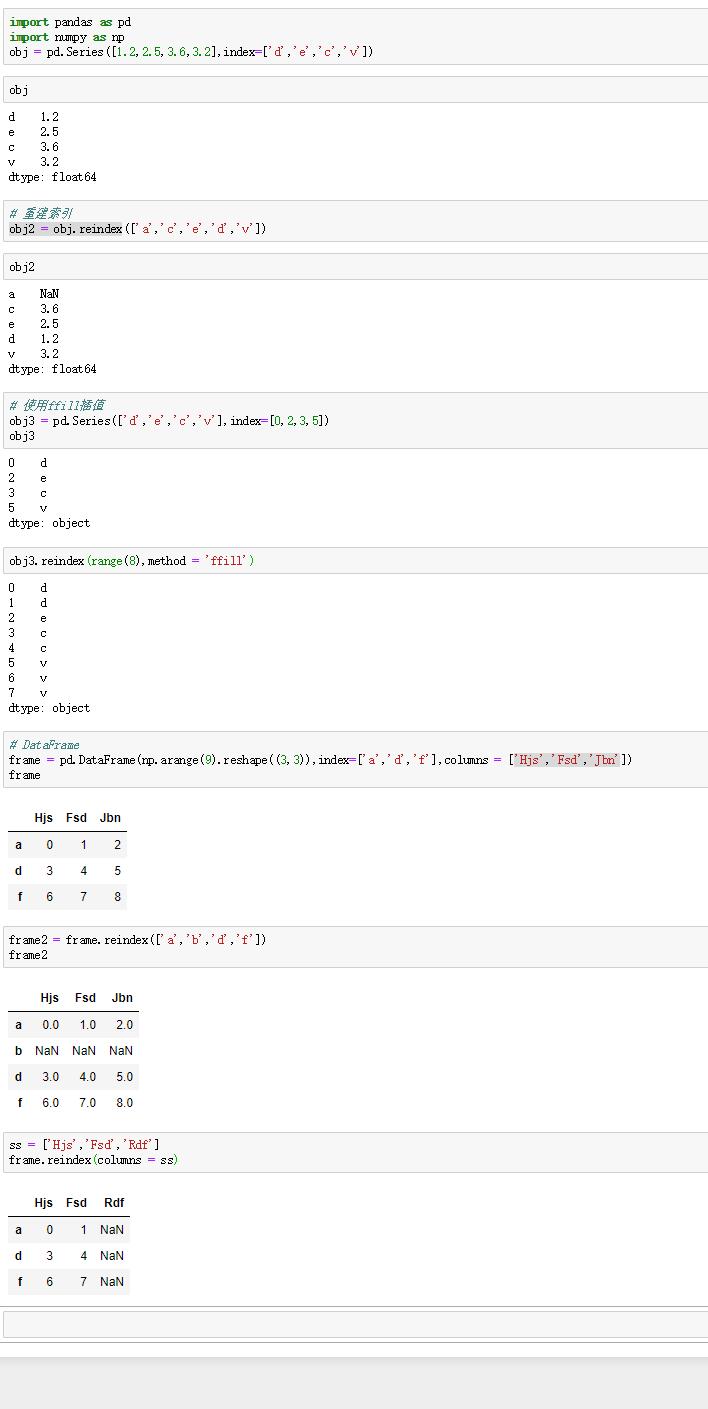
下面介绍pandas常见的基本功能,和python的基本数据类型进行比较可以看到pandas在操作大型数据集中的优势。
1.重建索引
(1)函数:reindex
(2)作用:创建一个符合新索引的新对象。
(3)内容:
Series调用reindex方法时,会将数组按照新的索引进行排列,如果之前并不存在,则会引入缺失值NaN。
DataFrame调用reindex方法时,会改变行和列索引。只传入一个序列时,行会重建索引;传入columns关键字参数时,列会重建索引。
(4)重要参数:ffill
作用:重建索引时插值,按顺序把没有数据的标签补充数据。
(5)实例
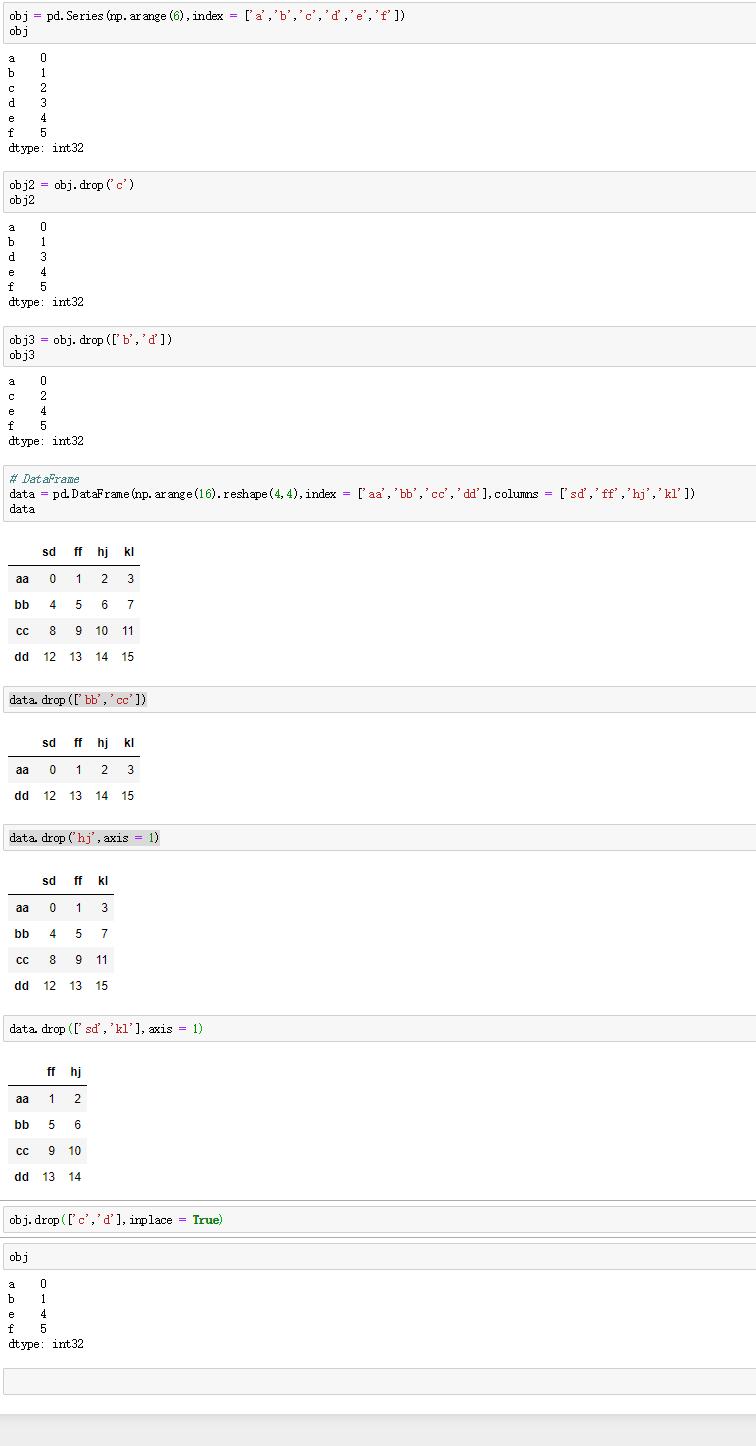
2.轴向上删除条目
(1)函数:drop
(2)作用:在轴向上删除一个或更多的条目。
(3)内容:
返回一个含有指示值或轴向上删除值的新对象。
Series调用drop方法时,把字符串或者字符串序列列表当作参数传入并返回对象。
DataFrame调用drop方法时,传入字符串序列列表会根据行标签删除值(轴0),传入axis=1或者axis='columns'会根据列标签删除值。
(4)重要参数:inplace
作用:清除被删除的数据,并返回删除后的数据。
(5)实例
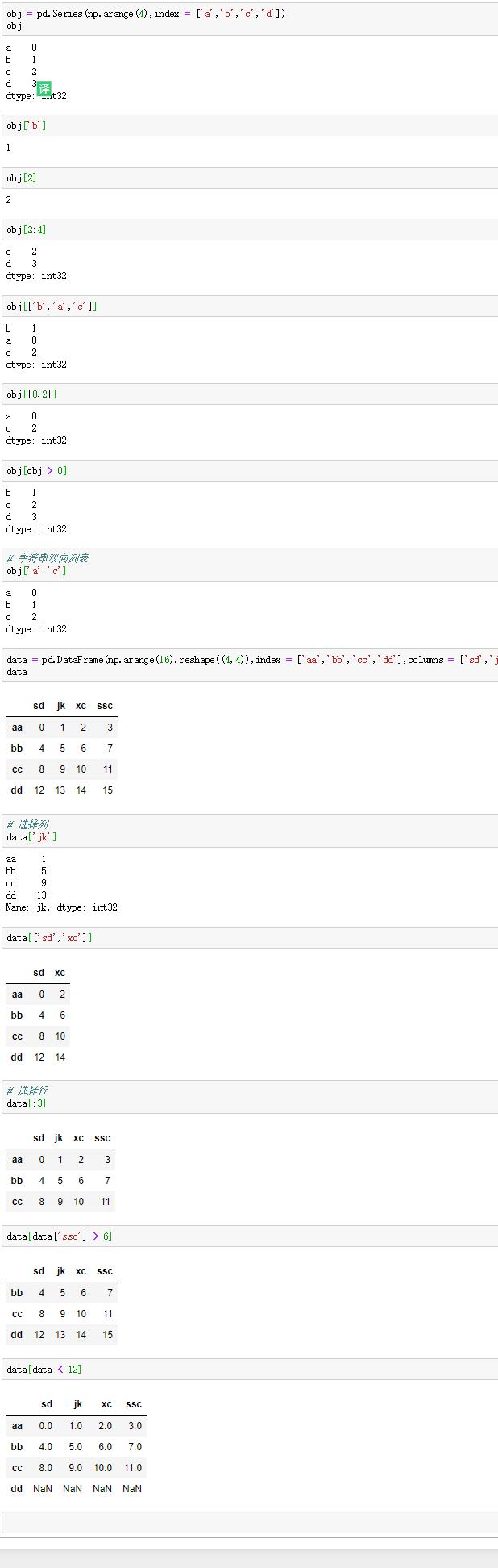
3.索引,选择与过滤
(1)索引
Series的索引可以不只是整数,也可以是小数,字符串,切片,字符串索引列表,布尔值索引。还可以是字符串双向切片。
DataFrame的索引可以是字符串,字符串索引列表选择列,切片和布尔值索引选择行。