1.hive的安装
解压就完事了
配置/etc/profile环境变量
启动hdfs
启动hive
cp $HIVE_HOME/lib/jline.xxxxx $HADOOP_HOME/share/hadoop/yarn/lib
2.show databases;查看数据库
3.show tables;
4.create database xxxxx
5.desc tablename;
6.create table tablename(column columnType....)
tinyInt smallint int bigint String float double array struct map timestamp binary
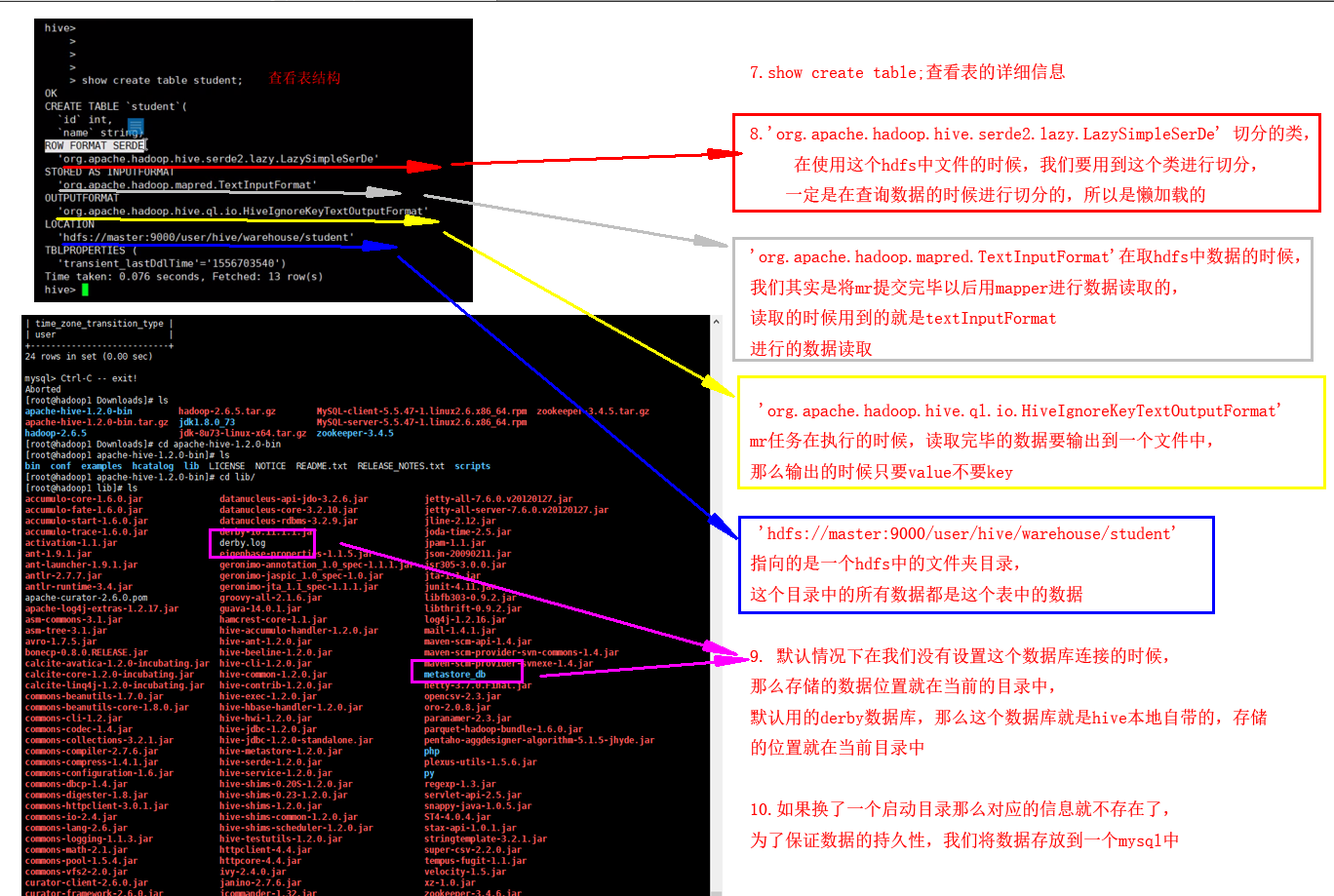
7.show create table;查看表的详细信息
8.'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' 切分的类,在使用这个hdfs中文件的时候,我们要用到这个类进行切分,
一定是在查询数据的时候进行切分的,所以是懒加载的
'org.apache.hadoop.mapred.TextInputFormat'在取hdfs中数据的时候,我们其实是将mr提交完毕以后用mapper进行数据读取的,读取的时候用到的就是textInputFormat
进行的数据读取
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' mr任务在执行的时候,读取完毕的数据要输出到一个文件中,那么输出的时候只要value不要key
'hdfs://master:9000/user/hive/warehouse/student'指向的是一个hdfs中的文件夹目录,这个目录中的所有数据都是这个表中的数据
9. 默认情况下在我们没有设置这个数据库连接的时候,那么存储的数据位置就在当前的目录中,默认用的derby数据库,那么这个数据库就是hive本地自带的,存储
的位置就在当前目录中
10.如果换了一个启动目录那么对应的信息就不存在了,为了保证数据的持久性,我们将数据存放到一个mysql中

export HIVE_HOME=/root/Downloads/apache-hive-1.2.0-bin export PATH=$PATH:$HIVE_HOME/bin cp /root/Downloads/apache-hive-1.2.0-bin/lib/jline-2.12.jar /root/Downloads/hadoop-2.6.5/share/hadoop/yarn/lib