报表项目中,常常会出现报表源数据来自不同数据库的情况,也就是同一张报表可能会从多个业务系统读取数据。例如:员工信息从人力资源系统中取出,销售数据从销售系统中取出。当然,还有一种可能,同一应用系统的数据库负载太大,不得已分成多个数据库,例如:销售系统数据分成当前库和历史库。
在数据库类型方面,报表工具可能连接同样类型的数据库,比如都是 oracle 或者 db2;也可能是不同的类型。
报表应用中针对这种数据分库存储的解决办法有两种:1、建设专门的数据仓库;2、利用跨库访问的技术。
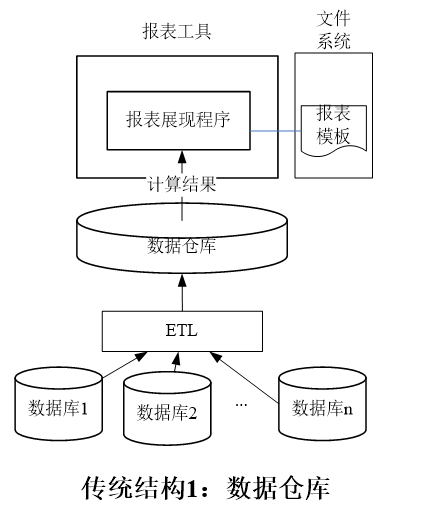
专门数据仓库的建设和管理比较复杂,如果数据量很大效率会很低,而且要持续进行 ETL 以便同步各个应用系统的数据。同时,数据仓库利用的实际上也是传统数据库的技术,当遇到负载较大的时候也会面临着进一步分库的问题。数据仓库方式结构示意图如下:
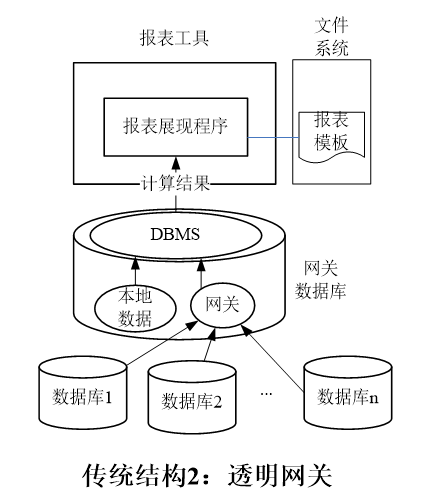
如果使用跨库访问技术,例如 Oracle 的透明网关、DB2 的联合查询等,也会遇到不少局限。比较共性的问题是:1、配置起来比较麻烦,而且往往需要数据库写权限;2、要为跨库的表配置别名;3、不同类型数据库的数据类型不一致时,比较难处理。4、sql 语句受到限制,比较难实现复杂的计算。这种方式的结构示意图如下:
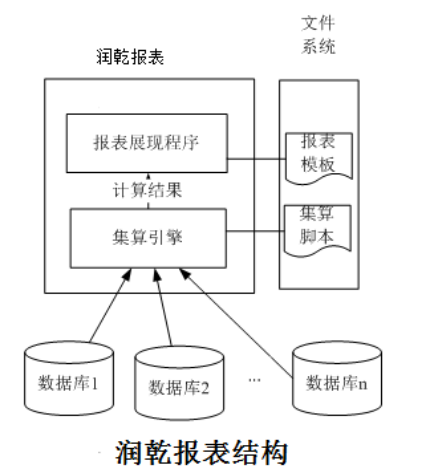
现在,有了第 3 种解决办法,也就是使用润乾报表(结合集算器实现)。其内置的集算引擎可以连接多个数据库,取数之后统一进行数据计算,从而能较好的解决报表数据取自不同数据库的问题。润乾报表解决分库存储问题的结构示意图如下:
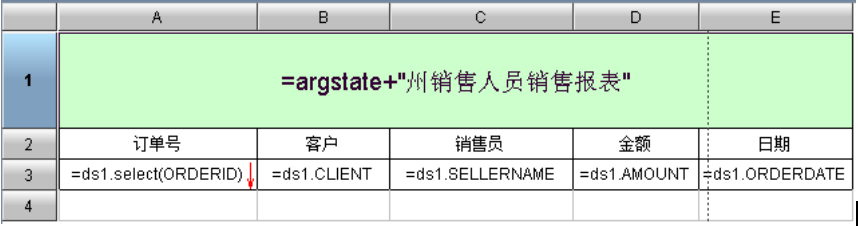
下面通过“销售人员销售报表”说明润乾报表解决数据分库存储问题的过程。报表如下图:

报表中的销售订单数据来自于销售系统的 db2 数据库,员工信息来自于人力资源系统的 db2 数据库。使用润乾报表开发这张报表的过程如下:
1、配置数据源
在润乾报表和集算器中分别配置两个数据源,销售系统数据库“db2sales”,人力资源数据库“db2HR”。
2、编写脚本
在集算器中定义网格参数 state,并编写计算脚本:
| A | |
|---|---|
| 1 | >salesdb=connect(“db2sales”) |
| 2 | >hrdb=connect(“db2HR”) |
| 3 | =salesdb.query(“select * from sales”) |
| 4 | =hrdb.query(“select * from employee”) |
| 5 | =A3.run(SELLERID=A4.select@1(EID:A3.SELLERID)) |
| 6 | =A5.select(SELLERID.STATE==state) |
| 7 | =A6.new(ORDERID,CLIENT,SELLERID.NAME:SELLERNAME,AMOUNT,ORDERDATE) |
| 8 | >salesdb.close() |
| 9 | >hrdb.close() |
| 10 | result A7 |
代码说明:
A1:连接预先配置好的 db2sales 数据源。
A2:连接预先配置好的 db2HR 数据源。
A3、A4:分别从两个数据源中读取 sales 序表和 employee 序表。
A5:使用集算器的对象引用机制,将 sales 序表和 employee 序表通过 sellerid=eid 关联。
A6:按照参数 state="California" 过滤序表。
A7:生成一个新的序表,得到需要的字段。
A8、9:关闭数据库连接。
A10:返回给集算报表。
3、配置数据集
在报表设计器中定义参数 argstate,配置集算数据集:

4、设计报表如下:
输入参数计算后,即可得到前面希望的报表。
报表上部的查询按钮使用了润乾报表提供的“参数模板”功能,具体做法参见教程,这里不再赘述。