在进行数据挖掘时,我们并不需要将所有的自变量用来建模,而是从中选择若干最重要的变量,这称为特征选择(feature selection)。本文主要介绍基于caret包的rfe()函数的特征选择。
一种算法就是后向选择,即先将所有的变量都包括在模型中,然后计算其效能(如误差、预测精度)和变量重要排序,然后保留最重要的若干变量,再次计算效能,这样反复迭代,找出合适的自变量数目。这种算法的一个缺点在于可能会存在过度拟合,所以需要在此算法外再套上一个样本划分的循环。在caret包中的rfe命令可以完成这项任务。
rfe(x, y, sizes = 2^(2:4), metric = ifelse(is.factor(y), "Accuracy", "RMSE"), maximize = ifelse(metric == "RMSE", FALSE, TRUE), rfeControl = rfeControl(), ...)
- x 训练集自变量矩阵或数据库,注意,列名必须唯一
- y 训练集的结果向量(数值型或因子型)
- sizes 对应于应该保留的特征的数量的数值向量
- metric 指定将使用什么汇总度量来选择最优模型。默认情况下,"RMSE" and "Rsquared" for regression and "Accuracy" and "Kappa" for classification
- maximize 逻辑值,metric是否最大化
- rfeControl 控制选项列表,包括拟合预测的函数。一些模型的预定义函数如下: linear regression (in the object lmFuncs), random forests (rfFuncs), naive Bayes (nbFuncs), bagged trees (treebagFuncs) and functions that can be used with caret’s train function (caretFuncs). 如果模型具有必须在每次迭代中确定的调整参数,则后者是有用的。
rfeControl(functions = NULL, rerank = FALSE, method = "boot",
saveDetails = FALSE, number = ifelse(method %in% c("cv", "repeatedcv"),
10, 25), repeats = ifelse(method %in% c("cv", "repeatedcv"), 1, number),
verbose = FALSE, returnResamp = "final", p = 0.75, index = NULL,
indexOut = NULL, timingSamps = 0, seeds = NA, allowParallel = TRUE)
functions
method 确定用什么样的抽样方法,默认提升boot,还有cv(交叉验证),LOOCV(留一交叉验证)
number folds的数量或重抽样的迭代次数
seeds 每次重抽样迭代时设置的随机种子
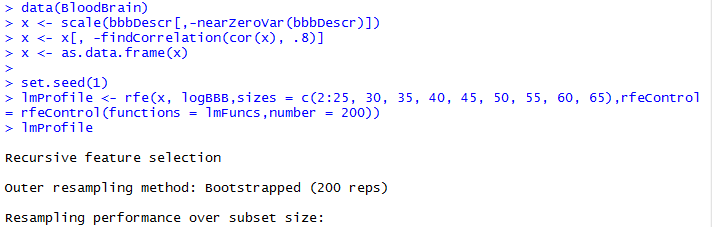
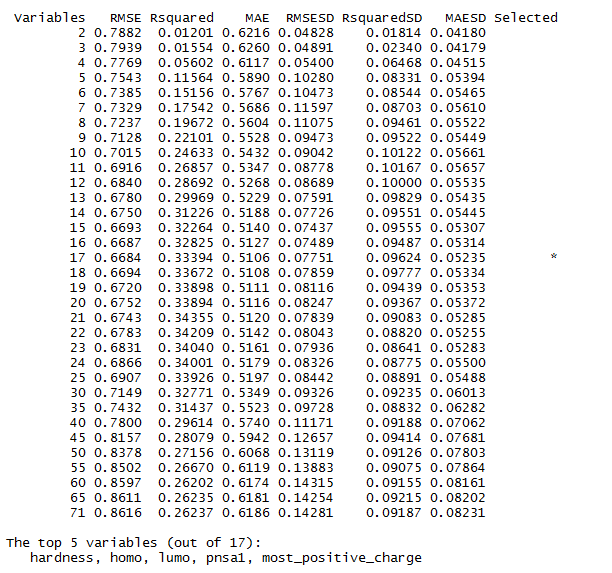

在第17个变量后面有 * 号,表明选择17个变量时,其预测精度最高
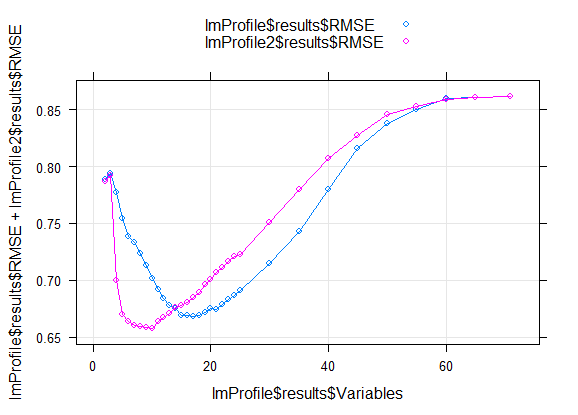
plot(lmProfile) 可观察到同样结果,如下:
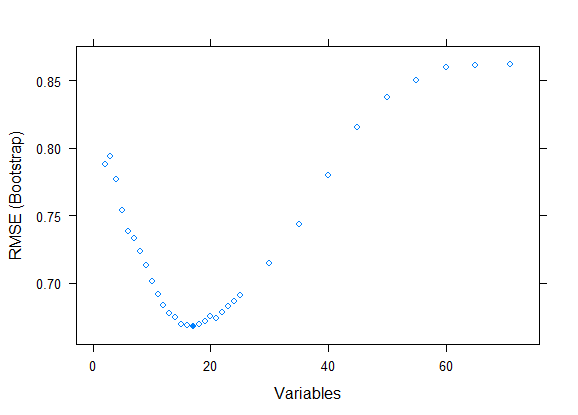
返回最终保留的自变量:

参考:
http://topepo.github.io/caret/recursive-feature-elimination.html