参考文档: Adaptive Thresholding for the DigitalDesk.pdf
Adaptive Thresholding Using the Integral Image.pdf
一、问题的由来
一个现实: 当用照像机拍摄一副黑纸白字的纸张时,照相机获得的图像并不是真正的黑白图像。不管从什么角度拍摄,这幅图像实际上是灰度或者彩色的。除非仔细的设置灯光,否则照相机所拍摄的放在桌子上的纸张图像并不能代表原始效果。不像在扫描仪或打印机内部,想控制好桌子表面的光源是非常困难的。这个开放的空间可能会受到台灯、吊灯、窗户、移动的影子等影响。人类的视觉系统能自动补偿这些,但是机器没有考虑到这些因素因此拍出的效果会很差。
这个问题在处理那种高对比度的艺术线条或文字时尤为突出,因为这些东西都是真正的黑色或白色。而摄像头会产生一副具有不同等级的灰度图像。许多应用都必须清楚的知道图像的那一部分是纯黑或纯白,以便将文字传递给OCR软件去识别。这些系统无法使用灰度图像(典型的是8位每像素),因此必须将他们转换为黑白图像。这有很多种方式去实现。在某些情况下,如果这些图像最终是给人看的,这些图像会使用一些抖动技术,以便使他们看起来更像灰度图像。但是对于机器处理的过程,比如文字识别,选择复制操作,或多个图像合成,系统就不可以使用抖动的图像。系统仅仅需要简单的线条、文字或相对大块的黑色和白色。从灰度图像获得这种黑白图像的过程通常称作为阈值化。
有很多种方式来阈值化一副图像,但是基本的处理过程都是检查每一个灰度像素,然后决定他是白色和还是黑色。本文描述了已经开发的不同的算法来阈值一副图像,然后提出了一种比较合适的算法。这个算法(这里我们称之为快速自适应阈值法)可能不是最合适的。但是他对我们所描述的问题处理的相当好。
二、全局阈值法
在某种程度上说,阈值法是对比度增强的极端形式,或者说他使得亮的像素更亮而暗的像素更暗。最简单的(也是最常用的)方法就是将图像中低于某个阈值的像素设置为黑色,而其他的设置为白色。那么接着问题就是如何设置这个阈值。一种可能性就是选择所有可能取值的中间值,因此对于8位深的图像(范围从0到255),128将会被选中。这个方法在图像黑色像素确实在128以下,而白色也在128以上时工作的很好。但是如果图像过或欠曝光,图像可能全白或全黑。所以找到图像实际的取值范围代替可能取值范围会更好些。首先找到图像中所有像素的最大值和最小值,然后取中点作为阈值。一个更好的选择阈值的方法是不仅查看图像实际的范围,还要看其分布。比如说,你希望图像类似于一副黑色线条画,或者在白纸上的文字效果,那么你就期望大部分像素是背景颜色,而少部分是黑色。一副像素的直方图可能如图1所示。
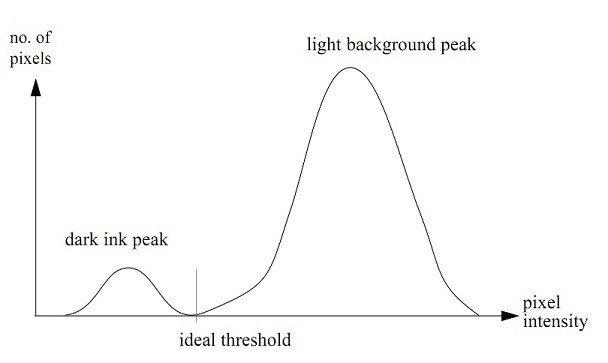
图1
上图中,可以发现一个背景颜色的大峰值,以及一个黑色墨水的小的峰值。根据周围的光线整个曲线可想向左或者向右偏移,但是在任何情况下,最理想的阈值就是在两个峰值之间的波谷处。这在理论上很好,但是他在实际中到底表现如何呢。
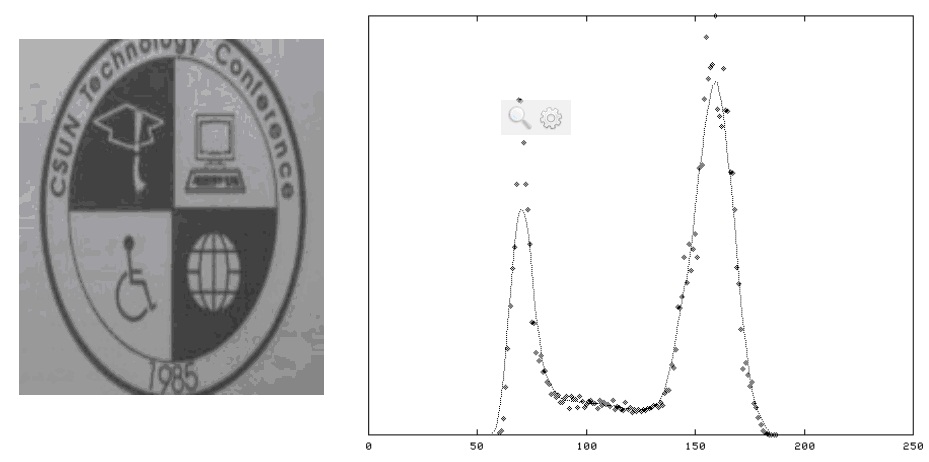
图 2
图2及其直方图显示整个技术工作的很好。平滑后的直方图显示出2个潜在的峰值,通过拟合直方图曲线或简单的取两个峰值之间的平均值来计算出一个近似理想阈值并不是一件困难的事情。这不是一个典型的图像,因为他有大量的黑色和白色的像素点。算法必须还要对类似图3这样的图像进行阈值处理。这这幅图像的直方图中,较小的黑色峰值已经掩埋在噪音中,因此要可靠地在峰值之间确定哈一个最小值是不太可能的。
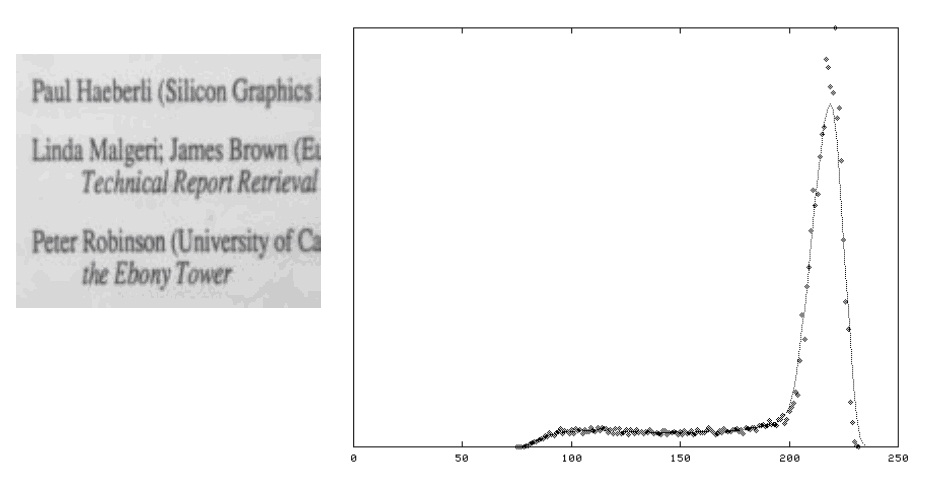
图 3
在任何情况下,一个大的(背景)峰值总是存在的并且也容易找到,因此,一个有用的阈值策略可描述如下:
1) 计算直方图。
2) 按照一定的半径对直方图数据进行平滑,并计算平滑后数据的最大值。平滑的目的减少噪音对最大值的影响,如图2和图3所示。
3) 根据上述峰值和最小值(不包括在直方图中为0的项)的距离按照一定的比例选择阈值。
试验表明这个距离的一半能够对很大范围内的图像产生相当好的效果,从非常亮到几乎完全黑的图像。比如,在图3中,峰值在215处,而最小值为75,因此可以使用的阈值为145。图4是四副在不同的光照条件下抓取的图像以及根据上述基于直方图技术阈值处理后的效果。尽管私服图像有这较广的光照范围(可以从直方图中看出),该算法都选择了较为合适的阈值,而阈值处理后的图像基本一样。




图 4
这个基于直方图的全局阈值技术对于如上面所举的那些光线条件均匀或那些光线变化不多的部分图像处理的很好。但是对于在正常办公室光照条件下他无法获得满意的结果。因为对整个图像使用一个相同的阈值,图像的部分区域变得太白而其他地区又太黑。因此大部分文字变得不可读,如图5所示。

图 5
从光照不均匀的纸张图像中产生较好的二值化图像需要一种自适应的阈值算法。这个技术根据每个像素的背景亮度来改变阈值。下面的讨论都配以图5先显示新算法的效果。这是一个具有挑战性的测试,因为图像边缘有光源,并且其在白色背景上有黑色文字(PaperWorks整个词,以及黑色背景中的白色文字(“XEROX”),还有白色背景中的灰色文字(”The best way。。。”)还有不同的阴影和一个在单词“PaperWorks”下很细小的水平黑色线。
三 自适应阈值
一个理想的自适应阈值算法应该能够对光照不均匀的图像产生类似上述全局阈值算法对光照均匀图像产生的效果一样好。 为了补偿或多或少的照明,每个像素的亮度需要正规化,之后才能决定某个像素时黑色还是白色。问题是如何决定每个点的背景亮度。一个简单的方式就是在拍摄需要二值图片之前先拍一张空白的页面。这个空白的页面可以当做参考图像。对于每一个要处理的像素,在处理前对应的参考图像像素都将从其中减去。
只要在参考图像和实际要处理的图像拍摄时光照条件没有发生任何变化,这个方法能产生非常好的效果,但是,光照条件会收到人、台灯或其他移动物体的影子的影响。如果房间有窗户,那么光照条件还会随着时间变化而改变。一个解决方案就是在同样的位置,同样的时刻拍摄一种空白的页面作为参考,但是这如果使用扫描仪一样不太方便
另外一种方式就是通过一些关于图像实际该是什么样的假设来估计每个像素的背景亮度。例如,我们可以假设,图像大部分是背景(也就是白色),黑色只占图像的小部分。另外一个假设就是背景光改变相对较为缓慢。基于以上假设有很多算法都可行。由于没有关于自适应阈值的数学理论,因此,也就没有一个标准或者最优的方法来实现它。代替的是,有一些特别的方法要比另外一些更为使用的多。由于这些方法比较特别,因此测量他们的性能比较有用。为此,Haralick 和 Shapiro提出了以下建议:区域需和灰度调统一;区域内部应该简单,没有过多的小孔;相邻的区域应该有显著的不同值;每个部分的边缘也应该简单,不应凹凸不平,其空间上要准确。
根据Pratt的理论,对于图像二值化,还没有任何量化性能指标提出过。似乎主要评价算法性能的方式就是简单看看结果然后判断其是否很好。对于文字图像,有一个可行的量化办法:不同光照条件下的图片使用不同的二值化算法处理的后的结果被送往OCR系统,然后将OCR识别的结果和原文字比较。虽然该法可能有用,但是他不能用在以下描述的算法中,因为不可能给出一个看起来好的标准。对于一些交互式的应用,比如复制黏贴操作用户必须等到二值的处理。因此另外一个重要的指标就是速度。以下部分提出了不同的自适应阈值算法已经他们产生的结果。
四、基于Wall算法的自适应阈值
R. J. Wall开发的根据背景亮度动态计算阈值的算法描述可见《Castleman, K. Digital Image Processing. Prentice-Hall Signal Pro-cessing Series, 1979.》 。以下描述基本是按照其论文的。首先,将图像分成较小的块,然后分别计算每块的直方图。根据每个直方图的峰值,然后为每个块计算其阈值。然后,每个像素点的阈值根据相邻的块的阈值进行插值获得。图6是用该算法对图5进行处理的结果。

图 6
这个图像被分成9个块(3*3),每个块的阈值选择为比峰值低20%。这个结果比全局阈值要好,但是他的计算量大,速度交慢。另外一个问题就是,对于有些图像,局部的直方图可能会被大量的黑色或白色点欺骗,导致阈值在整幅图像中不是平滑的变化,结果可能非常糟糕,见图7.
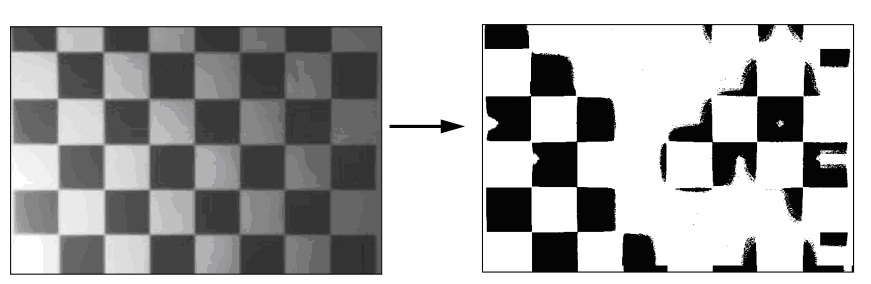
图 7
五、快速自适应阈值
文献中记载的大部分算法都比Wall算法更为复杂,因此需要更多的运行时间。开发一个简单的更快的自适应阈值算法是可行的,因此这接我们介绍下相关的理论。
算法基本的细想就是遍历图像,计算一个移动的平均值。如果某个像素明显的低于这个平均值,则设置为黑色,否则设置为白色。仅需一个遍历就够了,用硬件去实现算法也很简答。注意到下面的算法和IBM 1968年用硬件实现的算法的相似性是比较有趣的。
假设Pn为图像中位于点n处的像素。此刻我们假设图像是由所有行按顺序连接起来的一个单行。这这导致了在每行开始的时候会产生一些异常,但这个异常要比每行都从零开始要小。

假设fs(n)是点n处最后 s个像素的总和:
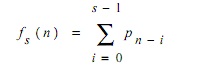
最后的图像T(n)是1(黑色)或0(白色)则依赖于其是否比其前s个像素的平均值的百分之t的暗。
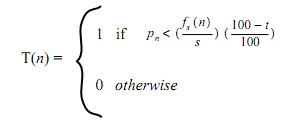
对于s使用图像的1/8宽而t取值15似乎对不同的图像都能产生较好的效果。图8显示了使用该算法从左到右扫描行的结果。


图 8 图 9
图9是使用相同算法从右到左处理的结果,注意在这个图像中,最左侧的较小的文字是不完整的。在字符PaperWorks中也有更多的孔洞。同样,最右侧的黑色边缘也窄很多。这主要是由于图像的背景光源是从左到右逐渐变黑的。
另外一个问题就是如何开始算法,或者说怎么计算g(0)。一个可能性是使用s*p0,但是由于边缘的结果,P0不是一个典型的值。因此另外一个可行是127*s(基于8位图像的中值)。不论如何,这两种方案都只会影响到g的很少一部分值。在计算gs(n)时,g(0)的权重是:

因此如果s=10,那么对于任何的n>6,g(0)的贡献则少于g10(n)的10%,对于n>22,g(0)的贡献值则少于1%。对于s=100,在8个像素之后g(0)的共享就小于10%,在68像素后则少于1%.
如果计算均值时不是从某一个方向效果应该会更好,图12显示使用另外一种方法来计算平均值的效果。该方法通过计算点n对称两侧的像素的平均值来代替某一个方向的平均值。此时f(n)的定义如下:

另外一种替代的方法就是交替的从左到右及从右到左计算平均值,如下所示:
这产生的效果和中心平均相比,没有多大的区别。
一个小小的修改可能会对大部分图像产生更好的效果,那就是保留前一行的平均效果(和当前行反方向的),然后把当前行的平均值和上一上的平均值再取平均作为新的平均值,即使用:

这使得阈值的计算考虑了垂直方向上的信息,产生的结果如图:

请注意他对字符的分割的效果。这也是为数不多的保留了PaperWorks下那条水平线的算法之一。
部分原文因现在看来已经不合理了,未做翻译。
从上面的东西来看,Wellner 自适应滤波阈值实际上就是对像素做指定半径的一维平滑,然后原像素和平滑后的值做比较来决定黑还是白。文章中很大一部分篇幅都是在讨论取样的那些像素的方向问题,是完全在左侧、完全在右侧还是左右对称,抑或是考虑到前一行的效果。 但是,总的来看,他只考虑到了行方向上的像素对平滑的影响。之后,Derek Bradley和Gerhard Roth 在他们的论文Adaptive Thresholding Using the Integral Image 中 提出了以W*W为模板的矩形区域的二维平滑值来代替一维加权值。从而抛开了一维平滑的方向性问题。
当然,对于二维平滑他们提出了0(1)时间复杂度的算法,其实很简单,就是先计算整幅图像的累加表。然后再一次循环通过加单的加减获得以某个像素为中心的累加值。
下面给出一个简答的从左到右的原始的Wellner算法的代码(我认为那个所有行并成一行并不会好,并且如果那样做还要考虑扫描行的无效数据):
public static void WellneradaptiveThreshold1(FastBitmap bmp, int Radius = 5, int Threshold = 15)
{
if (bmp == null) throw new ArgumentNullException();
if (bmp.Handle == IntPtr.Zero) throw new ArgumentNullException();
if (bmp.IsGrayBitmap() == false) throw new ArgumentException("Binaryzation functions can only be applied to 8bpp graymode Image.");
if (Radius < 0 || Radius > 255) throw new ArgumentOutOfRangeException();
if (Threshold < 0 || Threshold > 100) throw new ArgumentOutOfRangeException();
int Width, Height, Stride, X, Y;
int Sum, InvertThreshold, XX, OldValue;
byte* Pointer;
Width = bmp.Width; Height = bmp.Height; Stride = bmp.Stride; Pointer = bmp.Pointer; InvertThreshold = 100 - Threshold;
byte* Row = (byte*)Marshal.AllocHGlobal(Width);
for (Y = 0; Y < Height; Y++)
{
Pointer = bmp.Pointer + Stride * Y;
Sum = *Pointer * Radius;
Win32Api.CopyMemory(Row, Pointer, Width);
for (X = 0; X < Width; X++)
{
XX = X - Radius;
if (XX < 0) XX = 0;
Sum += Row[X] - Row[XX];
if (Row[X] * 100 * Radius < Sum * InvertThreshold)
Pointer[X] = 0;
else
Pointer[X] = 255;
}
}
Marshal.FreeHGlobal((IntPtr)Row);
}
这个是基于我自己的一个FastBitmap类的,要改成GDI+的 Bitmap 类也很简单,注意二值处理一般只针对灰度图像。
操作中必须先对于行数据进行一个备份,因为在计算过程中会改变像素值的。
同时也给出二维的Wellner算法的代码供大家参考:
public static void WellneradaptiveThreshold2(FastBitmap bmp, int Radius = 5, int Threshold = 50)
{
if (bmp == null) throw new ArgumentNullException();
if (bmp.Handle == IntPtr.Zero) throw new ArgumentNullException();
if (bmp.IsGrayBitmap() == false) throw new ArgumentException("Binaryzation functions can only be applied to 8bpp graymode Image.");
if (Radius < 0 || Radius > 255) throw new ArgumentOutOfRangeException();
if (Threshold < 0 || Threshold > 100) throw new ArgumentOutOfRangeException();
int Width, Height, Stride, X, Y;
int Sum, X1, X2, Y1, Y2, Y2Y1, InvertThreshold;
byte* Pointer;
Width = bmp.Width; Height = bmp.Height; Stride = bmp.Stride; Pointer = bmp.Pointer; InvertThreshold = 100 - Threshold;
int* Integral = (int*)Marshal.AllocHGlobal(Width * Height * 4);
int* IndexOne, IndexTwo;
for (Y = 0; Y < Height; Y++)
{
Sum = 0;
Pointer = bmp.Pointer + Stride * Y;
IndexOne = Integral + Width * Y;
for (X = 0; X < Width; X++)
{
Sum += *Pointer;
if (Y == 0)
*IndexOne = Sum;
else
*IndexOne = *(IndexOne - Width) + Sum;
IndexOne++;
Pointer++;
}
}
for (Y = 0; Y < Height; Y++)
{
Pointer = bmp.Pointer + Stride * Y;
Y1 = Y - Radius; Y2 = Y + Radius;
if (Y1 < 0) Y1 = 0;
if (Y2 >= Height) Y2 = Height - 1;
IndexOne = Integral + Y1 * Width;
IndexTwo = Integral + Y2 * Width;
Y2Y1 = (Y2 - Y1) * 100;
for (X = 0; X < Width; X++)
{
X1 = X - Radius; X2 = X + Radius;
if (X1 < 0) X1 = 0;
if (X2 >= Width) X2 = Width - 1;
Sum = *(IndexTwo + X2) - *(IndexOne + X2) - *(IndexTwo + X1) + *(IndexOne + X1);
if (*Pointer * (X2 - X1) * Y2Y1 < Sum * InvertThreshold)
*Pointer = 0;
else
*Pointer = 255;
Pointer++;
}
}
Marshal.FreeHGlobal((IntPtr)Integral);
}
其中if (*Pointer * (X2 - X1) * Y2Y1 < Sum * InvertThreshold) 是为了避免耗时的除操作,提高程序速度。
其实,上述计算平均值的方式并不是最快的,有能达到其2倍以上速度的代码。 并且上述算法还存在一个问题,就是对于稍微大一点的图像,累加的过程会超出int所能表达的范围,从而使得结果不正确,当然,在C#中,我们可以使用long类型来保存结果,但是这造成2个后果:一是程序占用内存更大,二十对于现在大部分的32位操作系统,long所代表的64位数的计算速度比32位要慢不少。当然对于64位就不同了。
关于论文中的贴的效果,似乎按照他的算法的参数是达不到的,不知道是不是因为我们的原始图片是从其论文中截图得到而有降质的原因。
总的而言,这种基于局部特征的二值,在不少情况下比全局阈值的一刀切的效果要好些,对于Wellner来说,搜索的半径的大小对于结果的影响还是很大的,不过也不一定。比如Lena这个美女图:



原图 大律法 S=50,T=15的效果。