


Sqoop教案
1. Sqoop介绍
Apache Sqoop(SQL-to-Hadoop) 项目旨在协助 RDBMS 与 Hadoop 之间进行高效的大数据交流。用户可以在 Sqoop 的帮助下,轻松地把关系型数据库的数据导入到 Hadoop 与其相关的系统 (如HBase和Hive)中;同时也可以把数据从 Hadoop 系统里抽取并导出到关系型数据库里。除了这些主要的功能外,Sqoop 也提供了一些诸如查看数据库表等实用的小工具。理论上,Sqoop 支持任何一款支持 JDBC 规范的数据库,如 DB2、MySQL 等。Sqoop 还能够将 DB2 数据库的数据导入到 HDFS 上,并保存为多种文件类型。常见的有定界文本类型,Avro 二进制类型以及 Sequence Files 类型。
Sqoop中一大亮点就是可以通过hadoop的mapreduce把数据从关系型数据库中导入数据到HDFS。Sqoop架构非常简单,其整合了Hive、Hbase和Oozie,通过map-reduce任务来传输数据,从而提供并发特性和容错。
简单说,Sqoop就是一个转换工具,用于在关系型数据库与HDFS之间进行数据转换。强大功能见下图:

2. Sqoop安装
2.1 安装包下载
下载地址:http://mirrors.hust.edu.cn/apache/sqoop/

这里有两个版本,1.4.x 为Sqoop 1 版本,1.99.x为Sqoop 2 版本,这里两个都要下载,分别下载sqoop-1.4.6.bin__hadoop-0.23.tar.gz和sqoop-1.99.6-bin-hadoop200.tar.gz两个压缩包。
2.2 解压安装
我们先讲解Sqoop 1 版本的安装使用。
将sqoop-1.4.6.bin__hadoop-0.23.tar.gz上传的虚拟机中的准备安装目录下。
我这里的安装目录为:/hadoop/
解压缩
# > tar -xvf sqoop-1.4.6.bin__hadoop-0.23.tar.gz
重命名为sqoop
# > mv sqoop-1.4.6.bin__hadoop-0.23 sqoop
2.3 设置环境变量
在文件/etc/profile中设置环境变量SQOOP_HOME:
# > vim /etc/profile
设置内容:
export SQOOP_HOME=/hadoop/sqoop
export PATH=$PATH:$SQOOP_HOME/bin:
# > source /etc/profile
把mysql的jdbc驱动mysql-connector-java-5.1.32-bin.jar复制到sqoop项目的lib目录下:
# > cp mysql-connector-java-5.1.32-bin.jar /hadoop/sqoop/lib/
2.4 修改配置文件
复制名配置文件
在${SQOOP_HOME}/conf中执行命令
# > cp sqoop-env-template.sh sqoop-env.sh
设置内容如下:
2.5 试运行
执行命令如下:
# > sqoop version
Success!
3. Sqoop原理
3.1 Sqoop架构图
Sqoop 1 架构

Sqoop 2架构
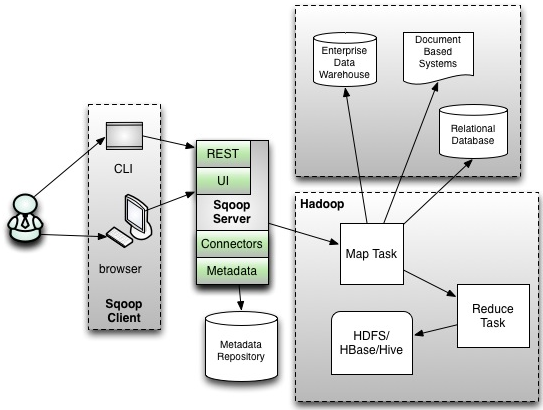
3.2 Sqoop1大概流程
读取要导入数据的表结构,生成运行类,默认是QueryResult,打成jar包,然后提交给Hadoop,设置好job,主要也就是设置好各个参数,这里就由Hadoop来执行MapReduce来执行Import命令。
1) 首先要对数据进行切分,也就是DataSplit,DataDrivenDBInputFormat.getSplits(JobContext job)。
2) 切分好范围后,写入范围,以便读取DataDrivenDBInputFormat.write(DataOutput output),这里是lowerBoundQuery and upperBoundQuery。
3) 读取以上2)写入的范围DataDrivenDBInputFormat.readFields(DataInput input)。
4) 然后创建RecordReader从数据库中读取数据DataDrivenDBInputFormat.createRecordReader(InputSplit split,TaskAttemptContext context)。
5) 创建MAP,MapTextImportMapper.setup(Context context)。
6) RecordReader一行一行从关系型数据库中读取数据,设置好Map的Key和Value,交给MapDBRecordReader.nextKeyValue()。
7) 运行MAP,mapTextImportMapper.map(LongWritable key, SqoopRecord val, Context context),最后生成的Key是行数据,由QueryResult生成,Value是NullWritable.get()。
3.3 Sqoop 1与 Sqoop 2 对比
sqoop1优点:架构部署简单
sqoop1缺点:命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏, 安装需要root权限,connector必须符合JDBC模型。
sqoop2优点:多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写
sqoop2缺点:架构稍复杂,配置部署更繁琐。
3.4 Sqoop的Import
Sqoop在import时,需要制定split-by参数。Sqoop根据不同的split-by参数值来进行切分,然后将切分出来的区域分配到不同map中。每个map中再处理数据库中获取的一行一行的值,写入到HDFS中。同时split-by根据不同的参数类型有不同的切分方法,如比较简单 的int型,Sqoop会取最大和最小split-by字段值,然后根据传入的num-mappers来确定划分几个区域。 比如select max(split_by),min(split-by) from得到的max(split-by)和min(split-by)分别为1000和1,而num-mappers为2的话,则会分成两个区域 (1,500)和(501-100),同时也会分成2个sql给2个map去进行导入操作,分别为select XXX from table where split-by>=1 and split-by<500和select XXX from table where split-by>=501 and split-by<=1000。最后每个map各自获取各自SQL中的数据进行导入工作。
3.4 Sqoop的Export
Sqoop可以在HDFS/Hive和关系型数据库之间进行数据的导入导出,其中主要使用了import和export这两个工具。这两个工具非常强大,提供了很多选项帮助我们完成数据的迁移和同步。比如,下面两个潜在的需求:
- 业务数据存放在关系数据库中,如果数据量达到一定规模后需要对其进行分析或同统计,单纯使用关系数据库可能会成为瓶颈,这时可以将数据从业务数据库数据导入(import)到Hadoop平台进行离线分析。
- 对大规模的数据在Hadoop平台上进行分析以后,可能需要将结果同步到关系数据库中作为业务的辅助数据,这时候需要将Hadoop平台分析后的数据导出(export)到关系数据库。