在面试的时候经常稳的JVM调优问题
- 线上环境,如果内存飙升了,应该怎么排查呢?
- 线上环境,如果CPU飙升了,应该怎么排查呢?
内存飙升首先要考虑是不是类有很多,并且没有被释放;使用jmap可以检查出哪个类很多
CPU飙升,可以使用Jstact 来找出CPU飙升的原因
下面就来研究Jmap,Jstact的用法。
目标:
- Jmap、Jstack、Jinfo详解
- JvisualVm调优工具实战
- JVM内存或CPU飙高如何定位
- JState命令预估JVM运行情况
- 系统频繁Full GC导致系统卡顿实战调优
- 内存泄漏到底是怎么回事?
一、前言
因为我的是mac电脑,所以运行程序都是在mac上,有时一些工具在mac上不是很好用。如果有不好用的情况,可以参考文章:
1. mac安装多版本jdk
2. 彻底解决Jmap在mac版本无法使用的问题
以上是我在mac上运行Jmap时遇到的问题,如果你也遇到了,可以查看。
二、Jmap使用
1. Jmap -histo 进程号
这个命令是用来查看系统内存使用情况的,实例个数,以及占用内存。
命令:
jmap -histo 3241
运行结果:
num #instances #bytes class name
----------------------------------------------
1: 1101980 372161752 [B
2: 551394 186807240 [Ljava.lang.Object;
3: 1235341 181685128 [C
4: 76692 170306096 [I
5: 459168 14693376 java.util.concurrent.locks.AbstractQueuedSynchronizer$Node
6: 543699 13048776 java.lang.String
7: 497636 11943264 java.util.ArrayList
8: 124271 10935848 java.lang.reflect.Method
9: 348582 7057632 [Ljava.lang.Class;
10: 186244 5959808 java.util.concurrent.ConcurrentHashMap$Node
这里显示的是,byte类型的数组,有多少个实例,占用多大内存。
- num:序号
- instances:实例数量
- bytes:占用空间大小
- class name:类名称,[C is a char[],[S is a short[],[I is a int[],[B is a byte[],[[I is a int[][]
2. Jmap -heap 进程号
注意:Jmap命令在mac不太好用,具体参考前言部分。
windows或者linux上运行的命令是
Jmap -heap 进程号
mac上运行的命令是:(jdk8不能正常运行,jdk9以上可以)
jhsdb jmap --heap --pid 2139
执行结果
Attaching to process ID 2139, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 11.0.2+9
using thread-local object allocation.
Garbage-First (G1) GC with 8 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 2576351232 (2457.0MB)
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 1048576 (1.0MB)
Heap Usage:
G1 Heap:
regions = 4096
capacity = 4294967296 (4096.0MB)
used = 21654560 (20.651397705078125MB)
free = 4273312736 (4075.348602294922MB)
0.5041845142841339% used
G1 Young Generation:
Eden Space:
regions = 15
capacity = 52428800 (50.0MB)
used = 15728640 (15.0MB)
free = 36700160 (35.0MB)
30.0% used
Survivor Space:
regions = 5
capacity = 5242880 (5.0MB)
used = 5242880 (5.0MB)
free = 0 (0.0MB)
100.0% used
G1 Old Generation:
regions = 1
capacity = 210763776 (201.0MB)
used = 0 (0.0MB)
free = 210763776 (201.0MB)
0.0% used
通过上述结果分析,我们查询的内容如下:
- 进程号:2139
- JDK版本号:11
- 使用的垃圾收集器:G1(jdk11默认的)
- G1垃圾收集器线程数:8
- 还可以知道堆空间大小,已用大小,元数据空间大小等等。
- 新生代,老年代region的大小。容量,已用,空闲等。
3. Jmap -dump 导出堆信息
这个命令是导出堆信息,当我们线上有内存溢出的情况的时候,可以使用Jmap -dump导出堆内存信息。然后再导入可视化工具用jvisualvm进行分析。
导出命令
jmap -dump:file=a.dump 进程号
我们还可以设置内存溢出自动导出dump文件(内存很大的时候,可能会导不出来)
1. -XX:+HeapDumpOnOutOfMemoryError
2. -XX:HeapDumpPath=./ (路径)
下面有案例说明如何使用。
三、jvisualvm命令工具的使用
1. 基础用法
上面我们有导出dump堆信息到文件中,可以使用jvisualvm工具导入dump堆信息,进行分析。
打开jvisualvm工具命令:
jvisualvm
打开工具界面如下:

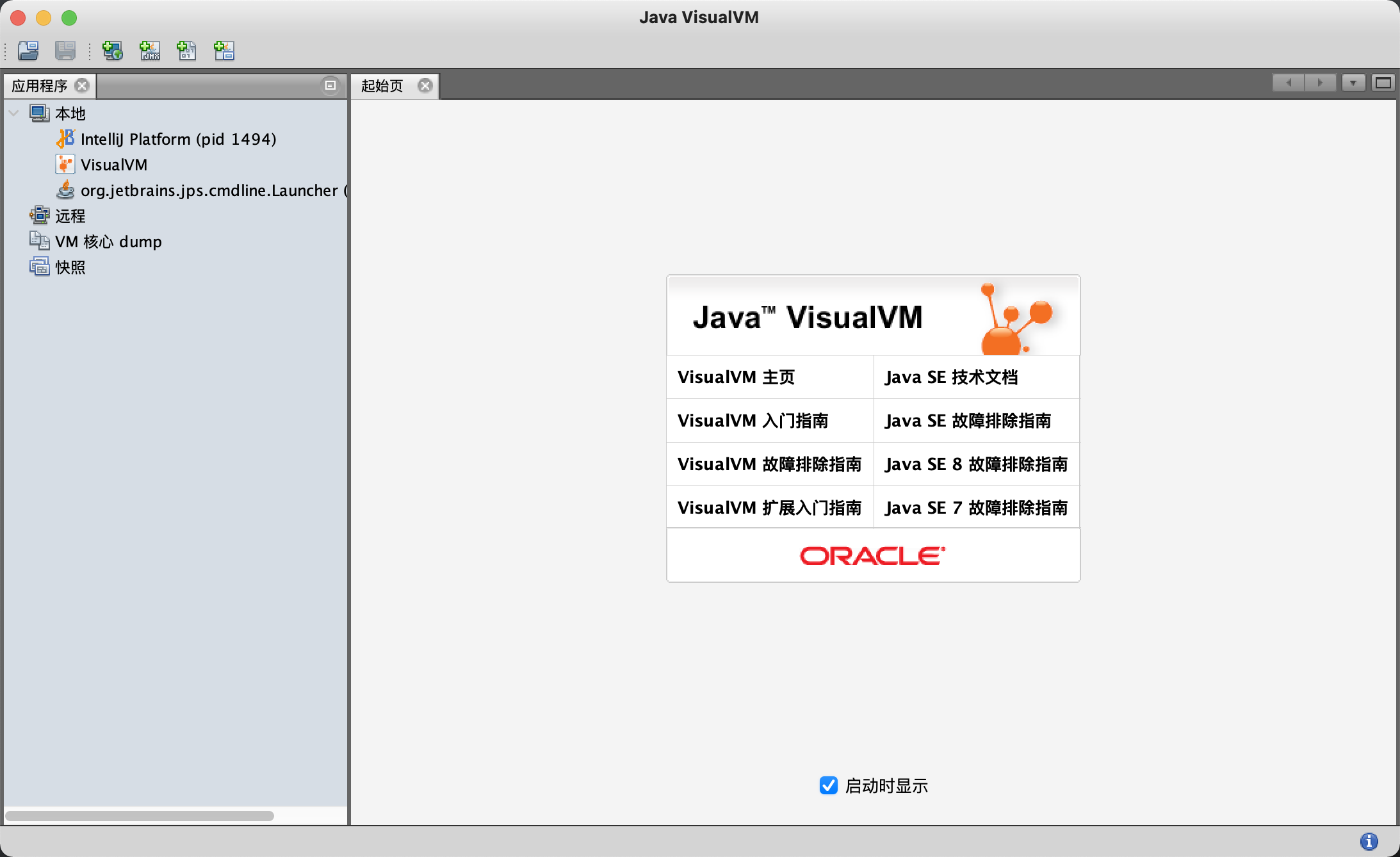
点击文件->装入,可以导入文件,查看系统的运行情况了。
2.案例分析 - 堆空间溢出问题定位
下面通过工具来分析内存溢出的原因。
第一步:自定义一段可能会内存溢出的代码,如下:
import com.aaa.jvm.User;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
@SpringBootApplicationpublic class JVMApplication {
public static void main(String[] args) {
List<Object> list = new ArrayList<>();
int i = 0;
int j = 0;
while (true) {
list.add(new User(i++, UUID.randomUUID().toString()));
new User(j--, UUID.randomUUID().toString());
}
}
}
第二步:配置参数
为了方便看到效果,所以我们会设置两组参数。
第一组:设置堆空间大小,将堆空间设置的小一些,可以更快查看内存溢出的效果
‐Xms10M ‐Xmx10M ‐XX:+PrintGCDetails
设置的堆内存空间是10M,并且打印GC
第二组:设置内存溢出自动导出dump文件(内存很大的时候,可能会导不出来)
1. -XX:+HeapDumpOnOutOfMemoryError
2. -XX:HeapDumpPath=./ (路径)
将这两组参数添加到项目启动配置中。
运行的过程中打印堆空间信息到文件中:
jmap -dump:file=a.dump,format=b 12152
后面我们可以使用工具导入堆文件进行分析(下面有说到)。
我们还可以设置内存溢出自动导出dump文件(内存很大的时候,可能会导不出来)
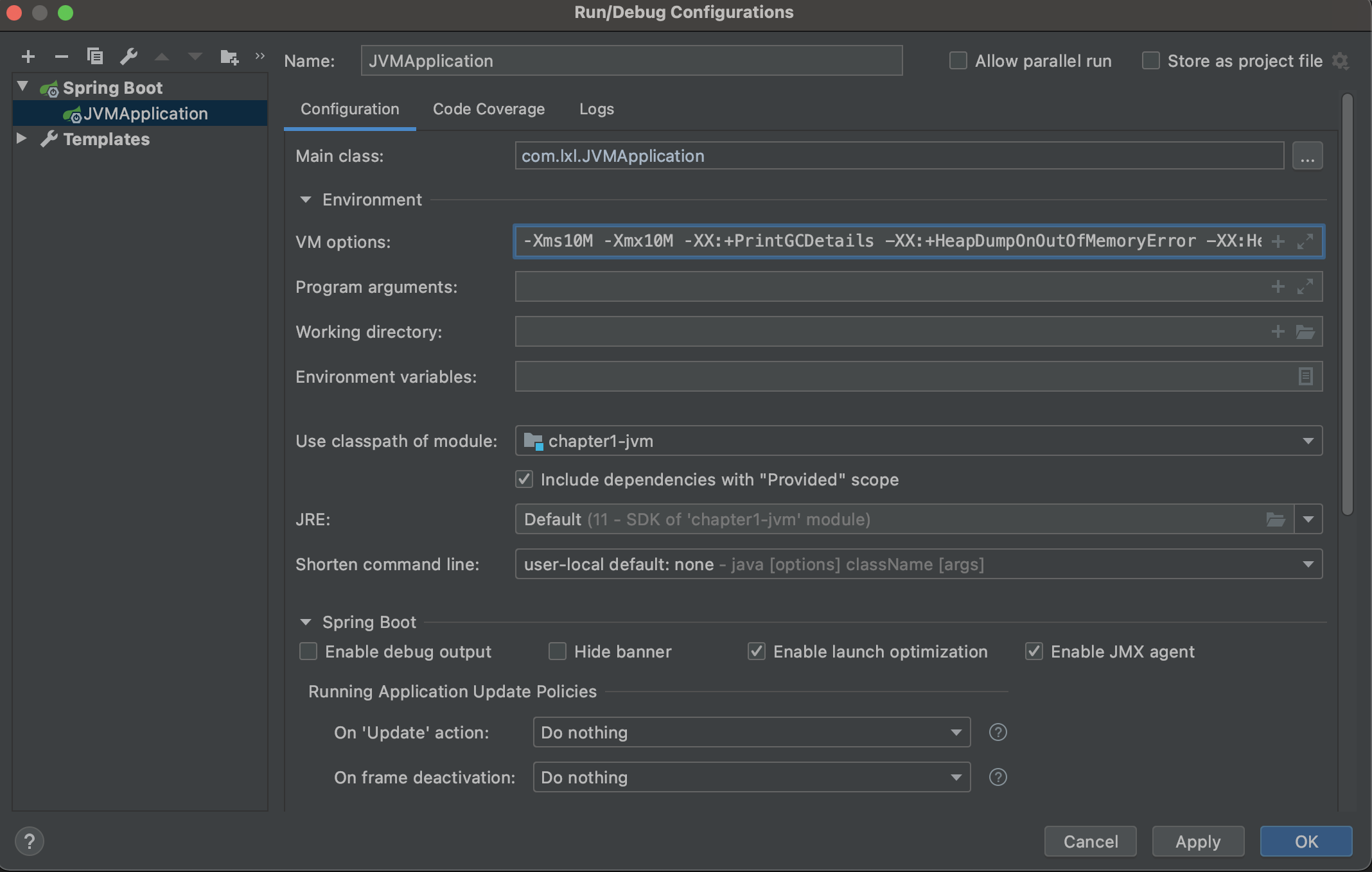
完整参数配置如下:
-Xms10M -Xmx10M -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/zhangsan/Downloads
-XX:+HeapDumpOnOutOfMemoryError 表示的是内存溢出的时候输出文件
-XX:HeapDumpPath=/Users/zhangsan/Downloads 表示的是内存溢出的时候输出文件的路径
这里需要注意的是堆目录要写绝对路径,不能写相对路径。
第三步:启动项目,等待内存溢出
我们看到,运行没有多长时间就内存溢出了。
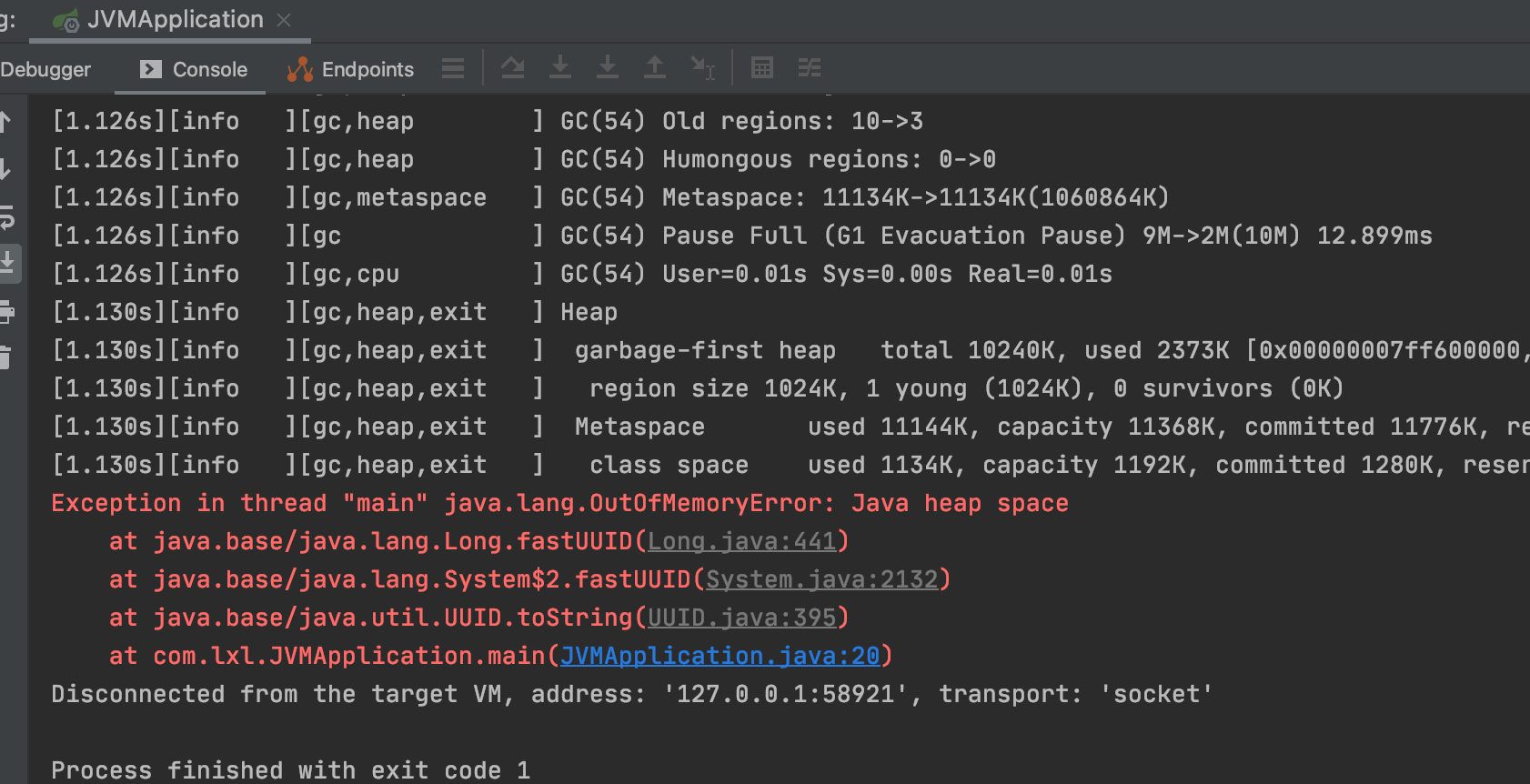
查看导出到文件的目录:
第四步:导入堆内存文件到jvisualvm工具
文件->装入->选择刚刚导出的文件
第五步:分析
我们主要看【类】这个模块。
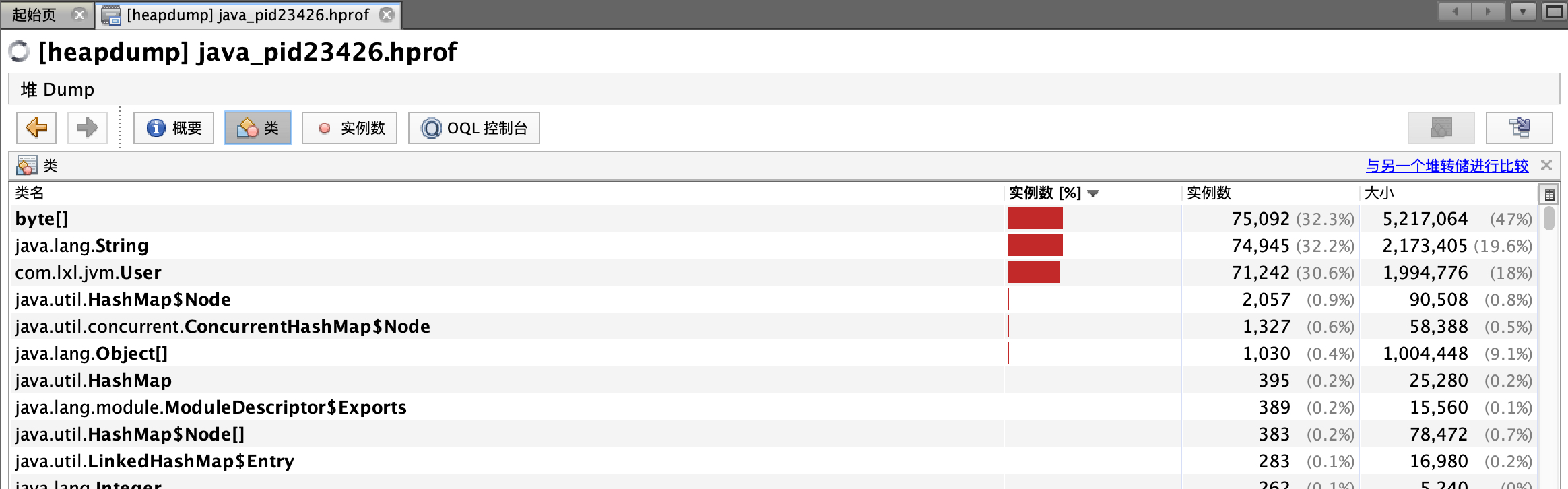
通过上图我们可以明确看出,有三个类实例数特别多,分别是:byte[],java.lang.String,com.lxl.jvm.User。前两个我们不容易看出是哪里的问题,但是第三个类com.lxl.jvm.User我们就看出来了,问题出在哪里。接下来就重点排查调用了这个类的地方,有没有出现内存没有释放的情况。
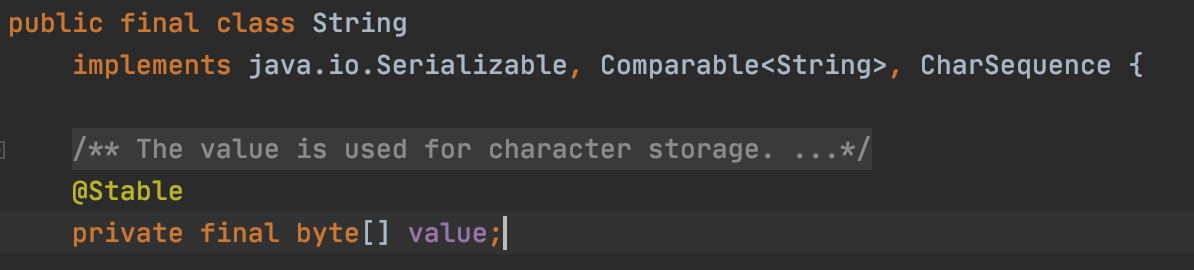
这个程序很简单,那么byte[]和java.lang.String到底是什么呢?我们的User对象结构中字段类型是String。
public class User {
private int id;
private String name;
}
既然有很多User,自然String也少不了。
那么byte[]是怎么回事呢?其实String类中有byte[]成员变量。所以也会有很多byte[]对象。
四、Jstack使用
Jstack可以用来查看堆栈使用情况,还可以查看进程死锁情况。
4.1 [Jstack 进程号] 进程死锁分析
1.执行命令:
Jstack 进程号
2. 死锁案例分析:
package com.lxl.jvm;
public class DeadLockTest {
private static Object lock1 = new Object();
private static Object lock2 = new Object();
public static void main(String[] args) {
new Thread(() -> {
synchronized (lock1) {
try {
System.out.println("thread1 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock2) {
System.out.println("thread1 end");
}
}
}).start();
new Thread(() -> {
synchronized (lock2) {
try {
System.out.println("thread2 begin");
Thread.sleep(5000);
} catch (InterruptedException e) {
}
synchronized (lock1) {
System.out.println("thread2 end");
}
}
}).start();
}
}
下面来分析一下这段代码:
- 定义了两个成员变量lock1,lock2
- main方法中定义了两个线程。
- 线程1内部使用的是同步执行--上锁,锁是lock1。休眠5秒钟之后,他要获取第二把锁,执行第二段代码。
- 线程2和线程1类似,锁相反。
- 问题:一开始,像个线程并行执行,线程一获取lock1,线程2获取lock2.然后线程1继续执行,当休眠5s后获取开启第二个同步执行,锁是lock2,但这时候很可能线程2还没有执行完,所以还没有释放lock2,于是等待。线程2刚开始获取了lock2锁,休眠五秒后要去获取lock1锁,这时lock1锁还没释放,于是等待。两个线程就处于相互等待中,造成死锁。
运行程序,通过Jstack命令来看看是否能检测到当前有死锁。
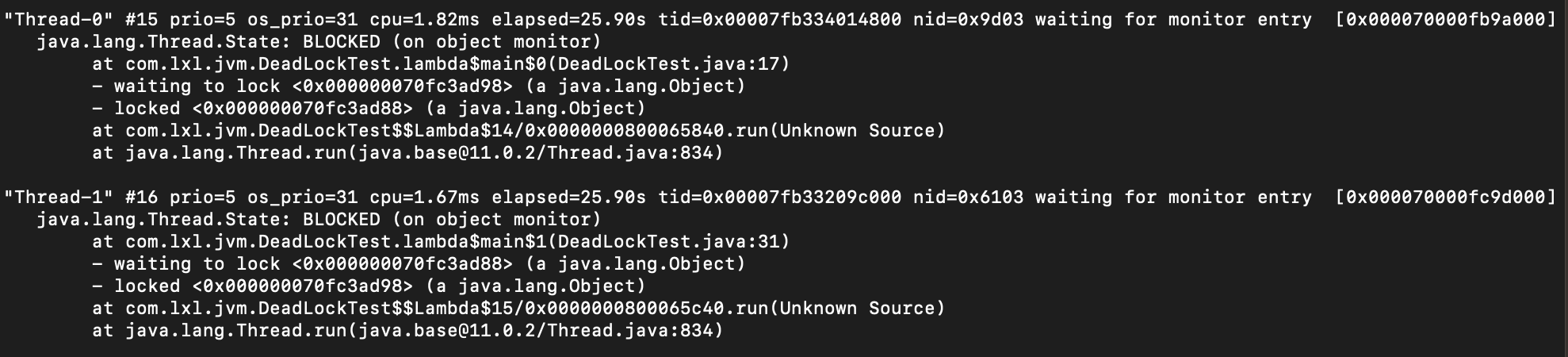
从这里面个异常可以看出,
- prio:当前线程的优先级
- cpu:cpu耗时
- os_prio:操作系统级别的优先级
- tid:线程id
- nid:系统内核的id
- state:当前的状态,BLOCKED,表示阻塞。通常正常的状态是Running我们看到Thread-0和Thread-1线程的状态都是BLOCKED.
通过上面的信息,我们判断出两个线程的状态都是BLOCKED,可能有点问题,然后继续往下看。
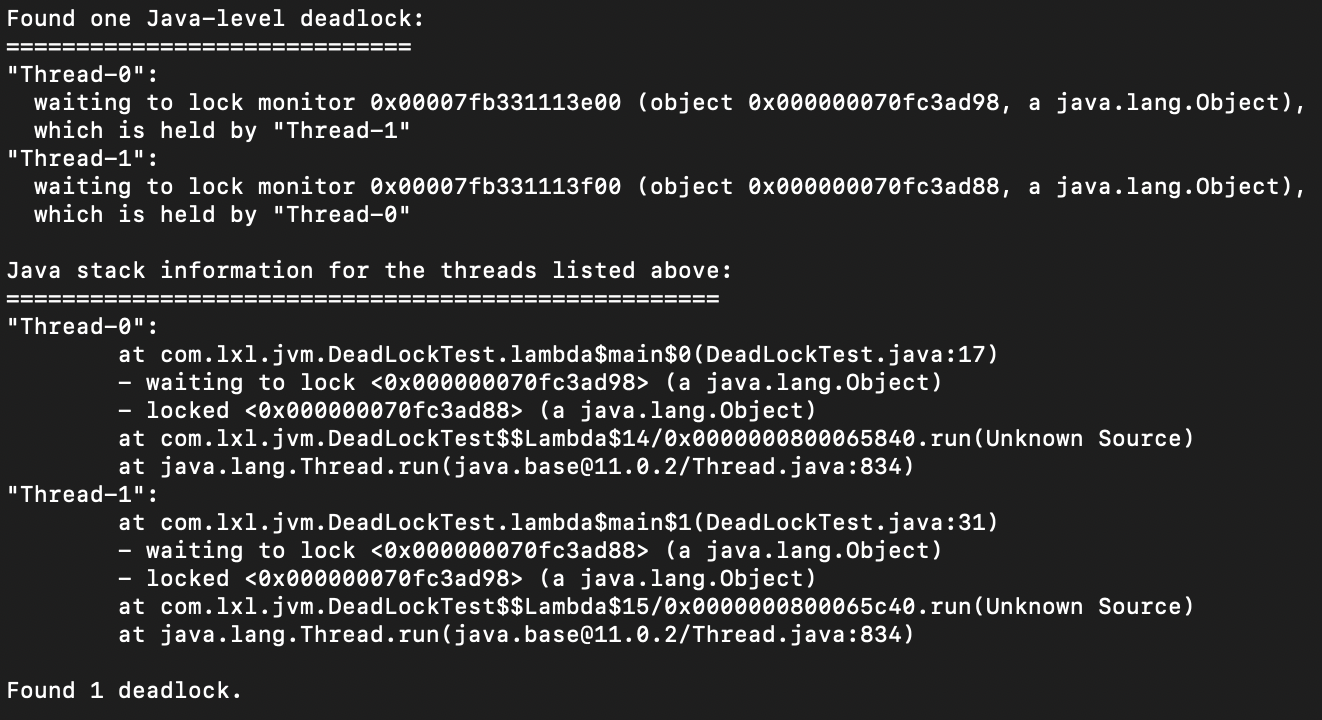
我们从最后的一段可以看到这句话:Found one Java-level deadlock; 意思是找到一个死锁。死锁的线程号是Thread-0,Thread-1。
Thread-0:正在等待0x000000070e706ef8对象的锁,这个对象现在被Thread-1持有。
Thread-1:正在等待0x000000070e705c98对象的锁,这个对象现在正在被Thread-0持有。
最下面展示的是死锁的堆栈信息。死锁可能发生在DeadLockTest的第17行和第31行。通过这个提示,我们就可以找出死锁在哪里了。
3. 使用jvisualvm查看死锁
在程序代码启动的过程中,打开jvisualvm工具。
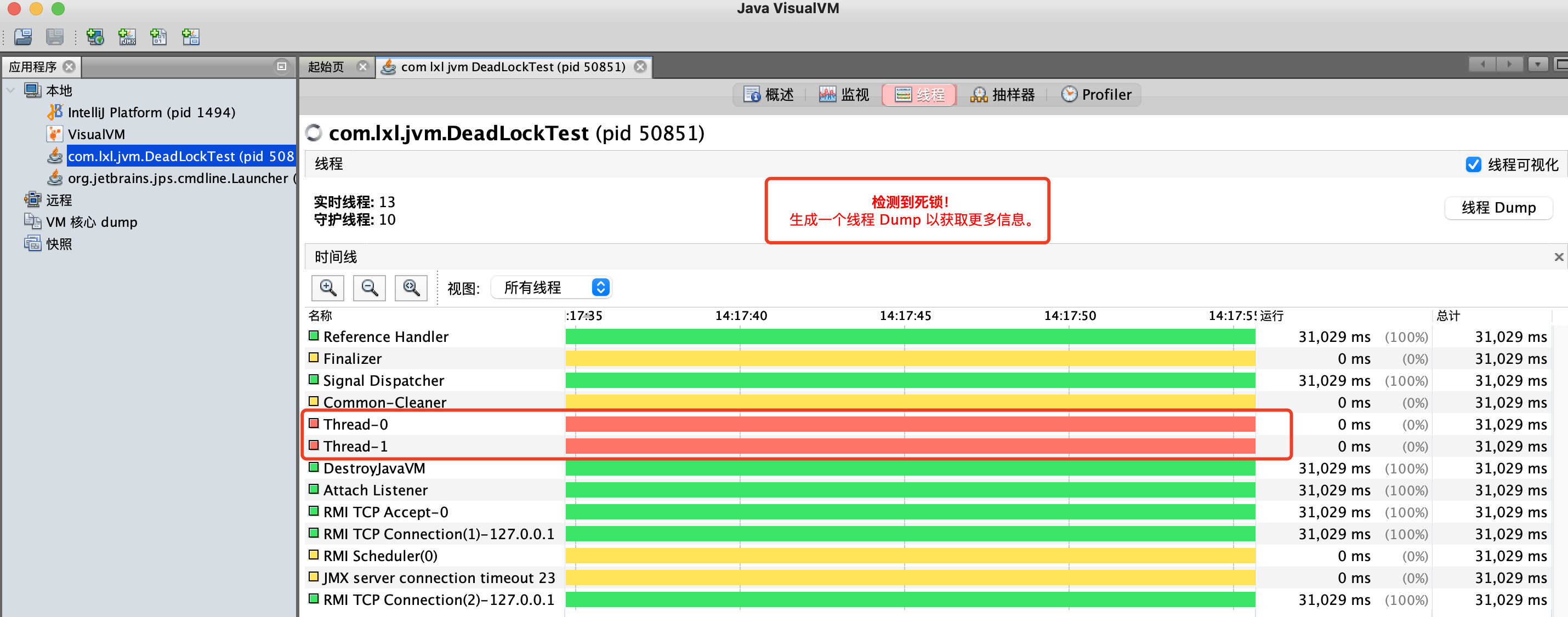
找到当前运行的类,查看线程,就会看到最头上的一排红字:检测到死锁。然后点击“线程Dump”按钮,查看相信的线程死锁的信息。
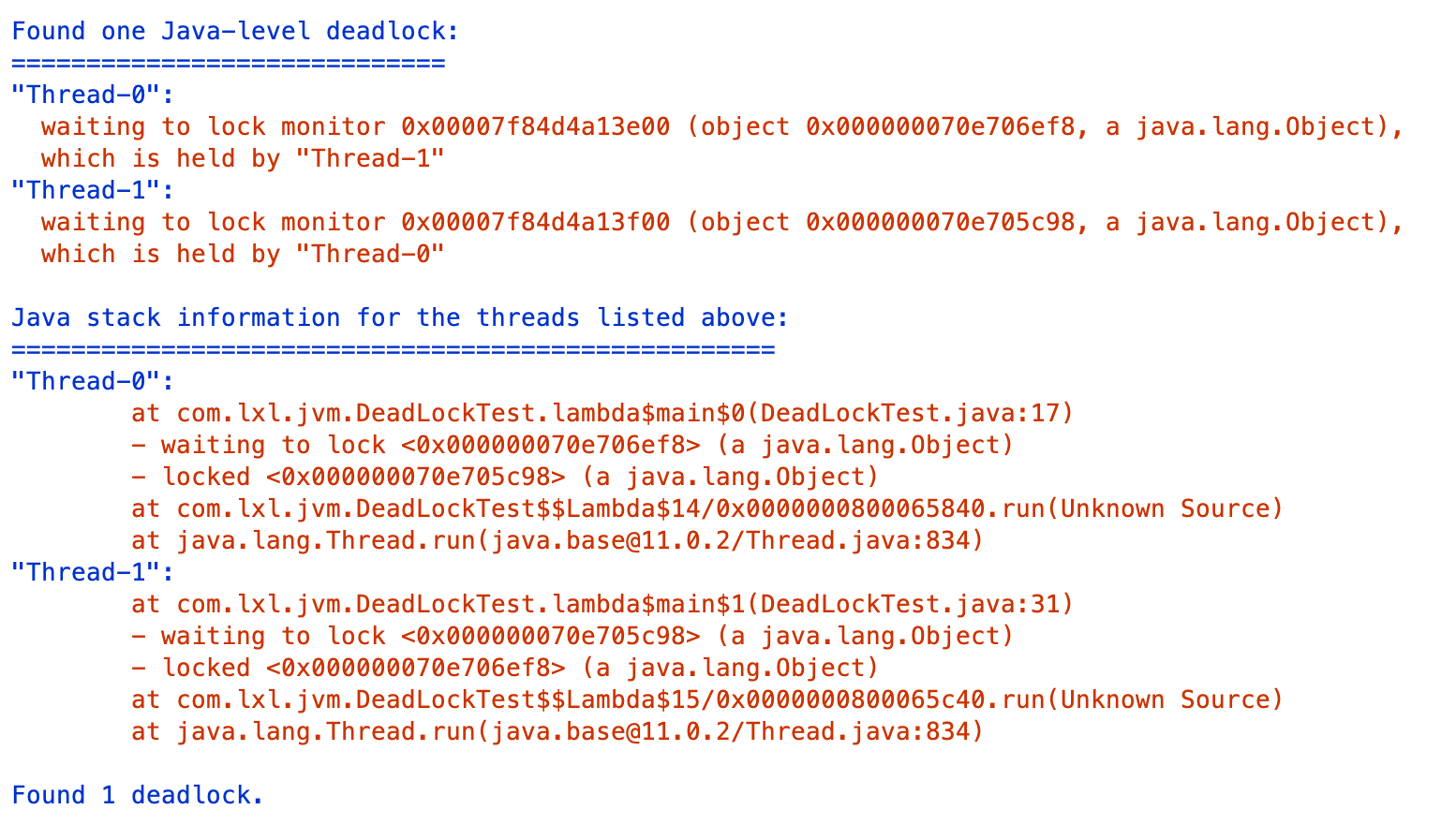
这里可以找到线程私锁的详细信息,具体内容和上面使用Jstack命令查询的结果一样,这里实用工具更加方便。
4.2 Jstack找出占用cpu最高的线程堆栈信息。
我们使用案例来说明如何查询cpu线程飙高的问题。
代码:
package com.lxl.jvm;
public class Math {
public static int initData = 666;
public static User user = new User();
public User user1;
public int compute() {
int a = 1;
int b = 2;
int c = (a + b) * 10;
return c;
}
public static void main(String[] args) {
Math math = new Math();
while(true){
math.compute();
}
}
}
这是一段死循环代码,会占满cpu。下面就运行这段代码,来看看如何排查cpu飙高的问题。
第一步:运行代码,使用top命令查看cpu占用情况
top
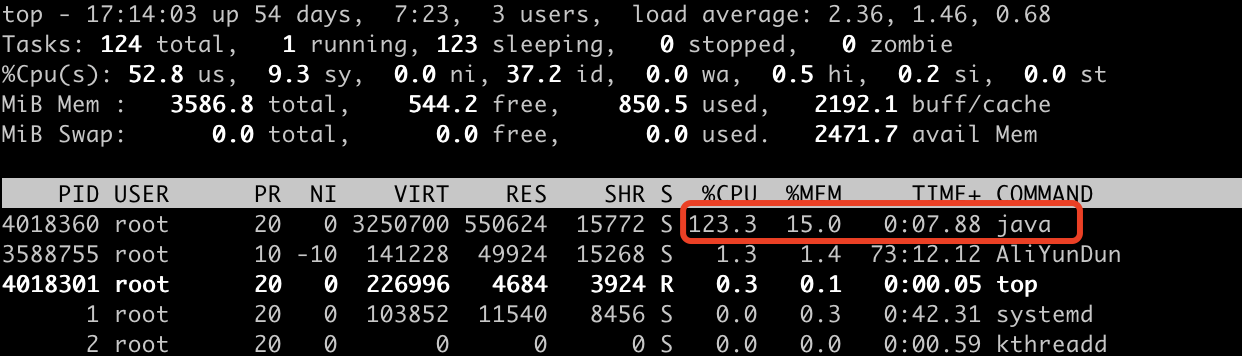
我们看到cpu严重飙高,一般cpu达到80%就会报警了
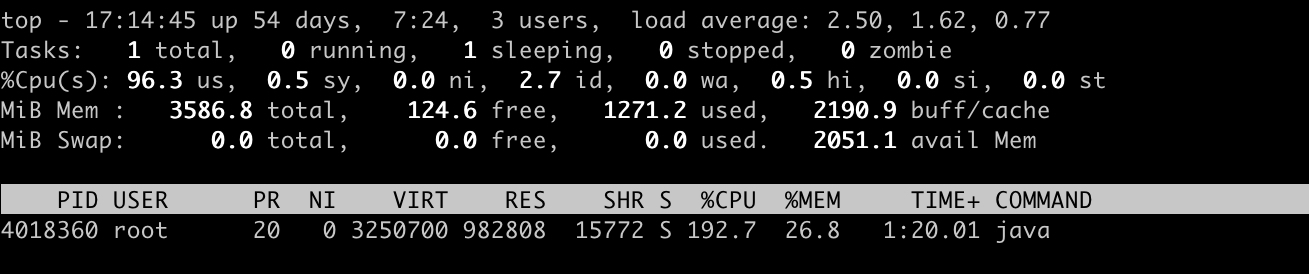
第二步:使用top -p 命令查看飙高进程
使用【top -p 进程号】 查看进程id的cpu占用情况
第三步:按H,获取每个线程的内存情况
需要注意的是,这里的H是大写的H。
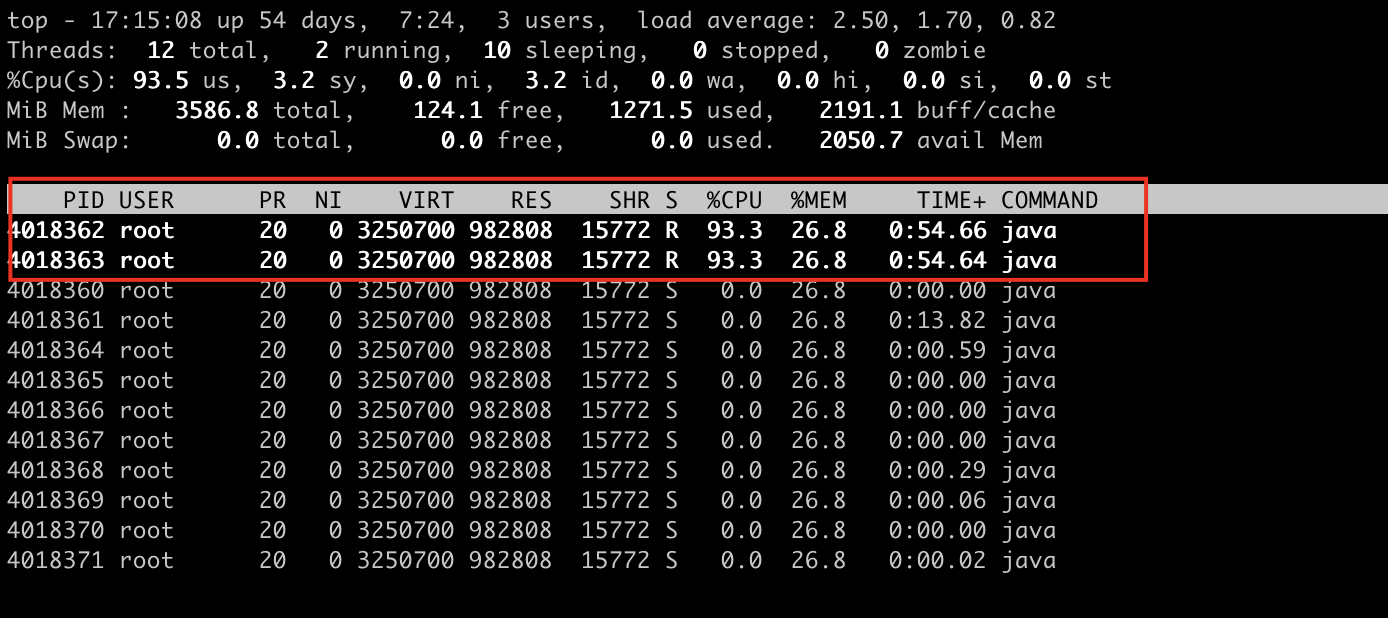
我们可以看出线程0和线程1线程号飙高。
第四步:找到内存和cpu占用最高的线程tid
通过上图我们看到占用cpu资源最高的线程有两个,线程号分别是4013442,4013457。我们一第一个为例说明,如何查询这个线程是哪个线程,以及这个线程的什么地方出现问题,导致cpu飙高。
第五步:将线程tid转化为十六进制
67187778是线程号为4013442的十六进制数。具体转换可以网上查询工具。
第六步:执行[ jstack 4013440|grep -A 10 67187778] 查询飙高线程的堆栈信息
接下来查询飙高线程的堆栈信息
jstack 4013440|grep -A 10 67190882
- 4013440:表示的是进程号
- 67187778: 表示的是线程号对应的十六进制数
通过这个方式可以查询到这个线程对应的堆栈信息
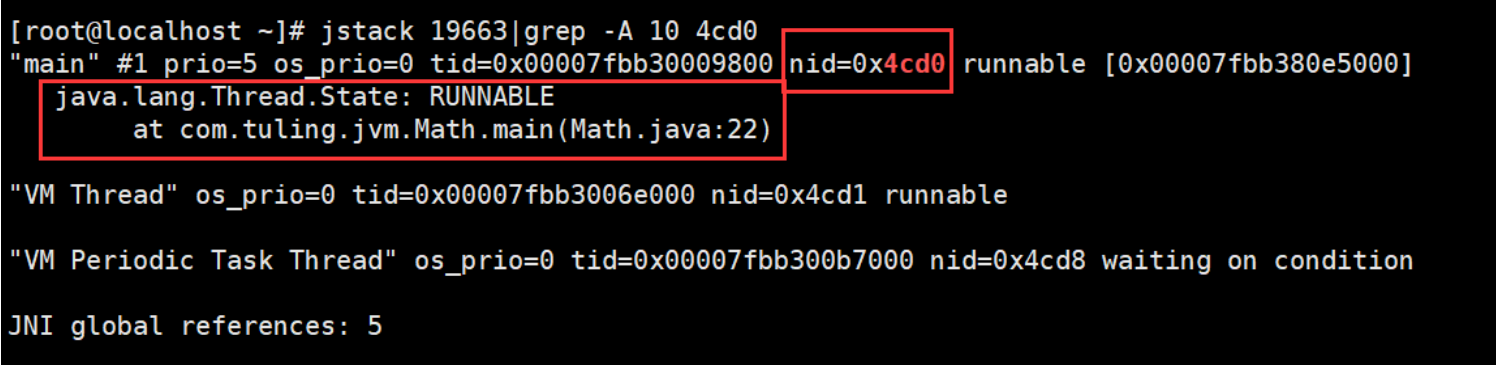
从这里我们可以看出有问题的线程id是0x4cd0, 哪一句代码有问题呢,Math类的22行。
第七步:查看对应的堆栈信息找出可能存在问题的代码
上述方法定位问题已经很精确了,接下来就是区代码里排查为什么会有问题了。
五、Jinfo
Jinfo命令主要用来查看jvm参数
1. 查看当前运行的jvm参数
jinfo -flags 线程id
执行结果:


从结果可以看出,我们使用的是CMS+Parallel垃圾收集器
2. 查看java系统参数
jinfo -sysprops 进程id
执行结果:
Java System Properties:
#Thu Nov 11 17:28:19 CST 2021
java.runtime.name=OpenJDK Runtime Environment
java.protocol.handler.pkgs=org.springframework.boot.loader
sun.boot.library.path=/data/java/jdk8/jre/lib/amd64
java.vm.version=25.40-b25
java.vm.vendor=Oracle Corporation
java.vendor.url=http\://java.oracle.com/
path.separator=\:
java.vm.name=OpenJDK 64-Bit Server VM
file.encoding.pkg=sun.io
user.country=CN
sun.java.launcher=SUN_STANDARD
sun.os.patch.level=unknown
java.vm.specification.name=Java Virtual Machine Specification
user.dir=/data/temp
java.runtime.version=1.8.0_41-b04
java.awt.graphicsenv=sun.awt.X11GraphicsEnvironment
java.endorsed.dirs=/data/java/jdk8/jre/lib/endorsed
os.arch=amd64
java.io.tmpdir=/tmp
line.separator=\n
java.vm.specification.vendor=Oracle Corporation
os.name=Linux
sun.jnu.encoding=UTF-8
java.library.path=/usr/java/packages/lib/amd64\:/usr/lib64\:/lib64\:/lib\:/usr/lib
java.specification.name=Java Platform API Specification
java.class.version=52.0
sun.management.compiler=HotSpot 64-Bit Tiered Compilers
os.version=5.10.23-5.al8.x86_64
user.home=/root
user.timezone=Asia/Shanghai
java.awt.printerjob=sun.print.PSPrinterJob
file.encoding=UTF-8
java.specification.version=1.8
user.name=root
java.class.path=chapter1-jvm-0.0.1-SNAPSHOT.jar
java.vm.specification.version=1.8
sun.java.command=chapter1-jvm-0.0.1-SNAPSHOT.jar
java.home=/data/java/jdk8/jre
sun.arch.data.model=64
user.language=zh
java.specification.vendor=Oracle Corporation
awt.toolkit=sun.awt.X11.XToolkit
java.vm.info=mixed mode
java.version=1.8.0_41
java.ext.dirs=/data/java/jdk8/jre/lib/ext\:/usr/java/packages/lib/ext
sun.boot.class.path=/data/java/jdk8/jre/lib/resources.jar\:/data/java/jdk8/jre/lib/rt.jar\:/data/java/jdk8/jre/lib/sunrsasign.jar\:/data/java/jdk8/jre/lib/jsse.jar\:/data/java/jdk8/jre/lib/jce.jar\:/data/java/jdk8/jre/lib/charsets.jar\:/data/java/jdk8/jre/lib/jfr.jar\:/data/java/jdk8/jre/classes
java.vendor=Oracle Corporation
file.separator=/
java.vendor.url.bug=http\://bugreport.sun.com/bugreport/
sun.io.unicode.encoding=UnicodeLittle
sun.cpu.endian=little
sun.cpu.isalist=
六、Jstat使用
Jstat命令是jvm调优非常重要,且非常有效的命令。我们来看看她的用法:
1. 垃圾回收统计 jstat -gc
jstat -gc 进程id
这个命令非常常用,在线上有问题的时候,可以通过这个命令来分析问题。
下面我们来测试一下,启动一个项目,然后在终端驶入jstat -gc 进程id,得到如下结果:

上面的参数分别是什么意思呢?先识别参数的含义,然后根据参数进行分析
- S0C: 第一个Survivor区的容量
- S1C: 第二个Survivor区的容量
- S0U: 第一个Survivor区已经使用的容量
- S1U:第二个Survivor区已经使用的容量
- EC: 新生代Eden区的容量
- EU: 新生代Eden区已经使用的容量
- OC: 老年代容量
- OU:老年代已经使用的容量
- MC: 方法区大小(元空间)
- MU: 方法区已经使用的大小
- CCSC:压缩指针占用空间
- CCSU:压缩指针已经使用的空间
- YGC: YoungGC已经发生的次数
- YGCT: 这一次YoungGC耗时
- FGC: Full GC发生的次数
- FGCT: Full GC耗时
- GCT: 总的GC耗时,等于YGCT+FGCT
连续观察GC变化的命令
jstat -gc 进程ID 间隔时间 打印次数
举个例子:我要打印10次gc信息,每次间隔1秒
jstat -gc 进程ID 1000 10
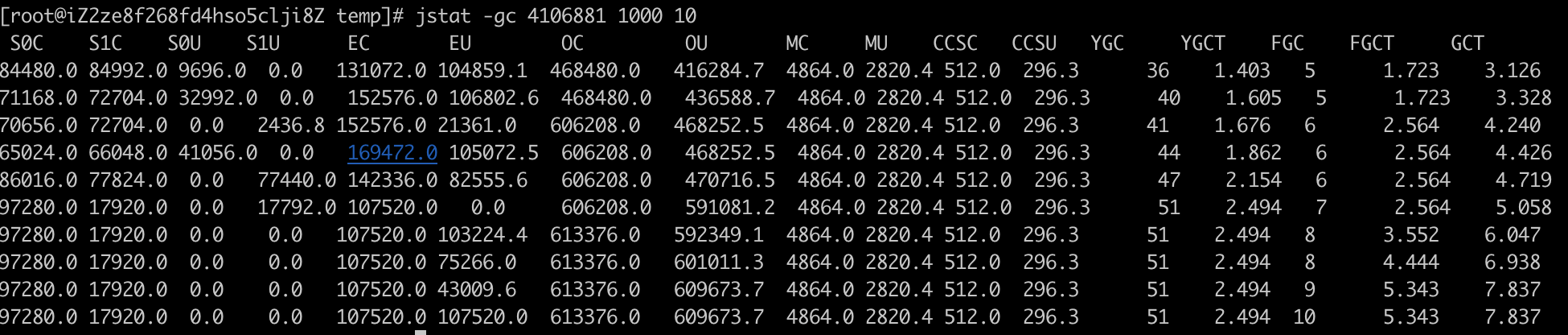
这样就连续打印了10次gc的变化,每次隔一秒。
这个命令是对整体垃圾回收情况的统计,下面将会差分处理。
2.堆内存统计
这个命令是打印堆内存的使用情况。
jstat -gccapacity 进程ID

- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0C:第一个Survivor区大小
- S1C:第二个Survivor区大小
- EC:Eden区的大小
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC: 当前老年代大小
- MCMN: 最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小压缩类空间大小
- CCSMX:最大压缩类空间大小
- CCSC:当前压缩类空间大小
- YGC:年轻代gc次数
- FGC:老年代GC次数
3.新生代垃圾回收统计
命令:
jstat -gcnew 进程ID [ 间隔时间 打印次数]
这个指的是当前某一次GC的内存情况

- S0C:第一个Survivor的大小
- S1C:第二个Survivor的大小
- S0U:第一个Survivor已使用大小
- S1U:第二个Survivor已使用大小
- TT: 对象在新生代存活的次数
- MTT: 对象在新生代存活的最大次数
- DSS: 期望的Survivor大小
- EC:Eden区的大小
- EU:Eden区的使用大小
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
4. 新生代内存统计
jstat -gcnewcapacity 进程ID

参数含义:
- NGCMN:新生代最小容量
- NGCMX:新生代最大容量
- NGC:当前新生代容量
- S0CMX:Survivor 1区最大大小
- S0C:当前Survivor 1区大小
- S1CMX:Survivor 2区最大大小
- S1C:当前Survivor 2区大小
- ECMX:最大Eden区大小
- EC:当前Eden区大小
- YGC:年轻代垃圾回收次数
- FGC:老年代回收次数
5. 老年代垃圾回收统计
命令:
jstat -gcold 进程ID

参数含义:
- MC:方法区大小
- MU:方法区已使用大小
- CCSC:压缩指针类空间大小
- CCSU:压缩类空间已使用大小
- OC:老年代大小
- OU:老年代已使用大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间,新生代+老年代
6. 老年代内存统计
命令:
jstat -gcoldcapacity 进程ID

参数含义:
- OGCMN:老年代最小容量
- OGCMX:老年代最大容量
- OGC:当前老年代大小
- OC:老年代大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
7. 元数据空间统计
命令
jstat -gcmetacapacity 进程ID

- MCMN:最小元数据容量
- MCMX:最大元数据容量
- MC:当前元数据空间大小
- CCSMN:最小指针压缩类空间大小
- CCSMX:最大指针压缩类空间大小
- CCSC:当前指针压缩类空间大小
- YGC:年轻代垃圾回收次数
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
8.整体运行情况
命令:
jstat -gcutil 进程ID

- S0:Survivor 1区当前使用比例
- S1:Survivor 2区当前使用比例
- E:Eden区使用比例
- O:老年代使用比例
- M:元数据区使用比例
- CCS:指针压缩使用比例
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
七、案例分析
1. JVM运行情况预估
现在有一个线上的异常情况。具体的详情如下;
- 机器配置:2核4G
- JVM内存大小:2G
- 系统运行时间:7天
- 期间发生的Full GC次数和耗时:500多次,200多秒
- 期间发生的Young GC的次数和耗时:1万多次,500多秒。
如何能够知道系统运行期间发生了多少次young gc和多少次full gc,并且他们的耗时是多少呢?使用如下命令:
jstat -gcutil 进程ID
然后就可以看到程序运行的结果了;

这几个参数的具体含义是什么呢?
- S0:Survivor 1区当前使用比例
- S1:Survivor 2区当前使用比例
- E:Eden区使用比例
- O:老年代使用比例
- M:元数据区使用比例
- CCS:指针压缩使用比例
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
2. JVM优化的思路
JVM优化的目标其实主要是Full GC。只要不发生Full GC,基本就不会出现OOM。所以如何优化Full GC就是我们的目标。往前推,老年代的对象是怎么来的呢?从新生代来的,那么我们就要避免朝生夕死的新生代对象进入到老年代。
1) 分析GC数据:
期间发生的Full GC次数和耗时:500多次,200多秒。那么平均7 * 24 * 3600秒/500 = 20分钟发生一次Full GC, 每次full GC耗时:200秒/500=400毫秒;
期间发生的Young GC次数和耗时:1万多次,500多秒,那么平均7 * 24 * 3600秒/10000 = 60秒也就是1分钟发生一次young GC,每次young GC耗时:500/10000=50毫秒;
其实,从full GC和young GC的时间来看,还好,不太长。主要是发生的频次,full gc发生的频次太高了,20分钟一次,通常我们的full gc怎么也要好几个小时触发一次,甚至1天才触发一次。而young gc触发频次也过于频繁,1分钟触发一次。
2)梳理内存模型
根据上述信息,我们可以画一个内存模型出来。
先来看看原系统的JVM参数配置信息
‐Xms1536M ‐Xmx1536M ‐Xmn512M ‐Xss256K ‐XX:SurvivorRatio=6 ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M 2 ‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC ‐XX:CMSInitiatingOccupancyFraction=75 ‐XX:+UseCMSInitiatingOccupancyOnly
- 堆空间:1.5G
- 新生代:512M
- 线程大小:256k
- ‐XX:SurvivorRatio新生代中Eden区域和Survivor区域:6。也就是Eden:S0: S1 = 6:1:1
- 元数据空间:256M
- 采用的垃圾收集器:CMS
- -XX:CMSInitiatingOccupancyFraction=75:CMS在对内存占用率达到75%的时候开始GC
- -XX:+UseCMSInitiatingOccupancyOnly: 只是用设定的回收阈值(上面指定的70%), 如果不指定, JVM仅在第一次使用设定值, 后续则自动调整.
根据参数我们梳理如下内存模型。堆内存空间都分配好了,那么上面说了每过60s触发一次Young GC,那么就是说,平均每秒会产生384/60=6.4M的垃圾。而老年代,每过20分钟就会触发一次GC,而老年代可用的内存空是0.75G,也就是750多M。
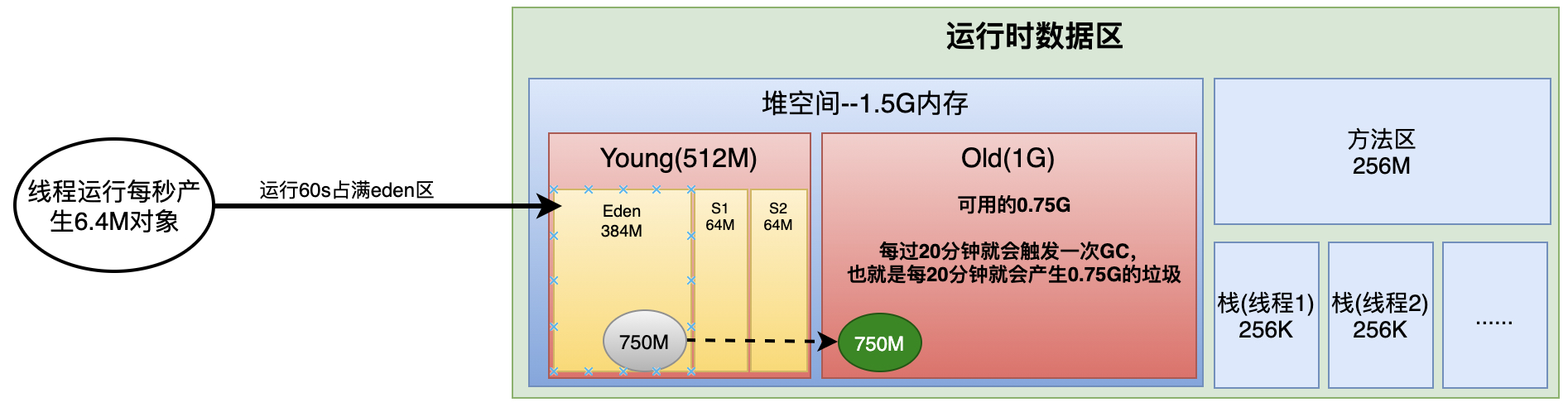
现在的问题,为什么每过20分钟,就会有750M的对象挪到老年代呢?解决了这个问题,我们就可以阻止对象挪到老年代
结合对象挪动到老年的规则分析这个模型可能会有哪些问题:
- 大对象
- 顽固的对象
- 动态年龄判断机制
- 老年代空间担保机制
-
首先分析:我们的系统里会不会有大对象。其实代码使我们自己写的,我们知道里面没有特别大的对象。在年轻代放不下了,直接进入老年代,所以这种情况排除
-
第二个顽固的对象:我们这里通常都是朝生夕死的对象,顽固的对象就是系统的那些对象,如果是系统对象,也不应该是每过20分钟都会产生700M老顽固对象啊。
-
第三个动态年龄判断机制:一批对象的总大小大于这块Survivor区域内存大小的50%(-XX:TargetSurvivorRatio可以指定),那么此时大于等于这批对象年龄最大值的对象,就可以直接进入老年代了。这个是有可能的,可能在垃圾收集的时候,Survivor区放不下了,那么就会直接放入到老年代。
既然这种情况有可能,那我们就来分析一下:
线程每秒中产生6M多的垃圾,如果并发量比较大的时候, 处理速度比较慢,可能1s处理不完,假设处理完数据要四五秒,就按5s来算,那一秒就可能产生30M的垃圾,这时候触发Dden区垃圾回收的时候,这30M的垃圾要进入到S1区,而S1区很可能本身就有一部分对象了,再加上这30M就大于S1区的一半了,直接进入老年代。
这只是一种可能。
- 第四个触发老年代空间担保机制:其实触发老年代空间担保机制的概率很小,通常都是老年代空间很小的会后,会触发。我们这里老年代比较大,所以基本不可能。
综上所述,现在最有可能频繁触发GC的可能的原因是动态年龄判断机制。我们之前在做优化的时候,遇到过。可以将Survivor区域放大一点,就可以了。
3. 案例模拟分析
我们用下面这个案例来模拟分析上述情况。分析找到问题。
第一步:启动主程序
-
这时一个springboot的web程序,内容很简单。创建项目的时候注意选择web就可以了
-
然后里面定义了一个User对象。这个User对象比较特别,里面有个参数a分配0.1M的内存空间。
package com.jvm;
public class User {
private int id;
private String name;
byte[] a = new byte[1024*100];
......
}
- 接下来定义了一个接口类
package com.jvm;
import org.springframework.util.StopWatch;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
@RestController
public class IndexController {
@RequestMapping("/user/process")
public String processUserData() throws InterruptedException {
ArrayList<User> users = queryUsers();
for (User user: users) {
//TODO 业务处理
System.out.println("user:" + user.toString());
}
return "end";
}
/**
* 模拟批量查询用户场景
* @return
*/
private ArrayList<User> queryUsers() {
ArrayList<User> users = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
users.add(new User(i,"zhuge"));
}
return users;
}
}
接口类很简单,每次调用接口,先创建5000个用户,然后让这5000个用户区执行各自的业务逻辑。需要注意的是5000个用户占用内存空间约500M。也就是说,每次调用这个接口,都会产生500M的对象。
- 然后定义一个测试类,测试类
@RunWith(SpringRunner.class)
@SpringBootTest(classes={Application.class})// 指定启动类
public class ApplicationTests {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
@Autowired
private RestTemplate restTemplate;
@Test
public void test() throws Exception {
for (int i = 0; i < 10000; i++) {
String result = restTemplate.getForObject("http://localhost:8080/user/process", String.class);
Thread.sleep(1000);
}
}
}
测试类很简单,就是手动调用上面的接口。循环调用10000次。如果启动10000次的话,
- 启动主程序
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
第二步:配置jvm参数
我们要模拟线上的情况,所以参数也设置和线上一样的情况。
-Xms1536M -Xmx1536M -Xmn512M -Xss256K -XX:SurvivorRatio=6 -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly
第三步:使用jstat gc命令观察垃圾收集情况
程序启动起来以后,可以使用jps命令查看进程,输入命令查看gc触发情况
jstat -gc 进程ID [间隔时间 触发次数]
jstat -gc 8620 1000 10000
表示观察8620这个进程,每隔1s打印一次gc情况,连续打印10000次

我们看到,程序启动以后都是出发了4次young gc, 1次full gc。程序启动触发gc都是ok的。后面基本没有什么垃圾产生了。
第四步:启动test代码,调用process接口
这一步没啥说的,直接启动程序就可以了
第五步:观察终端gc的变化
为了保险期间,我们查看一下运行的参数是不是我们配置的参数
jinfo -flags 8620
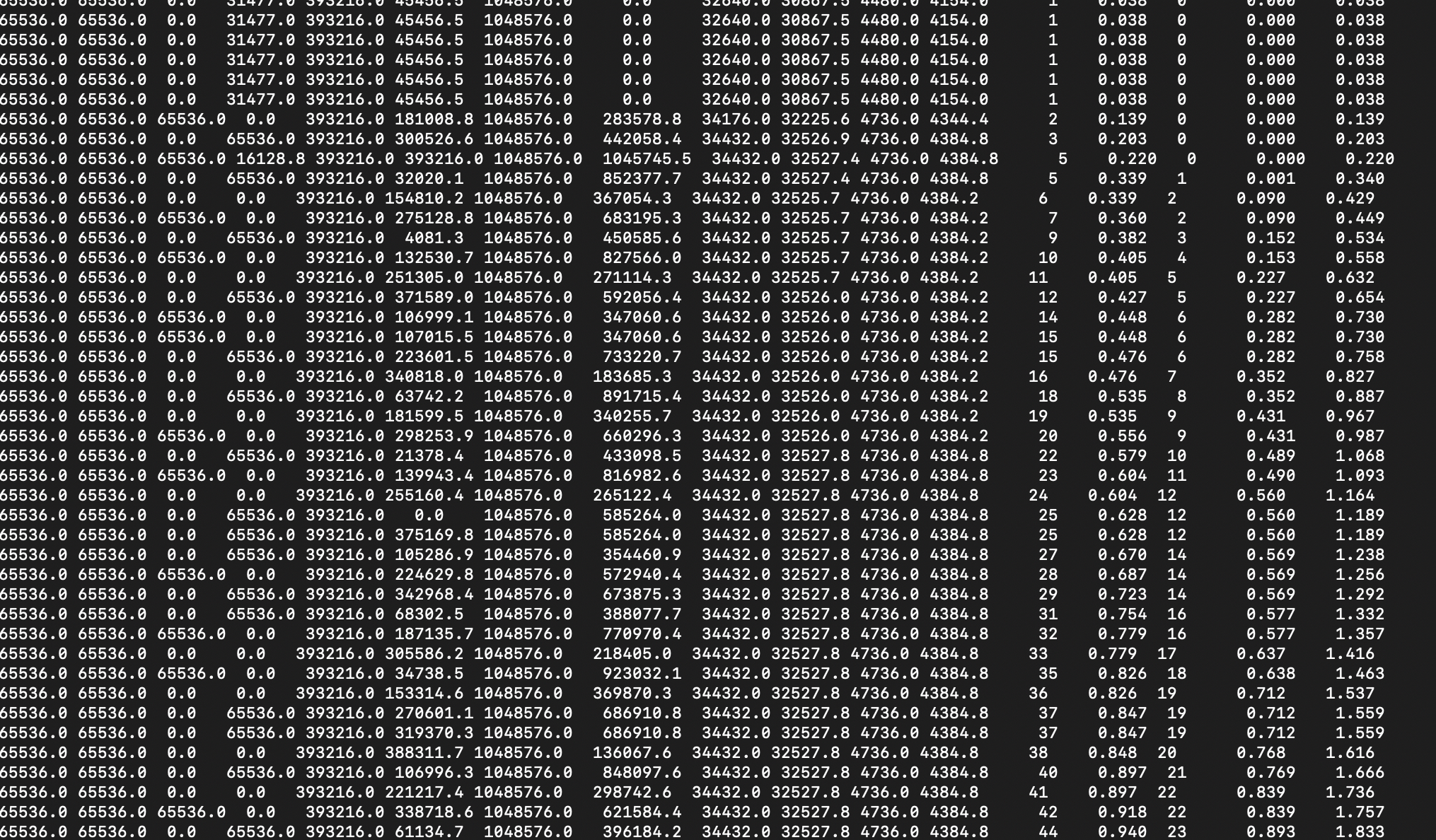
程序启动以后,我们发现频发的触发了gc,新生代gc触发很频繁,老年代也很频繁。老年代gc触发那么频繁,那就是有问题了。根据上面的分析,最有可能的情况是动态年龄分配机制。可能产生的对象在survivor区放不下,直接进入老年代 。处理这个问题的方法是,扩大年轻代空间。
第六步:优化1:增加新生代内存空间,以及老年代触发gc的比例
- 新生代空间扩大到1G
- 老年代空间缩小为0.5G
- 还要重新设置一个参数就是CMSInitiatingOccupancyFraction,原来是是75,这个参数是为了防止触发老年代空间担保机制。但这样会有25%的空间基本是空闲的。当很少触发full gc的时候,这个值可以缩小一些。
-Xms1536M -Xmx1536M -Xmn1024M -Xss256K -XX:SurvivorRatio=6 -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=92 -XX:+UseCMSInitiatingOccupancyOnly
内存空间变化后:
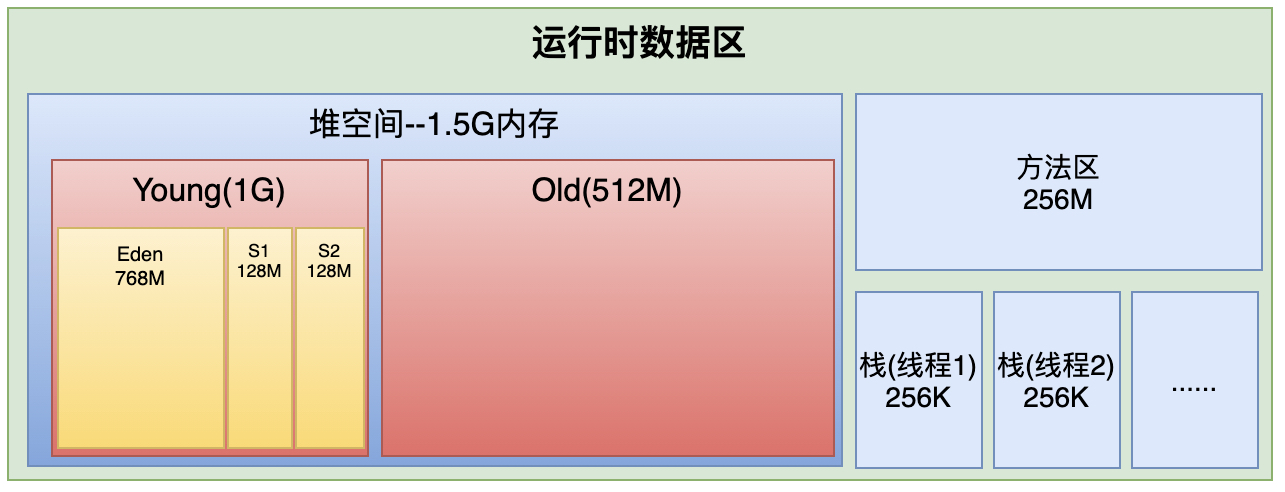
再次启动项目,看运行结果:

基本没有gc触发。说明我们的优化是有效的。然后在启动测试程序:
 这一次我们发现,触发gc的次数相对来说少了,gc的速度相对于上一次小了一些,但是又有新的问题发生:老年代gc比年轻代还有频繁。这是怎么回事呢?有什么情况会让老年代触发gc的频率大于年轻代呢?
这一次我们发现,触发gc的次数相对来说少了,gc的速度相对于上一次小了一些,但是又有新的问题发生:老年代gc比年轻代还有频繁。这是怎么回事呢?有什么情况会让老年代触发gc的频率大于年轻代呢?
这可能会有几种情况
- 元数据空间不够,导致full gc,不断扩大元数据空间
元数据空间比较好看,我们直接看输出的参数

红框圈出的就是元数据空间和元数据已用空间。我们来看实际使用情况
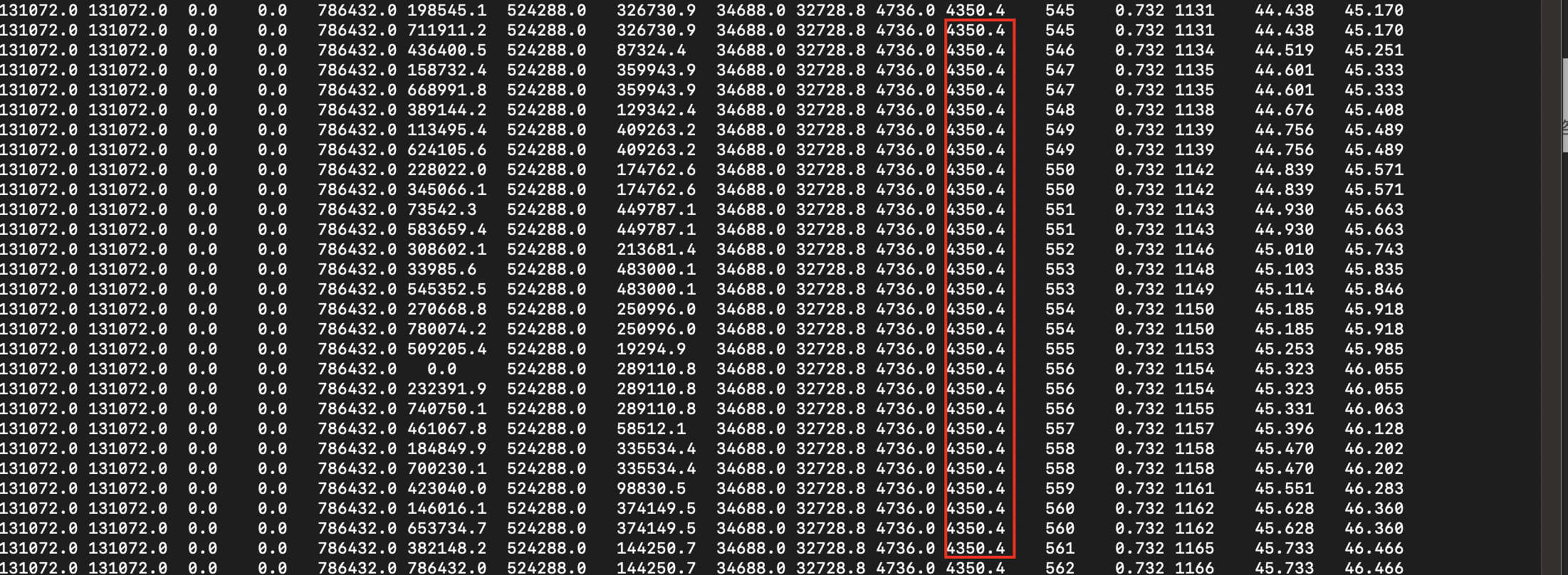
通过观察,我们发现元数据大小基本上是不变的。所以,元数据空间不太会增加导致触发full gc。
- 显式的调用System.gc(),造成多余的full gc触发。
这个情况一般在线上都会进制成都代码触发full gc。量通过XX:+DisableExplicitGC参数禁用,如果加上了这个JVM启动参数,那么代码中调用System.gc()没有任何效果。
- 触发了老年代空间担保机制
结合之前学习的理论,我们知道,老年代空间担保机制。有可能在触发一次minor GC的时候触发两次Full GC。
来复习一下:
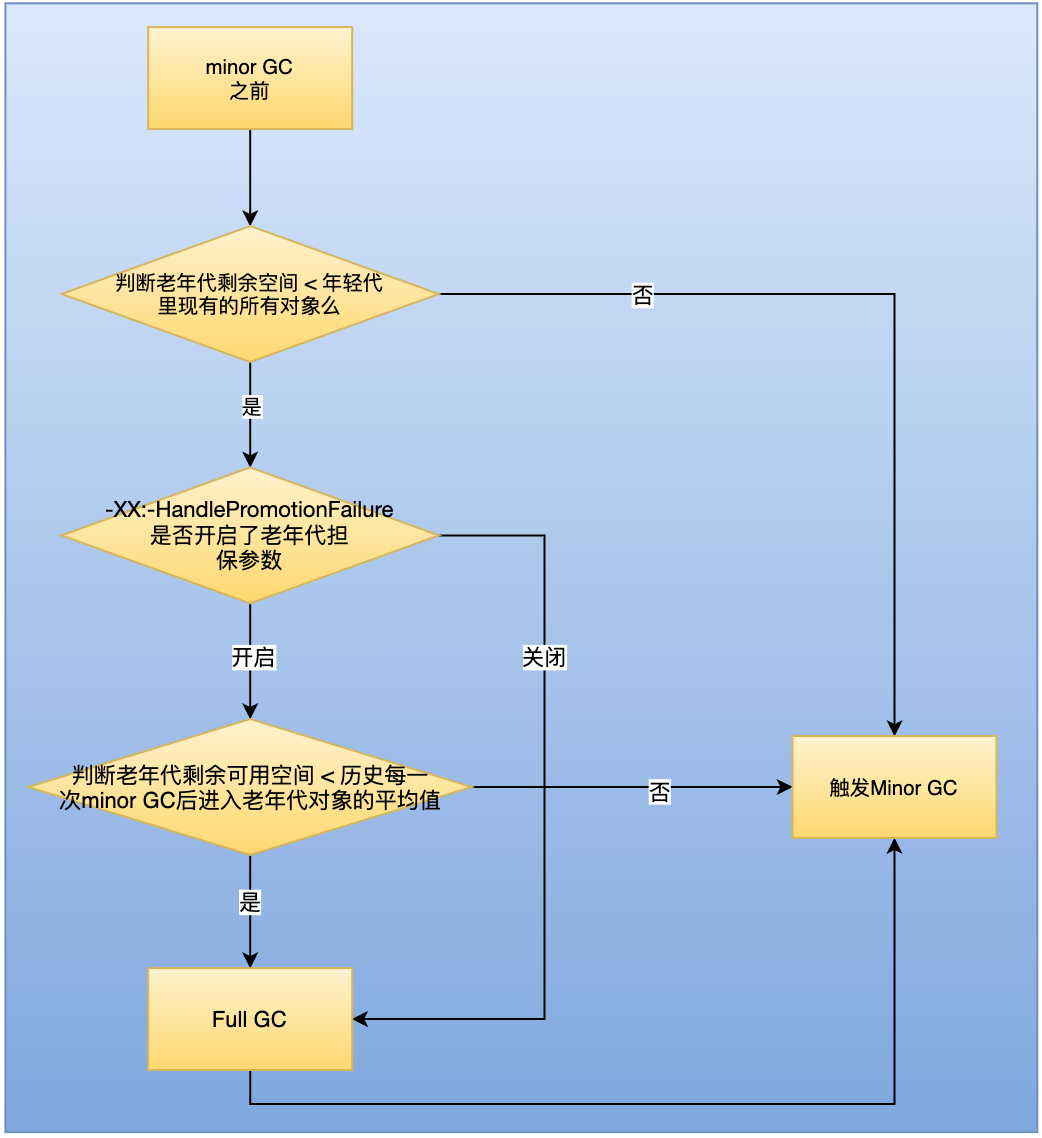
-
年轻代每次minor gc之前JVM都会计算下老年代剩余可用空间。如果这个可用空间小于年轻代里现有的所有对象大小之和(包括垃圾对象),就会看一个“-XX:-HandlePromotionFailure”(jdk1.8默认就设置了)的参数是否设置了,如果有这个参数,就会看看老年代的可用内存大小,是否大于之前每一次minor gc后进入老年代的对象的平均大小。
-
如果上一步结果是小于或者之前说的参数没有设置,那么就会直接触发一次Full GC,然后再触发Minor GC, 如果回收完还是没有足够空间存放新的对象就会发生"OOM"
-
如果minor gc之后剩余存活的需要挪动到老年代的对象大小还是大于老年代可用空间,那么也会触发full GC,Full GC完之后如果还是没有空间放minor gc之后的存活对象,则也会发生“OOM”。
在梳理一下这块逻辑,为什么叫担保机制。在触发Minor GC的时候,进行了一个条件判断,预估老年代空间是否能够放的下新生代的对象,如果能够放得下,那么就直接触发Minor GC, 如果放不下,那么先触发Full GC。在触发Full GC的时候设置了担保参数会增加异步判断,而不是直接触发Full GC。判断老年代剩余可用空间 是否小于 历史每次Minor GC后进入老年代对象的平均值。这样的判断可以减少Full GC的次数。因为新生代在触发Full GC以后是会回收一部分内存的,剩余部分再放入老年代,可能就能放下了。
通过回顾,我们看到老年代空间担保机制中,当触发一次Minor GC的时候,有可能会触发两次Full GC。这样就导致Full GC的次数大于Minor GC。
由此可见,我们这次优化是失败的, 还引入了新的问题。这里还有可能是大对象导致的,不一定是非常大的一个对象,也可能是多个对象在一个时刻产生的大对象。
第七步:优化2:查找大对象
我们在查找是否有大对象,或者某一个时间是否有大对象占用较大的内存空间,可以使用命令或者终端查看
jmap -histo 进程ID
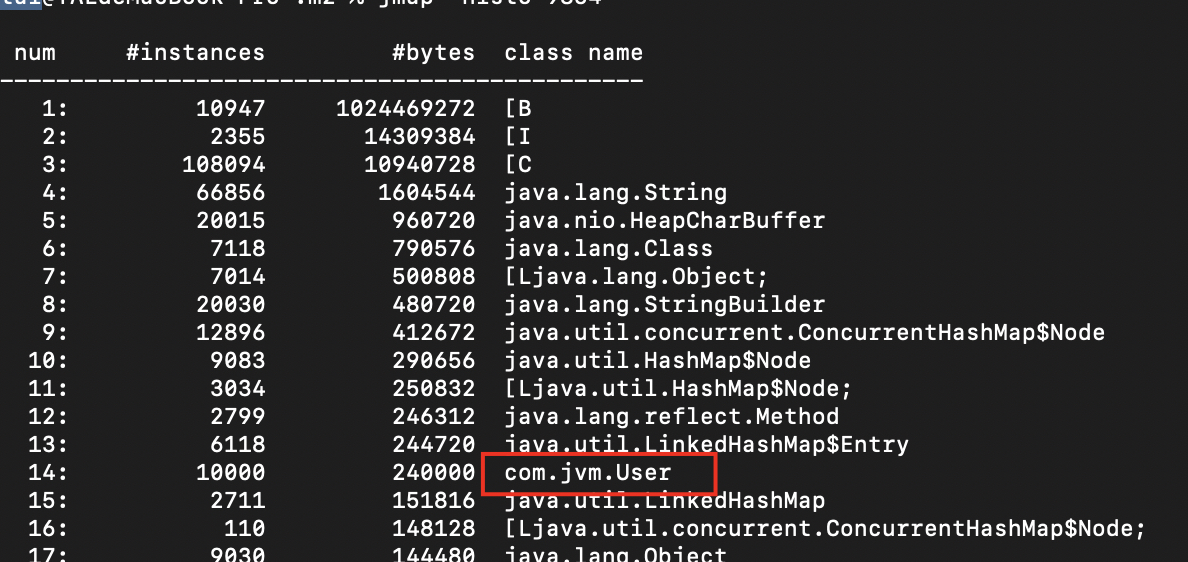
前面都是系统对象,往下找我们看到一个自定义对象User,这个实例有10000个,占用内存空间240M
或者使用jvisualvm
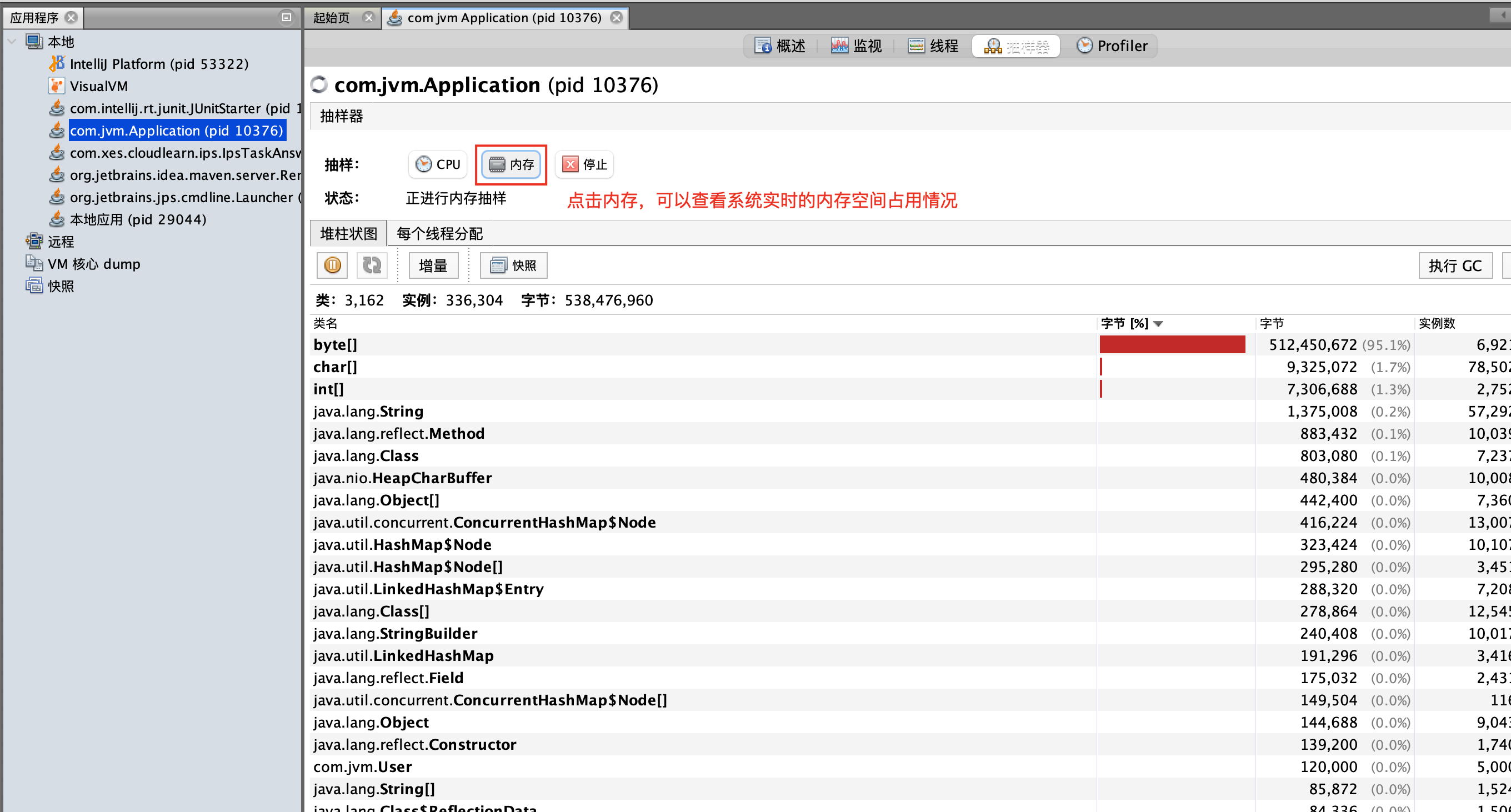
点击内存,就可以实时查看到系统进程的内存占用情况。点击内存其实就是对 【jmap -histo 进程ID】命令的包装
内存占用最多的是byte[]数组,占用了内存的95%。是什么情况让byte数组占用这么多的内存呢?这个通常都是用户自定义对象造成的。往下看,我们看到了User对象,user对象占用了12w字节数据,有5000个实例。
假如这个代码不是我们写的,是别人写的,我们不熟悉。这时候可以通过以下方法定位问题
-
new User()对象不多。可以通过反查定位找出问题。
/** * 模拟批量查询用户场景 * @return */ private ArrayList<User> queryUsers() { ArrayList<User> users = new ArrayList<>(); for (int i = 0; i < 5000; i++) { users.add(new User(i,"zhuge")); } return users; }我们发现,在这里竟然创建了5000个对象。不过5000个对象应该也不多。通常一个对象也就几k,我们进到User里看看
public class User { private int id; private String name; byte[] a = new byte[1024*100]; }意外发现,User里定义了一个byte数组,一个byte数组占用100k的空间。那问题就是这里了。
-
如果系统中new User()对象很多,应该怎么办呢?
系统中有这么多对象,说明什么问题呢?new User()在反复执行,这样的话,cpu占用率应该不低。如果这边不好找,我们可以看看cpu占用情况。
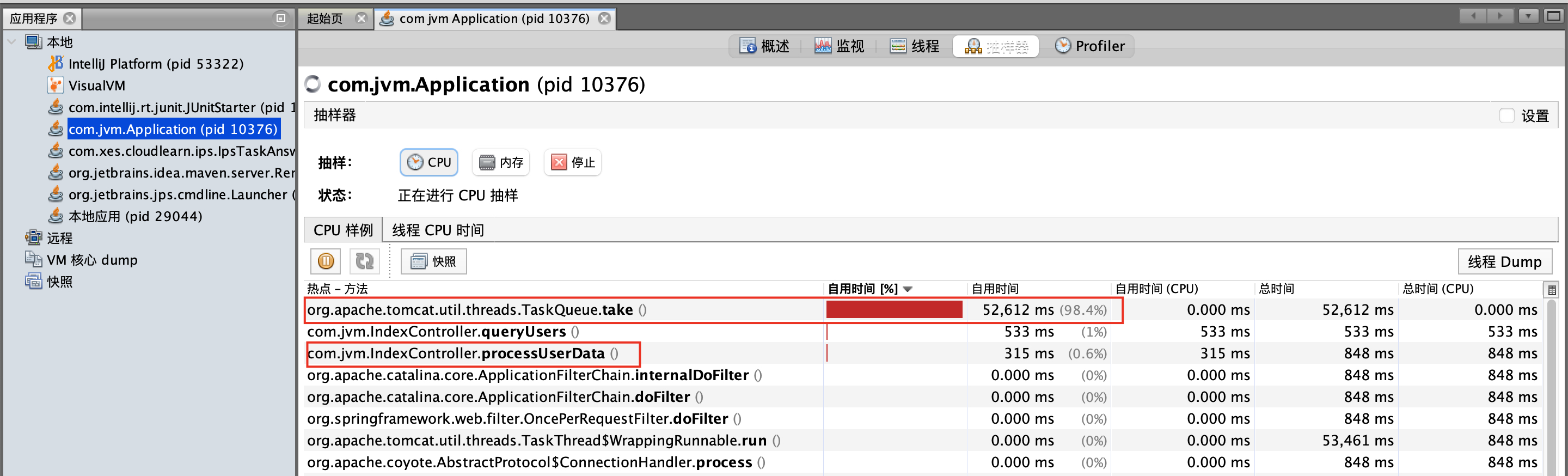
这里的cpu其实就是对命令是对jstack命令的封装【jstack 4013440|grep -A 10 67187778】
通过分析我们看出第一个take()方法占用cpu最高,达到98%,但是这个是什么东西,我们不太熟悉,看看第二个,第二个是queryUsers(),这个是我们自己的方法,可以看看这个方法的具体内容:
/**
* 模拟批量查询用户场景
* @return
*/
private ArrayList<User> queryUsers() {
ArrayList<User> users = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
users.add(new User(i,"zhuge"));
}
return users;
}
public class User {
private int id;
private String name;
byte[] a = new byte[1024*100];
}
刚好就定位到这段代码,我们发现他一下查询了5000个对象,并且每个对象里定义了一个大对象。这样我们就定位到了问题。
所以在查询数据的时候,要注意是否有大对象,如果有大对象的话,需要预估一下内存消耗。剩下就是代码优化的问题了。
我们这里降低查询用户数从一次5000到一次500,然后重启代码试一下:
private ArrayList<User> queryUsers() {
ArrayList<User> users = new ArrayList<>();
for (int i = 0; i < 500; i++) {
users.add(new User(i,"zhuge"));
}
return users;
}
来看看运行效果
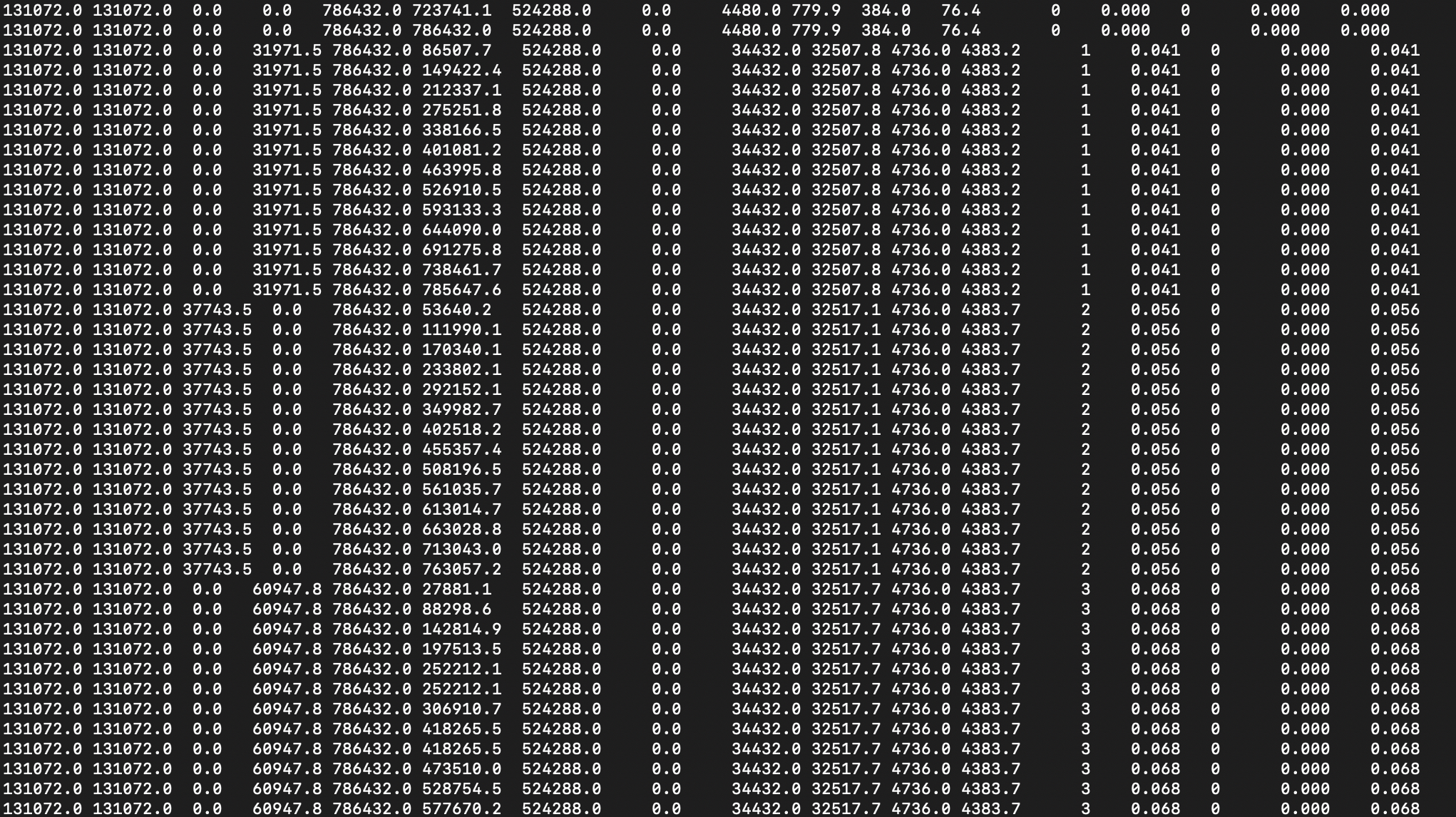
触发young gc的频率降低了,而且基本不会触发full gc了。说明这次优化是有效的。
