[TOC]
下面继续讲解pandas的第二个工具DataFrame。
二:pandas数据结构介绍
2.DataFarme
DataFarme表示的是矩阵的数据表,包含已排序的列集合,是一个二维数据工具。每一列可以是不同的数据类型值。它既有行索引又有列索引,可以看作是一组共享相同索引的Series对象。DataFarme的数组方法有很多,比如用index.name获取某列的值,用values获取行的值。这里先介绍一些常用的知识。
(1)构建DataFrame
有多种方式可以构建DataFrame,其中最常用的方式是利用包含等长度列表或NumPy数组的字典形成DataFrame:
# 下面是采用NumPy的字典的方式来进行构建DataFrame
data = {'a':[1,2,3,4],'b':[1.0,2.0,3.0,4.0],'c':['a','b','c','d']}
frame = pd.DataFarme(data)
结果如下:

产生的DataFrame的行索引会自动分配,列索引为字典的每个键。
(2)head
对于大型的矩阵数据,head方法将会只选出头部的五行:

(3)指定列
如果指定了列,则会按照指定顺序排列,用columns属性,但是在数组字典中一定要存在该列的标签名,如果没有则在结果中出现缺失值:

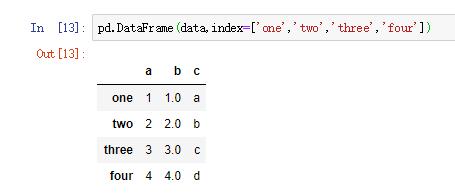
(4)指定行
同样的,也可以指定行,用index属性。
(5)获取属性
获取属性可以用index获取行,用columns获取列。

(6)获取列内容
获取DataFrame列的值,可以像字典型标记或属性那样检索Series:

frame[column]对于任意列名均有效,而frame.column只在列名是有效的Python变量名时有效。
(6)获取行内容
获取DataFrame行的值,可以通过位置或者特殊属性loc进行选取:

(7)赋值
将列表或者数组赋值给一个列时,值的长度必须和DataFrame的长度相匹配,并按照索引进行排序,在空缺的地方填充缺失值。
如果被赋值的列不存在,会产生新列, 但是要注意的是要用frame['']语法复制,用frame.(列名)的语法无法创建新的列。
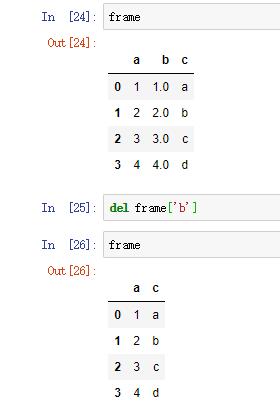
(8)删除列
del方法可以用于移除之前新建的列,这里删除的是对应数据的视图,会表现到原数组,如果需要复制,应该显式地使用copy方法。
(9)嵌套字典
如果嵌套字典被赋值给DataFrame,pandas会将字典的键作为列,将内部字典的键作为行索引。
(10)转置
这里可以用T属性获取该对象的转置:

在pandas中,可以用pd.Index()构造索引对象。