1. java结构体系
Description of Java Conceptual Diagram(java结构)
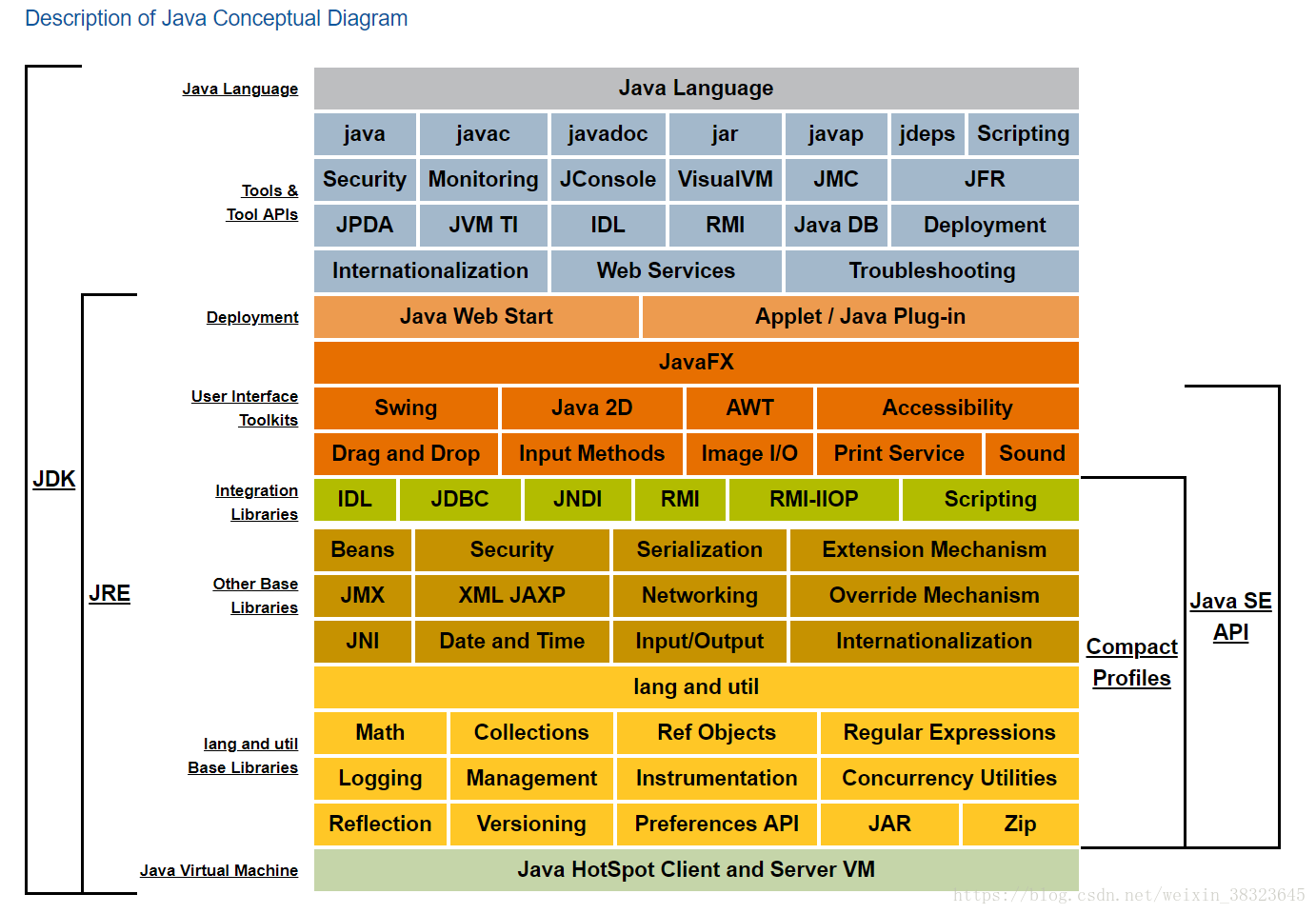
以上就是java结构体系, 主要由两部分构成,
第一部分是java 工具(Tools&Tool APIs), 比如java命令, javac, javap命令.
第二部分是: JRE,也就是java running enveriment. jre是Java的核心, 里面定义了java运行时需要的核心类库, 比如:我们常用的lang包, util包, Math包, Collection包等等.这里还有一个很重要的部分JVM(最后一部分青色的) ava 虚拟机, 这部分也是属于jre, 是java运行时环境的一部分.
二. java语言的跨平台特性

我们来简单看一下java语言是如何实现跨平台的?
跨平台指的是, 程序员开发出的一套代码, 在windows平台上能运行, 在linux上也能运行, 在mac上也能运行. 我们都知道, 机器最终运行的指令都是二进制指令. 但是同样的代码, 在windows上生成的二进制指令可能是1101, 但是在linux上是1001, 而在mac上是0101. 这样同样的代码, 如果要想在不同的平台运行, 放到相应的平台, 就要修改代码, 而java却不用, 那么java这种跨平台特性是怎么做到的呢?
原因在于jdk, 我们最终是将程序编译成二进制码,把他丢在jvm上运行的, 而jvm是jre的一部分. 我们在不同的平台下载的jdk是不同的. windows平台要选择下载适用于windows的jdk, linux要选择适用于linux的jdk, mac要选择适用于mac的jdk. 不同平台的jvm针对该平台有一个特定的实现, 正是这种特点的实现, 让java实现了跨平台
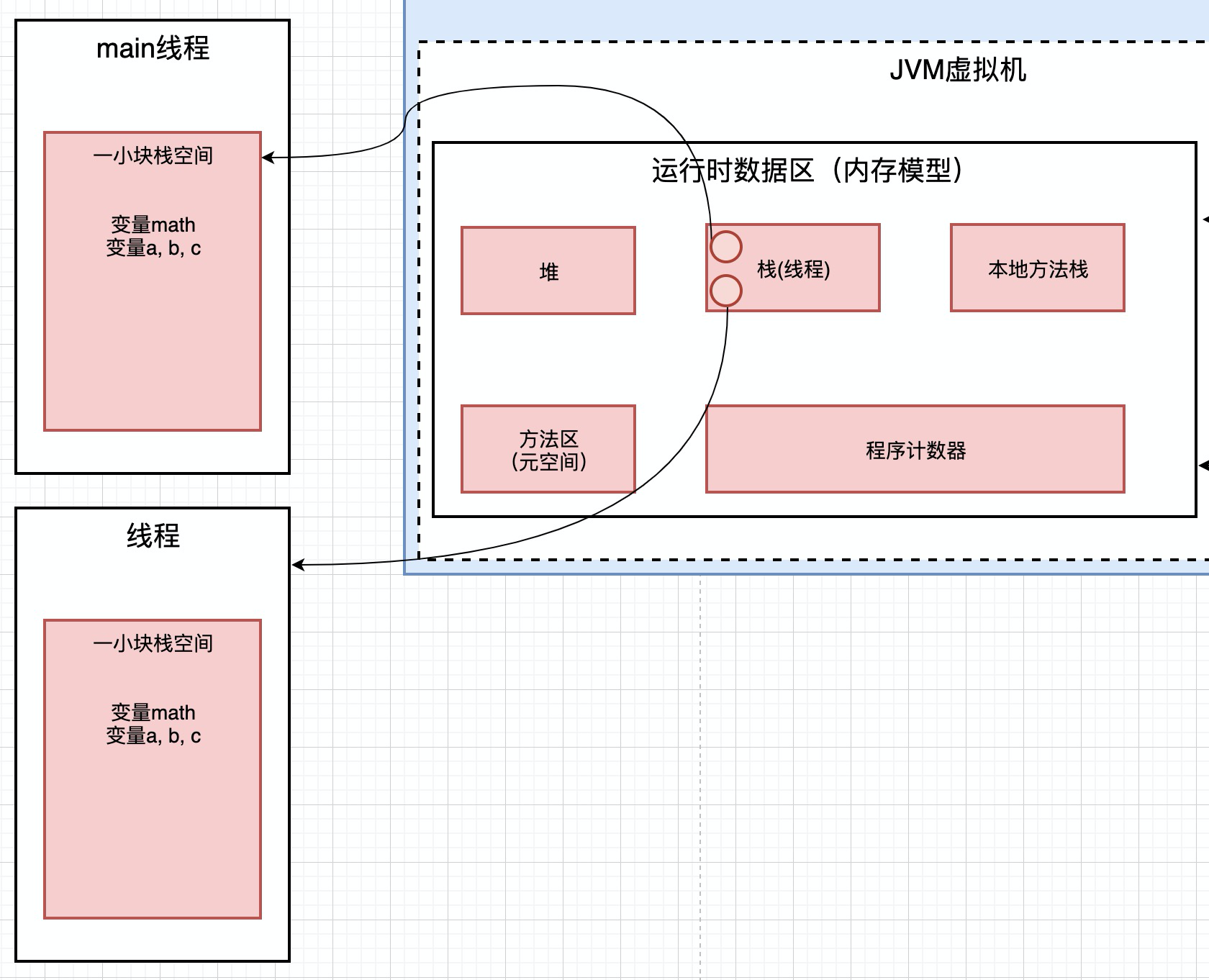
三. JVM整体结构和内存模型
JVM有三块组成: 类装载子系统, 运行时数据区(内存模型) , 字节码执行引擎
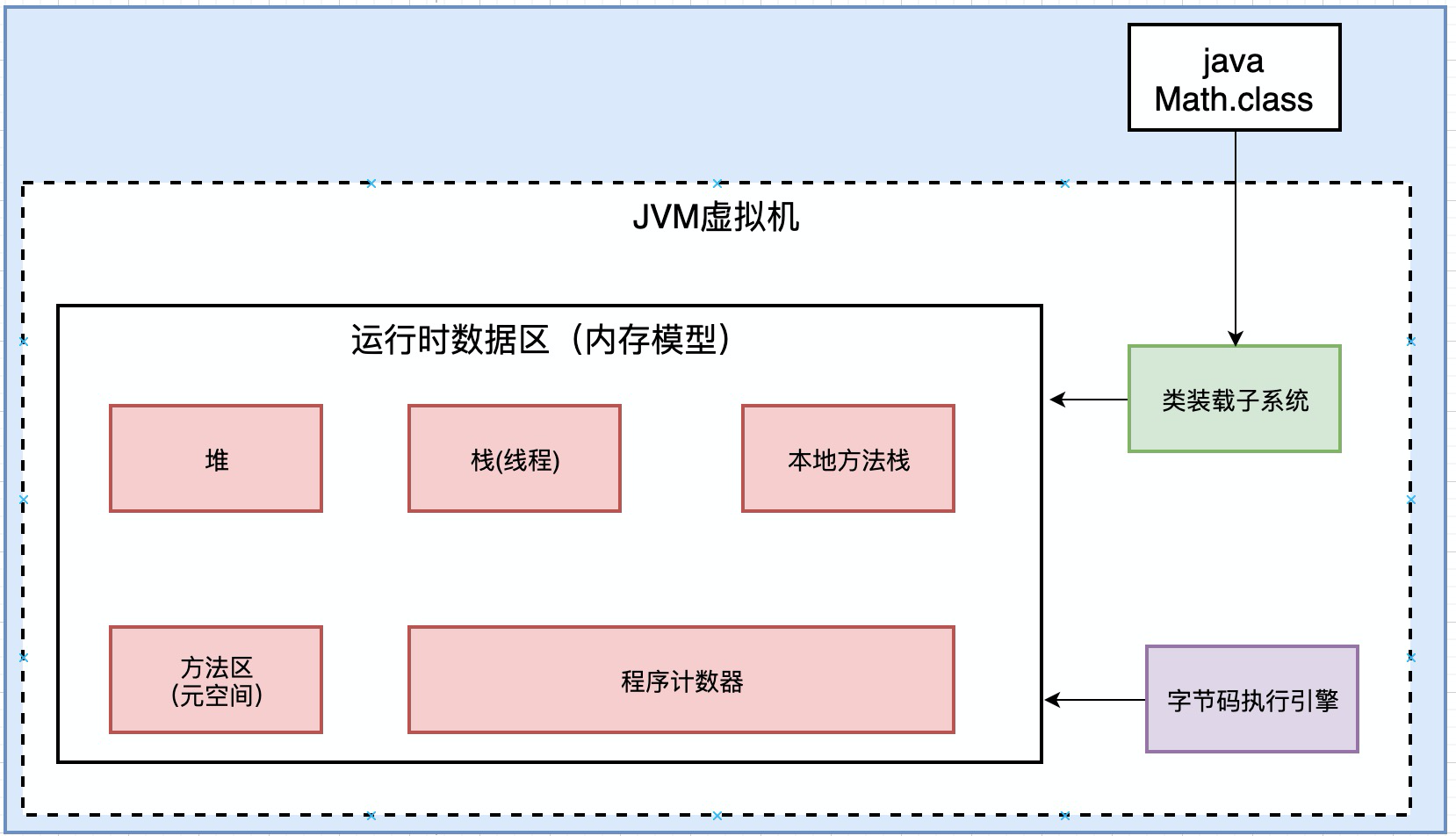
其中类装载子系统是C++实现的, 他把类加载进来,放入到虚拟机中. 然后, 字节码执行引擎去虚拟机中读取数据. 字节码执行引擎也是c++实现的. 我们重点研究运行时数据区
运行时数据区主要由5个部分构成: 堆, 栈, 本地方法栈, 方法区, 程序计数器.
下面我们来看看一个程序运行的时候, 类装载子系统, 运行时数据区, 字节码执行引擎是如何密切配合工作的?
我们举个例子来说一下:
package com.lxl.jvm; public class Math { public static int initData = 666; public static User user = new User(); public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c; } public static void main(String[] args) { Math math = new Math(); math.compute(); } }
当我们在执行main方法的时候, 都做了什么事情呢?
第一步: 类加载子系统加载Math.class类, 然后将其丢到内存区域, 这个就是前面博客研究的部分,类加载的过程, 我们看源码也发现,里面好多代码都是native本地的, 是c++实现的
第二步: 在内存中处理字节码文件, 这一部分内容较多, 也是我们研究的重点, 后面会对每一个部分详细说
第三步: 由字节码执行引擎执行java虚拟机中的内存代码, 而字节码执行引擎也是由c++实现的
这里最核心的部分是第二部分运行时数据区(内存模型), 我们后面的调优, 都是针对这个区域来进行的.
下面详细来说内存区域
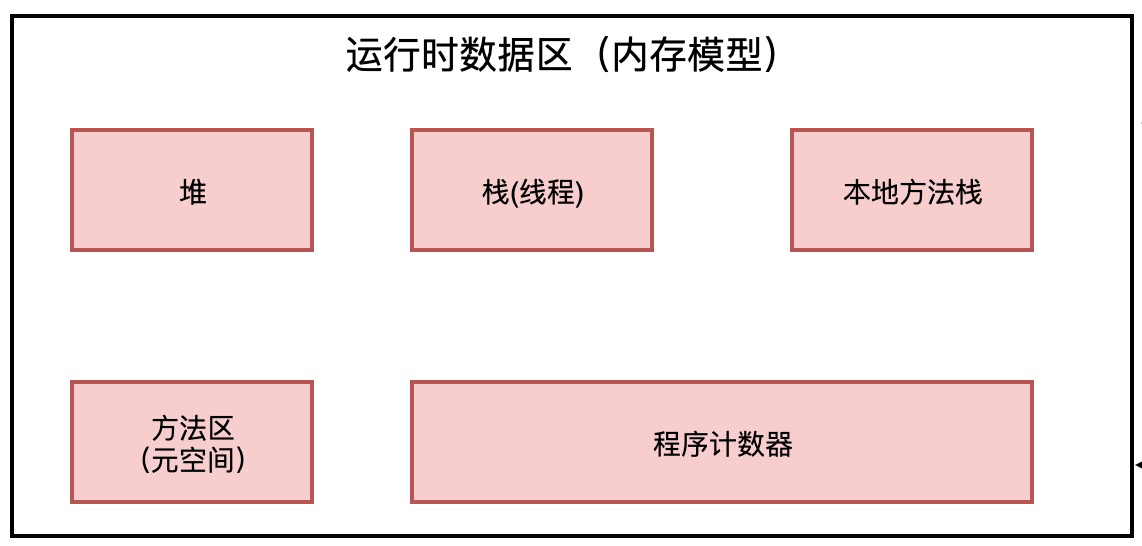
这是java的内存区域, 内存区域干什么呢?内存区域其实就是放数据的,各种各样的数据放在不同的内存区域
四. 栈
先来说说栈:
还是用Math的例子来说
当程序运行的时候, 会创建一个线程, 创建线程的时候, 就会在大块的栈空间中分配一块小空间, 用来存放当前要运行的线程的变量
public static void main(String[] args) { Math math = new Math(); math.compute(); }
比如,这段代码要运行,首先会在大块的栈空间中给他分配一块小空间. 这里的math这个局部变量就会被保存在分配的小空间里面.
在这里面我们运行了math.compute()方法, 我们看看compute方法内部实现
public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c; }
这里面有a, b, c这样的局部变量, 这些局部变量放在那里呢? 也放在上面分配的栈小空间里面.
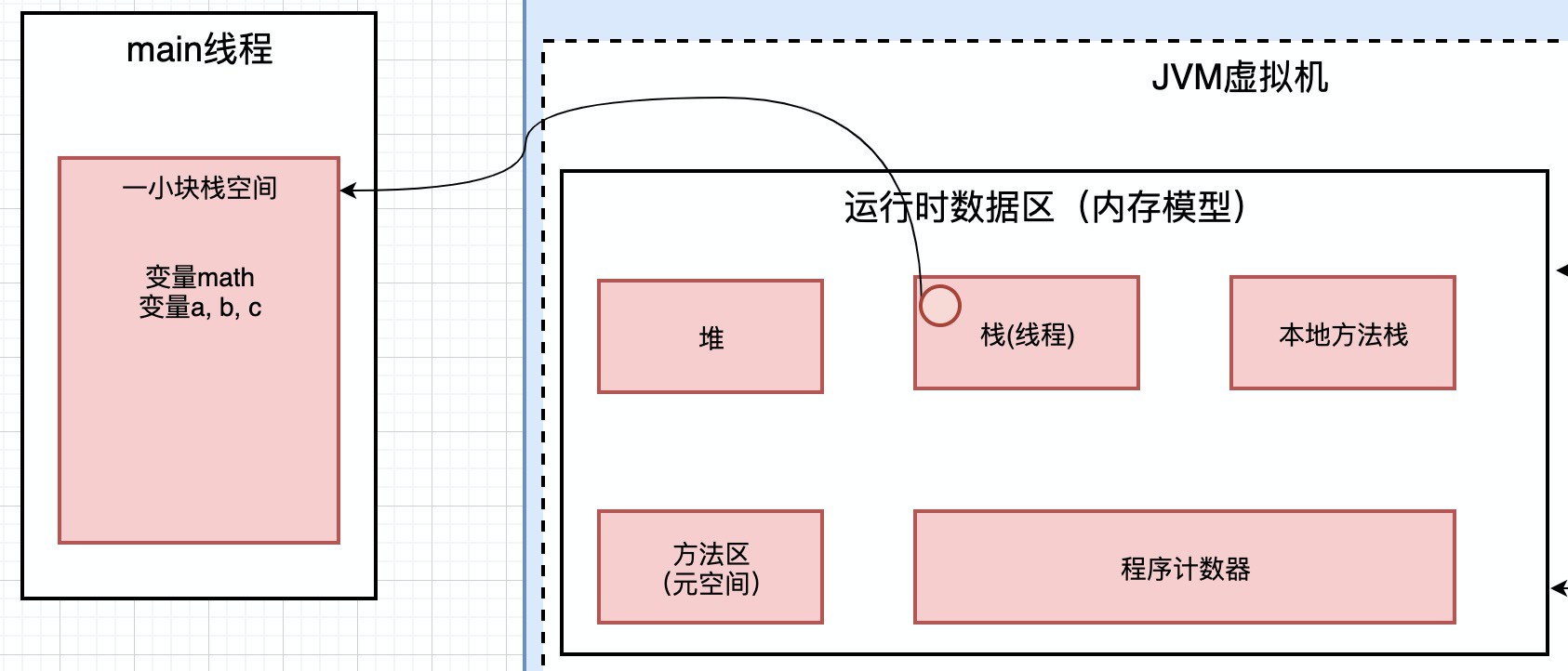
效果如上图, 在栈空间中, 分配一块小的区域, 用来存放Math类中的局部变量
如果再有一个线程呢? 我们就会再次在栈空间中分配一块小的空间, 用来存放新的线程内部的变量
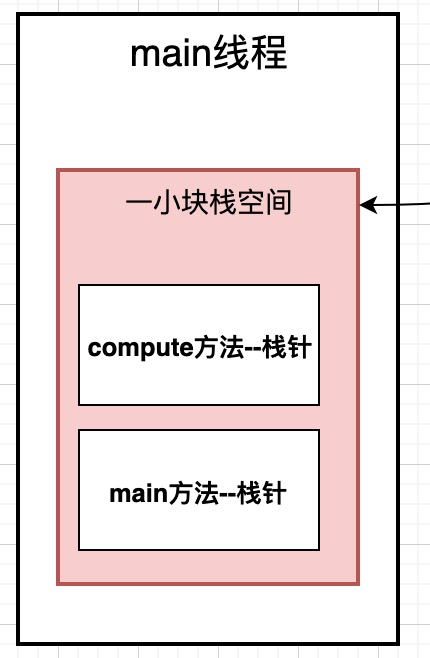
下面来说说什么是栈帧. 同样是变量, main方法中的变量和compute()方法中的变量放在一起么?他们是怎么放得呢?
4.1 栈帧
什么是栈帧呢?
package com.lxl.jvm; public class Math { public static int initData = 666; public static User user = new User(); public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c; } public static void main(String[] args) { Math math = new Math(); math.compute(); } }
还是这段代码, 我们来看一下, 当我们启动一个线程运行main方法的时候, 首先会在栈空分配一块区域,叫做栈帧空间.
当程序运行的compute()计算方法的时候, 又要去调用compute()方法, 这时候会再分配一个栈帧空间, 给compute()方法使用.
为什么要将一个线程中的不同方法放在不同的栈帧里面呢?
一方面: 我们不同方法里的局部变量是不能相互访问的. 比如compute的a,b,c在main里能访问么? 当然不能, 使用栈帧做了很好的隔离作用
另一方面: 方便垃圾回收, 我的一个方法用完了, 值也返回了, 那他里面的变量就是垃圾了, 后面直接回收这个栈帧就好了.
如下图, 在Math中两个方法, 当运行到main方法的时候, 会将main方法放到一块栈针空间, 这里面仅仅是保存main方法中的局部变量, 当执行到compute方法的时候, 这时会开辟一块compute栈针空间, 这部分空间仅存放compute()方法的局部变量. 好处上面已经说过了,
不同的方法开辟出不同的内存空间, 这样方便我们各个方法的局部变量进行管理, 同时也方便垃圾回收.
我们学过栈算法, 栈算法是先进后出的. 那么我们的内存模型里的栈和算法里的栈一样么?有关联么?
我们java内存模型中的栈使用的就是栈算法, 现金后出.举个例子, 还是这段代码
package com.lxl.jvm; public class Math { public static int initData = 666; public static User user = new User(); public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c; } public int add() { int a = 1; int b = 2; int c = a + b; return c; } public static void main(String[] args) { Math math = new Math(); math.compute(); math.add(); // 注意这里调用了两次compute()方法 } }
这时候加载的内存模型是什么样呢?
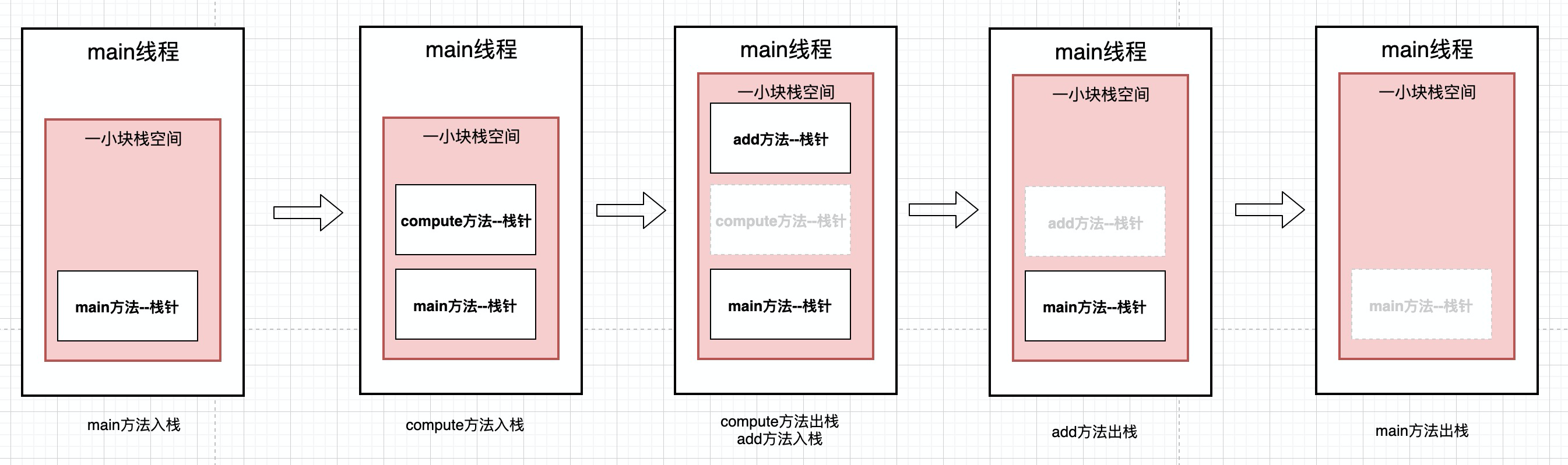
最先进入栈的是main方法, main方法里面调用了compute方法, 然后会在创建一个compute方法的栈帧空间, 我们知道compute方法后加载,但是他却会先执行, 执行完以后, compute中的局部变量就会被回收, 那么也就是出栈. 然后add方法在入栈, add执行完也出栈, 最后执行完main方法,出栈. 这个算法刚好验证了先进后出. 后加载的方法会被先执行.
4.2 栈帧的内部构成
我们上面说了, 每个方法在运行的时候都会有一块对应的栈帧空间, 那么栈帧空间内部的结构是怎样的呢?
栈帧内部有很多部分, 我们主要关注下面这四个部分:
1. 局部变量表 2. 操作数栈 3. 动态链接 4. 方法出口
4.2.1 局部变量表: 存放局部变量
那么操作数栈,动态链接, 方法出口他们是干什么的呢? 我们用例子来说明操作数栈
4.2.2 操作数栈

那么这四个部分是如何工作的呢?
我们用代码的执行过程来对照分析.
我们要看的是jvm反编译后的字节码文件, 使用javap命令生成反编译字节码文件.
javap命令是干什么用的呢? 我们可以查看javap的帮助文档

主要使用javap -c和javap -v
javap -c: 对代码进行反编译
javap -v: 输出附加信息, 他比javap -c会输出更多的内容
下面使用命令生成一个Math.class的字节码文件. 我们将其生成到文件
javap -c Math.class > Math.txt
打开Math.txt文件, 如下. 这就是对java字节码反编译成jvm汇编语言.
Compiled from "Math.java" public class com.lxl.jvm.Math { public static int initData; public static com.lxl.jvm.User user; public com.lxl.jvm.Math(); Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return public int compute(); Code: 0: iconst_1 1: istore_1 2: iconst_2 3: istore_2 4: iload_1 5: iload_2 6: iadd 7: bipush 10 9: imul 10: istore_3 11: iload_3 12: ireturn public static void main(java.lang.String[]); Code: 0: new #2 // class com/lxl/jvm/Math 3: dup 4: invokespecial #3 // Method "<init>":()V 7: astore_1 8: aload_1 9: invokevirtual #4 // Method compute:()I 12: pop 13: return static {}; Code: 0: sipush 666 3: putstatic #5 // Field initData:I 6: new #6 // class com/lxl/jvm/User 9: dup 10: invokespecial #7 // Method com/lxl/jvm/User."<init>":()V 13: putstatic #8 // Field user:Lcom/lxl/jvm/User; 16: return }
这就是jvm生成的反编译字节码文件.
要想看懂这里面的内容, 我们需要知道jvm文档手册. 现在我们不会没关系, 参考文章(https://www.cnblogs.com/ITPower/p/13228166.html)最后面的内容, 遇到了就去后面查就行了
我们以compute()方法为例来说说这个方法是如何在在栈中处理的
源代码 public int compute() { int a = 1; int b = 2; int c = (a + b) * 10; return c;
} 反编译后的jvm指令 public int compute(); Code: 0: iconst_1 1: istore_1 2: iconst_2 3: istore_2 4: iload_1 5: iload_2 6: iadd 7: bipush 10 9: imul 10: istore_3 11: iload_3 12: ireturn
jvm的反编译代码是什么意思呢? 我们对照着查询手册
0: iconst_1 将int类型常量1压入操作数栈, 这句话的意思就是先把int a=1;中的1先压入操作数栈
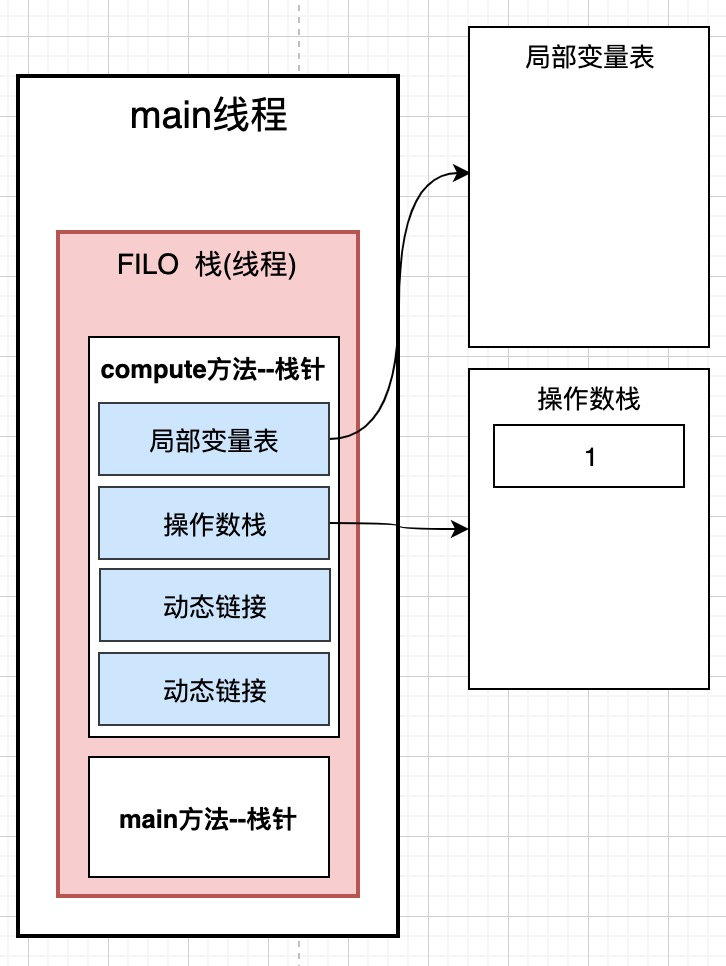
1: istore_1 将int类型值存入局部变量1-->意思是将int a=1; 中的a变量存入局部变量表
注意: 这里的1不是变量的值, 他指的是局部变量的一个下标. 我们看手册上有局部变量0,1,2,3

0表示的是this, 1表示将变量放入局部变量的第二个位置, 2表示放入第三个位置.
1: istore_1 将int类型值存入局部变量1-->意思是将int a=1; 中的a放入局部变量表的第二个位置, 然后让操作数栈中的1出栈, 赋值给a


2: iconst_2 将int类型常量2压入栈-->意思是将int b=2;中的常量2 压入操作数栈
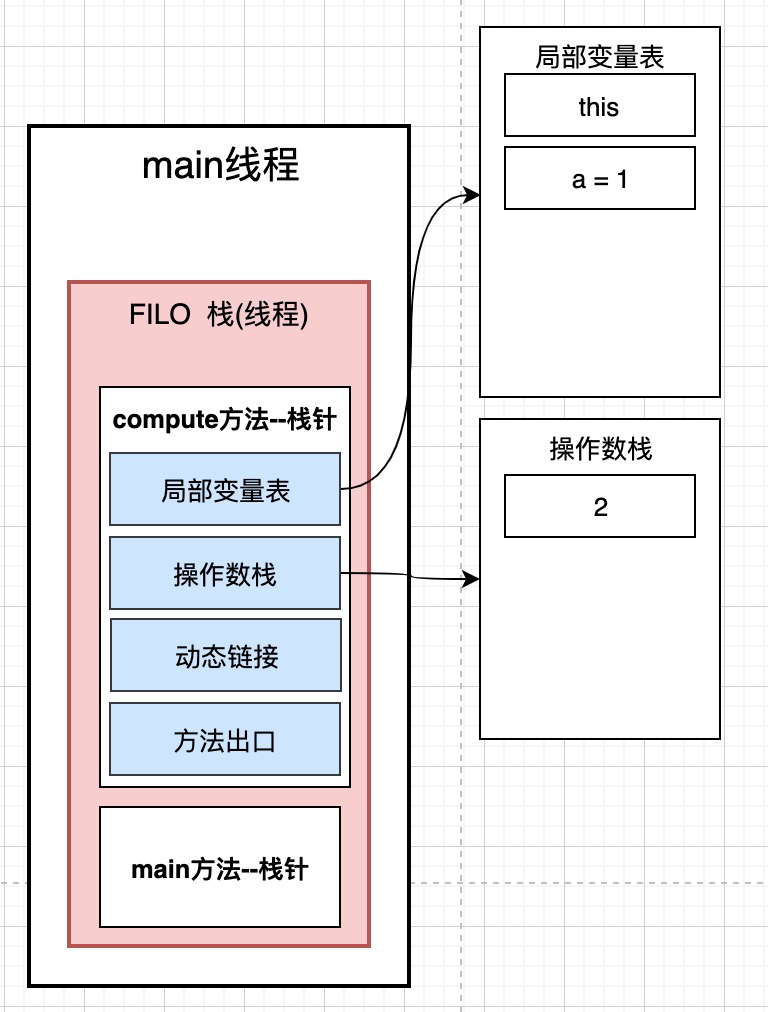
3: istore_2 将int类型值存入局部变量2 -->意思是将int b=2;中的变量b存入局部变量表中第三个位置, 然后让操作数栈中的数字2出栈, 给局部变量表中的b赋值为2

4: iload_1 从局部变量1中装载int类型值--->这句话的意思是, 将操作数1从操作数栈取出, 转入局部变量表中的a, 现在局部变量表中a=1
程序计数器: 程序计数器是每一个线程独有的, 他用来存放马上要执行的那行代码的内存位置, 也可以叫行号. 我们看到jvm反编译代码里,都会有0 1 2 3这样的位置(如下图), 我们可以将其认为是一个标识.而程序计数器可以简单理解为是记录这些数字的. 而实际上这些数字对应的是内存里的地址
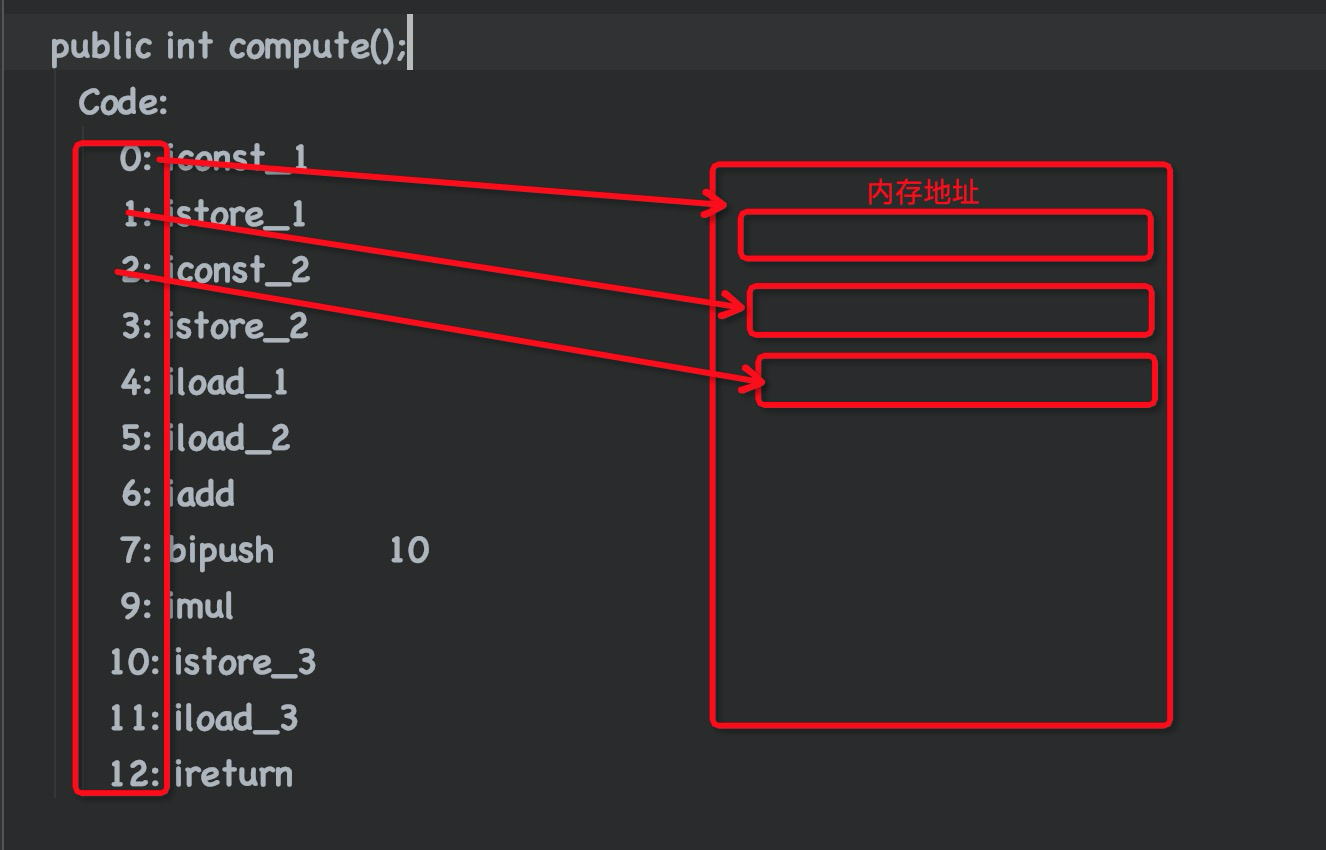
此时运行到4: iload_1, 我们可以简单理解为程序计数器记录的代码位置是4. 我们的方法Math.class是放在方法区的, 由字节码执行引擎执行, 每次执行完一行代码, 字节码执行引擎都会修改程序计数器的位置, 让其向下移动一位

java虚拟机为什么要设计程序计数器呢?
多线程, 一个线程正在执行, 然后被另一个线程抢占了cpu, 这是之前的线程就要挂起, 当线程2执行完以后, 在执行线程1. 那么线程1之前执行到哪里了呢? 程序计数器帮我们记录了.
下面执行这句话
4: iload_1 从局部变量1中装载int类型值--> 意思是从局部变量表的第二个位置取出int类型的变量值, 将其放入到操作数栈中

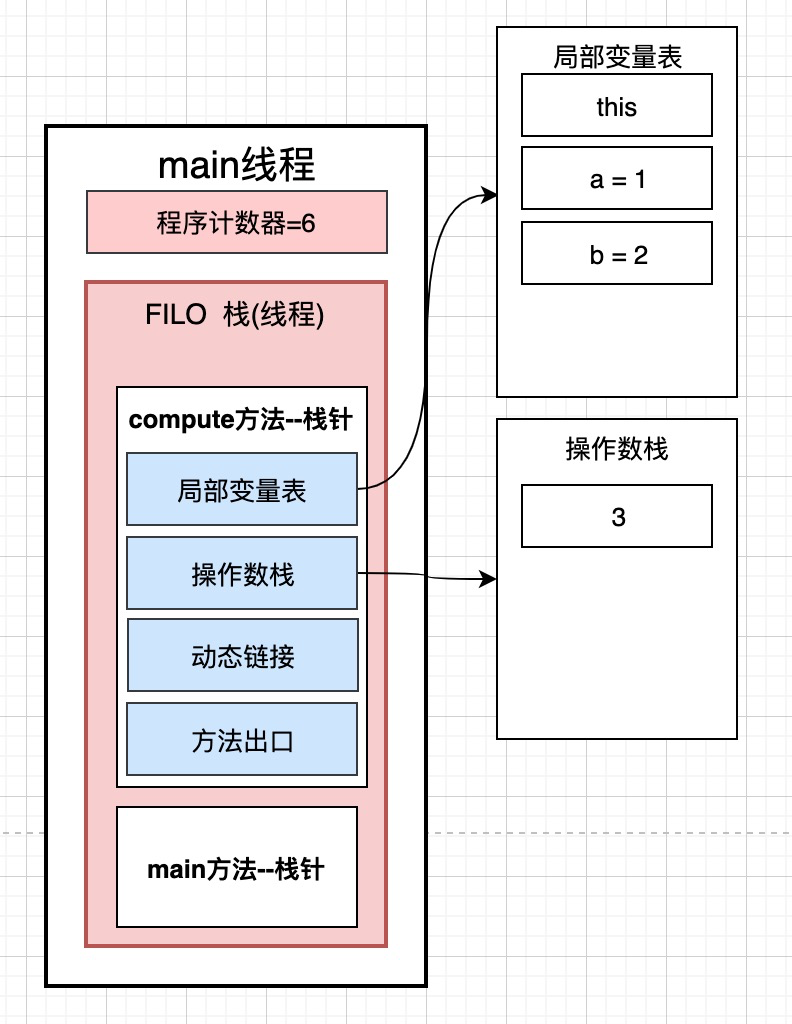
5: iload_2 从局部变量2中装载int类型值-->意思是将局部变量中的第三个int类型的元素b的值取出来, 放到操作数栈,

6: iadd 执行int类型的加法 ---> 将两个局部变量表中的数取出, 进行加法操作, 此操作是在cpu中完成的, 将执行后的结果3在放入到操作数栈 ,此时程序计数器指向的是6

7: bipush 10 :将一个8位带符号整数压入栈 --> 这句话的意思是将10压入操作数栈
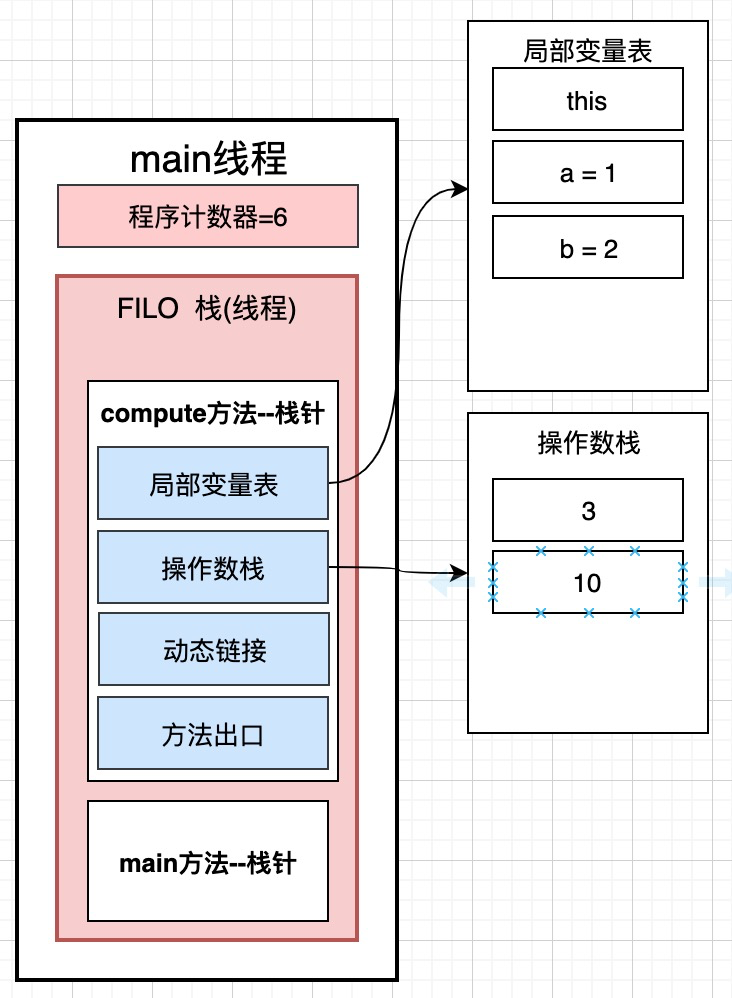
我们发现这里的位置是7, 但是下一个就变成了9, 那8哪里去了呢? 其实我们知道这里的0 1 2 3 ...都是对应的内存地址, 我们的乘数10也会占用内存空间, 所以, 8的位置存的是乘数10
9: imul 执行int类型的乘法 --> 这个和iadd加法一样, 首先将操作数栈中的3和10取出来, 在cpu里面进行计算, 将计算的结果30在放回操作数栈
乘法操作是在cpu的寄存器中进行计算的. 我们这里说的都是保存在内存中.

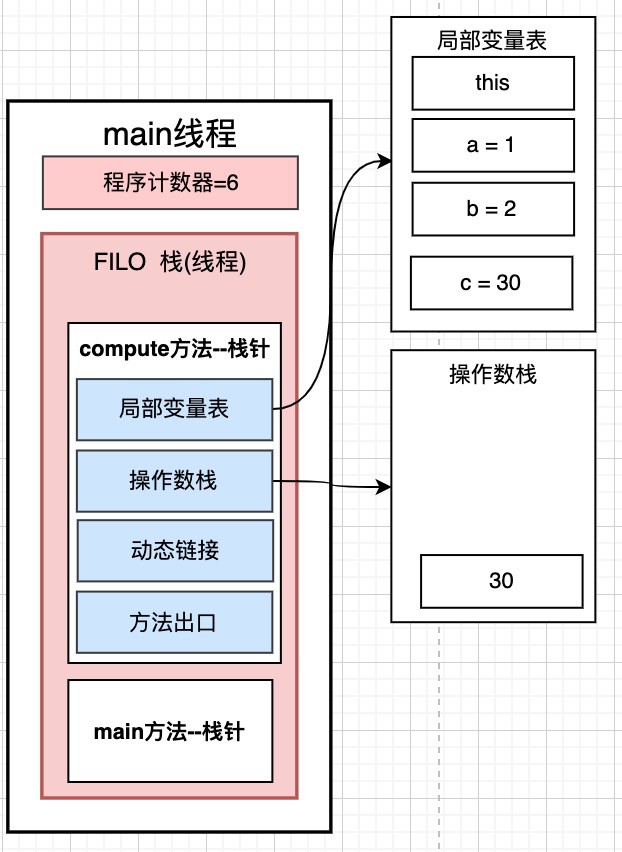
10: istore_3 将int类型值存入局部变量表中 ---> 意思是是将c这个变量放入局部变量表, 然后让操作数栈中的30出栈, 赋值给变量c
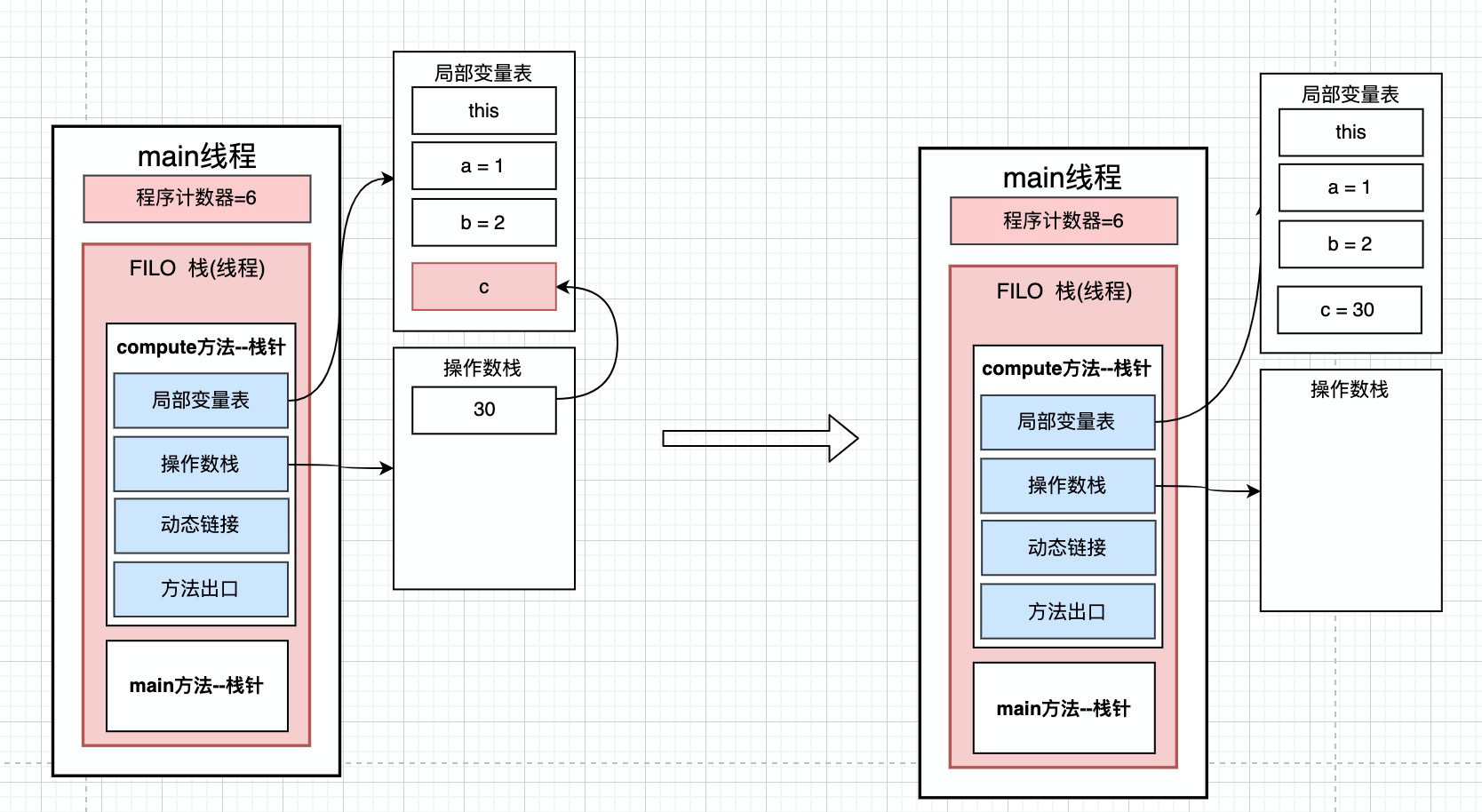
11: iload_3 从局部变量3中装载int类型值 --> 将局部变量表中取出第4个位置的值30, 装进局部变量表
12: ireturn 从方法中返回int类型的数据 --> 最后将得到的结果c返回.
这个方法中的变量是如何在操作数栈和局部变量表中转换的, 我们就知道了. 现在应该可以理解操作数栈和局部变量表是用来干嘛的了吧~~~
通过上面这个例子, 我们知道了, 什么是操作数栈?
在运算的过程中, 常数1, 2, 10, 也需要有内存空间存放, 那么它存在哪里呢? 就保存在操作数栈里面 操作数栈就是在运行的过程中, 一块临时的内存中转空间
4.3.3 动态链接
在之前说过什么是动态链接: 参考文章: https://www.cnblogs.com/ITPower/p/13197220.html 搜索:动态链接
静态链接是在程序加载的时候一同被加载进来的. 通常用静态常量, 静态方法等, 因为他们在内存地址中只有一份, 所以, 为了性能, 就直接被加载进来了
而动态链接, 是使用的时候才会被加载进来的链接, 比如compute方法. 只要在执行到math.compute()方法的时候才会真的进行加载.
4.3.4 方法出口
当我们运行完compute()方法, 还要返回到main方法的math.comput()方法的位置, 那么他怎么返回回来呢?就是方法出口里记录了, 我应该如何返回,返回到哪里. 方法出口就是记录一些方法的信息的.
5. 堆和栈的关系--
我们来看一下main方法的局部变量
public static void main(String[] args) { Math math = new Math(); math.compute(); }
main方法的局部变量和compute()有什么区别呢? main方法中的math是一个对象. 我们知道通常对象是被创建在堆里面的. 而math是在局部变量表中, 记录的是堆中new Math对象的地址
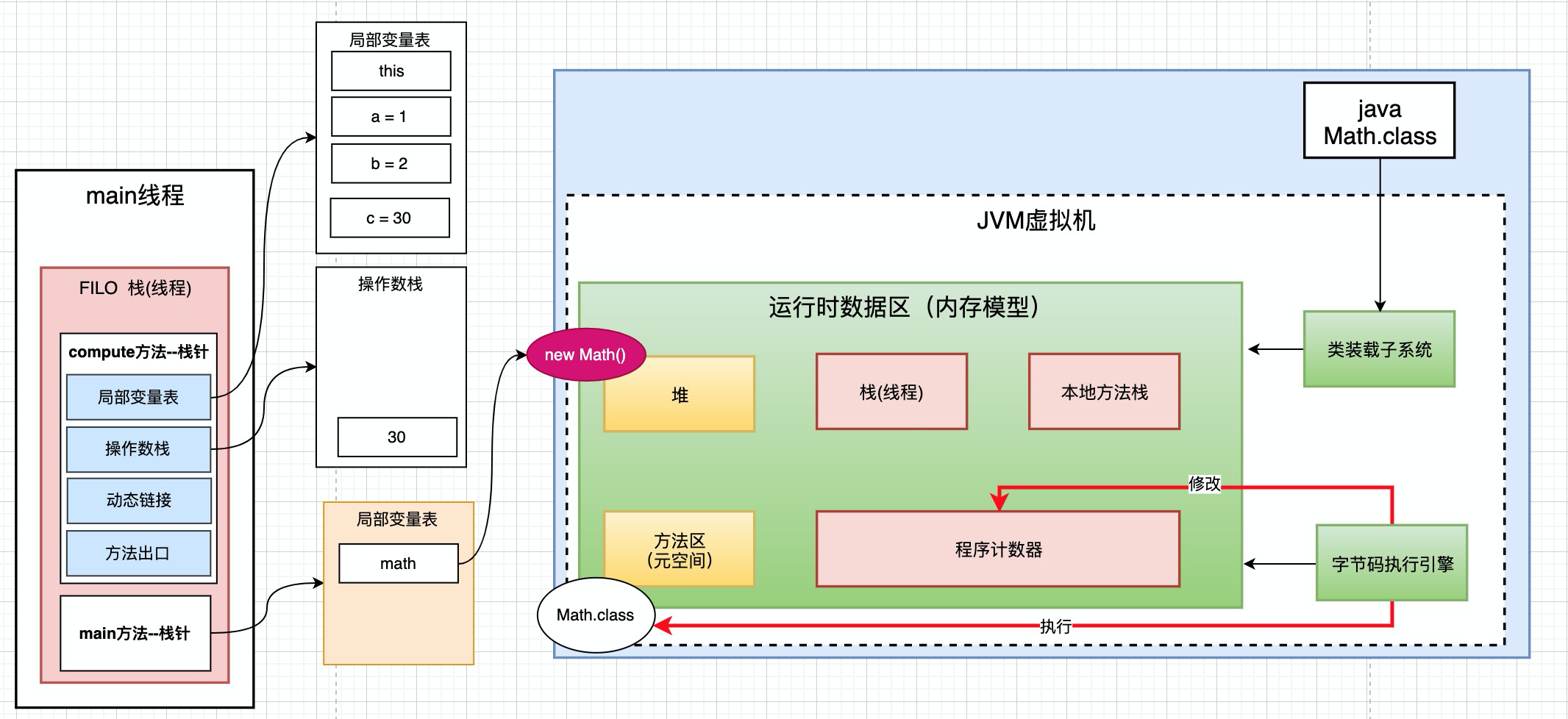
那么栈和堆的关系就出来了, 如果栈中有很多new对象, 这些对象是创建在堆里面的. 栈里面存的是这些堆中创建的对象的内存地址
6. 方法区
我们可以通过javap -v Math.class > Math.txt命令, 打印更详细的jvm反编译后的代码

这里会有一个常量池, 这个常量池的内容就放在方法区. 放在方法区的运行时空间里面.
方法区主要有哪些元素呢?
常量 + 静态变量 + 类元信息(就是类的代码信息)
在Math.class类中, 就有常量和静态常量
public static int initData = 666; public static User user = new User();
他们就方法方法区里面. 这里面 new User()是在堆里面new的, 而user对象是放在方法区里面的.
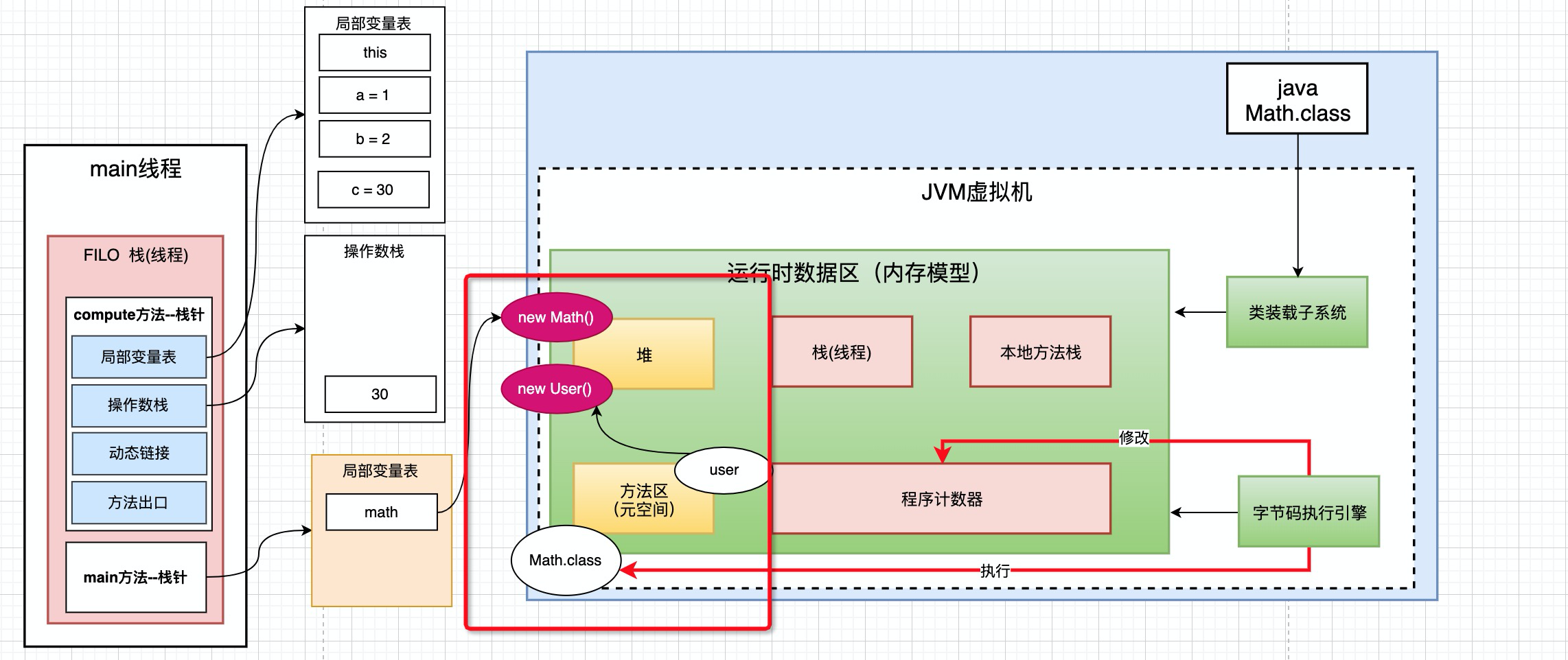
堆和方法区的关系是: 方法区中对象引用的是堆中new出来的对象的地址
类元信息: Math.class整个类中定义的内容就是类元信息, 也放在方法区
7. 本地方法栈
本地方法栈是有c++代码实现的方法. 方法名带有native的代码.
比如:
new Thread().start();
这里的start()调用的就是本地方法
这就是本地方法
本地方法栈: 运行的时候也需要有内存空间去储存, 这些内存空间就是本地方法栈提供的