量
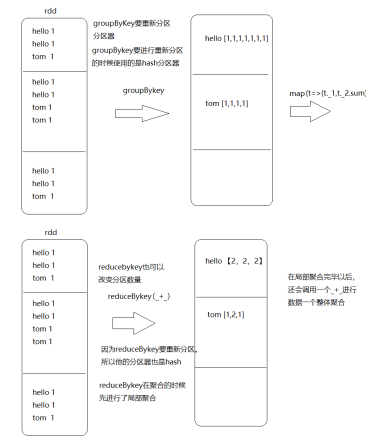
reducebyKey在做重新分区的时候,要将数据局部聚合一下,shuffle流程中可以大大的减少io,groupByKey只能分组不能局部聚合不会较少io消耗,groupByKey+map ==reducebykey
groupBykey 和reduceByKey都可以改变分区数量
action算子
foreach算子一一映射的关系,对于集合中的每条数据进行操作,返回值是unit
算子不执行,算子定义的是一种执行规则,map(_*10) filter mapPartitions....
|
scala> sc.makeRDD(Array(1,2,3,4,5,6,7,8,9)) res87: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[58] at makeRDD at <console>:25 scala> res87.foreach(println) |
foreach算子遍历每一个元素,处理的结果没有返回值
但是不会在交互式命令行中打印任何数据
因为rdd是分布式的默认带有分区的,所以每一个分区都交给一个executor进行处理,所以每个executor打印自己的数据,不会将数据显示在客户端中。如果想要进行显示数据,需要将数据都收集到一个driver端的内存中,一起打印
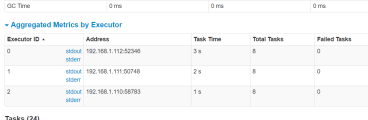
每个executor单独执行自己的数据打印,显示在executor的输出端

foreach算子运行了两次,每次的打印结果都不相同
executor在执行任务的时候,两次执行对应的分区不一定一致
foreachPartition每次遍历一个分区中的数据
每次遍历一个分区的数据
|
res90.foreachPartition(t=>t.foreach(println)) |