在大部分分布式应用中,为了提高系统的效率,都会引入缓存,例如使用Redis。与此同时,也会带来缓存与数据库数据不一致的问题。
如果对数据一致性要求不是很高的场景,我们正常的操作是,客户端先去缓存查询,如果查询不到再去数据中查找,数据库查询到以后,
再在缓存中放一份,最后返回给客户端。这样把大多数的请求落在缓存上,减少数据库的查询操作。
如果是做数据增删改的操作,一般也是有两种情况。
1.先写缓存,再写数据库;
2.先写数据库,再写缓存。
| 场景 | 描述 | 解决 |
|---|---|---|
| 先写缓存再写数据库,缓存成功,数据库失败 | 缓存写成功,但如果数据库写失败或延迟,则下次高并发读取缓存时,出现脏数据 | 不推荐这种方式,应该先写数据库,把旧的缓存值设置无效。读取数据时,缓存不存在,先读数据库再更新缓存 |
| 先写数据库,再写缓存,数据库写成功,缓存写失败 | 数据库写成功,缓存写失败,下次高并发读取缓存时,读不到数据 | 使用缓存时,如果都缓存失败,先读数据库,再写缓存的方式 |
第一种方式是错误的,所以大部分使用第二种场景。
当然这里存在缓存穿透,缓存雪崩,缓存击穿等情况,在这里不做详细解释。
这里举了例子,苹果官网预售Apple 12 Pro Max,库存是200W,然后果粉们准备去抢购,那么这里会存在以下情况:
- 数据库扣减库存成功了,但是更新缓存失败。例如,数据库里已经剩余100W,但缓存里还有150W,缓存库存大于数据库剩余库存。
这种请求如何解决?其实可以在扣减库存前,先去查询剩余数量,如果数量不足,则返回失败。 - 如果数据库扣减失败了,但缓存里的缓存却更新了,也就是说缓存中库存数量小于数据库里的数量,那么就存在部分剩余库存无法卖出的问题。
当然这种情况很难发生,因为数据库的读操作是远远快于写操作的。
但是,如果要保证数据库与缓存强一致性该如何设计?
这里可以考虑另一种思路,也就是使用MySQL的binlog。
流程图是这样的:
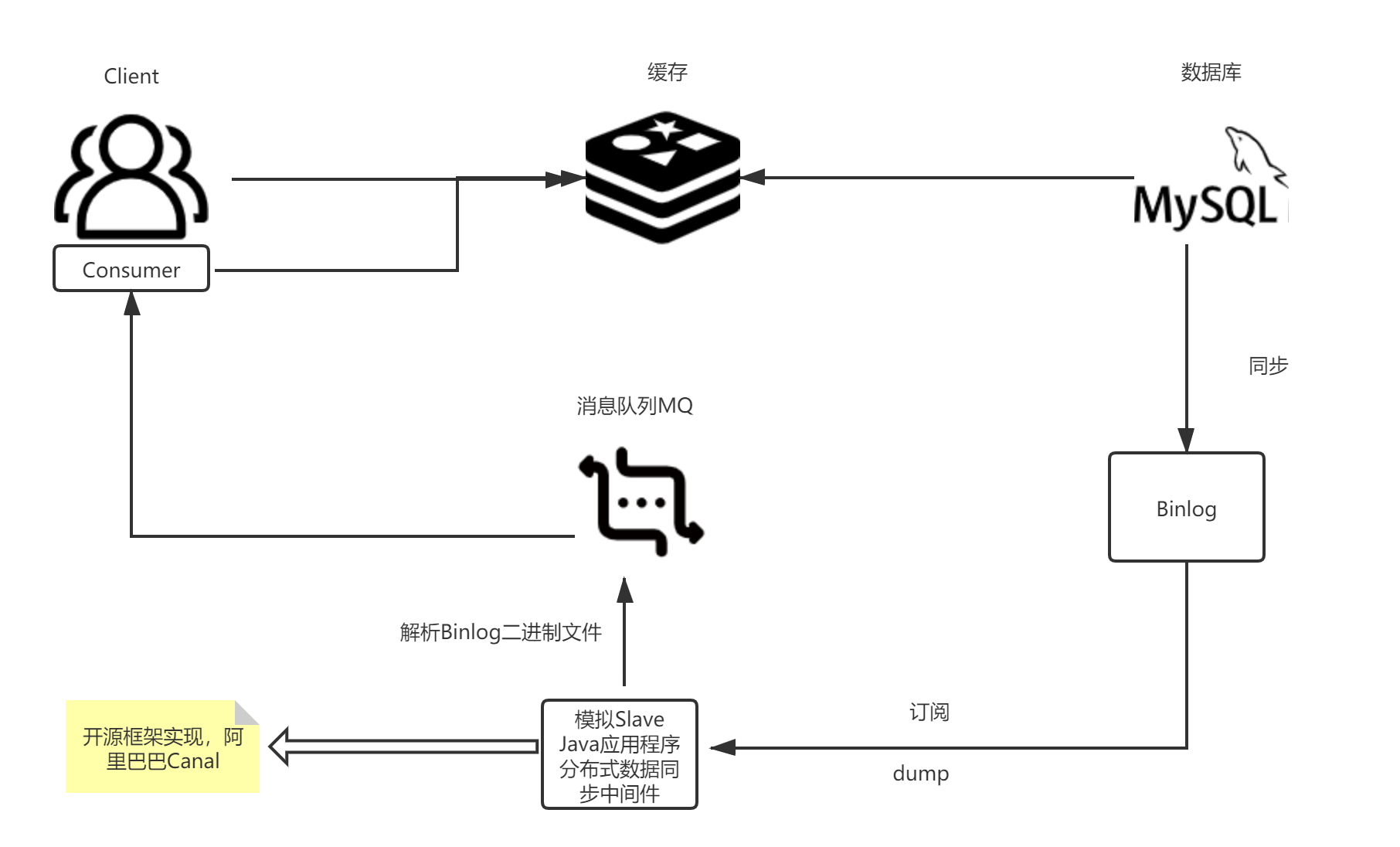
这里说一下流程:
1.客户端从缓存中读取;
2.如果有变更操作,更新数据库;
3.数据库事务提交以后写入binlog;
4.我们自己写一个Java应用程序,把自己模拟成一个MySQL的slave,去订阅MySQL的数据库的binlog,MySQL会把binlog dump给我们应用程序;
5.因为binlog是二进制文件,这里需要解析,处理insert、update、delete这些操作。
6.解析完以后,把这些数据丢到消息队列里。这里的消息队列有两个用处,第一是做持久化消息,第二是重试机制;
7.客户端消费消息队列的消息,然后推到缓存中,如果没有成功,进行重试。
8.更新缓存完毕。