1、聚类-Kmeans算法应用
观察学习与生活中可以用K均值解决的问题,从数据-模型训练-测试-预测完整地完成一个应用案例。
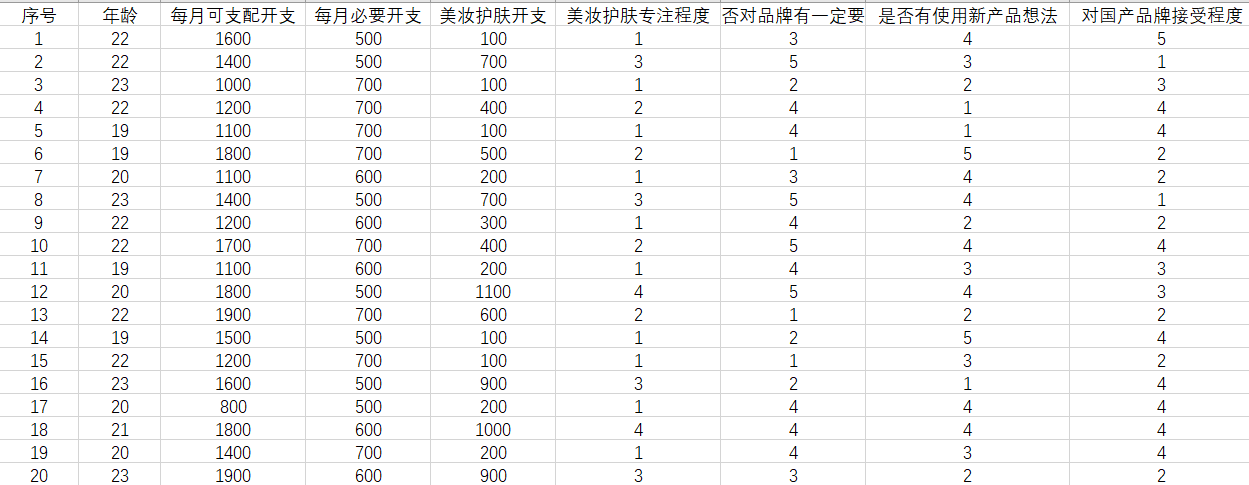
问题背景:某国产美妆公司试图开拓女大学生市场,苦于无法有效筛选出有效目标用户。根据向目标年龄段发放调查问卷后,获得了一定数据进行分类筛选。(*合计有效数据726条)
数据内容:用户年龄、用户每月可支配费用、用户每月必要开支、用户每月在美妆护肤上的开支(100以下取100,不满百向上取整至百,数值皆为大致范围),是否对品牌有一定要求,是否有使用新产品意愿,对国产品牌的接受程度(以1-5分为标准)
数据预览:
(1)读取数据,数据处理。
#1.读取处理数据 data=pd.read_excel('./data/test.xlsx') #进行数读取 print(data.isnull().any()) #查看哪一列中有空值 data=data.drop("序号",axis=1) #删除序号列 print(data)
(2)建立模型,并生成用户分类表,写入文件中。
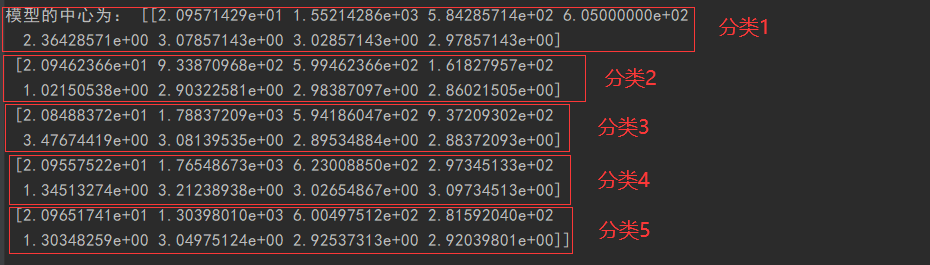
#2.构建模型 model=KMeans(n_clusters=5) #构建模型,对用户进行5类分类 model.fit(data) #模型匹配训练 pre=model.predict(data) #进行分类 print("分类结果:",pre) #查看分类结果 print("模型的中心为:",model.cluster_centers_) #查看聚类中心 a = pd.Series(['客户类1','客户类2','客户类3','客户类4','客户类5']) #创建一个序列s end = pd.concat([a,pd.Series(model.labels_).value_counts(),pd.DataFrame(model.cluster_centers_)], axis = 1) ##统计各个类别的个数,并和找出聚类中心,进行表格连接,得到聚类中心对应的类别下的数目 end.columns =['客户分类'] +['分类个数']+ list(data.columns) #重命名分类表格表头 end.to_csv("./data/客户分类表格.csv",encoding='gbk') #将表格写入文件中,方便分析


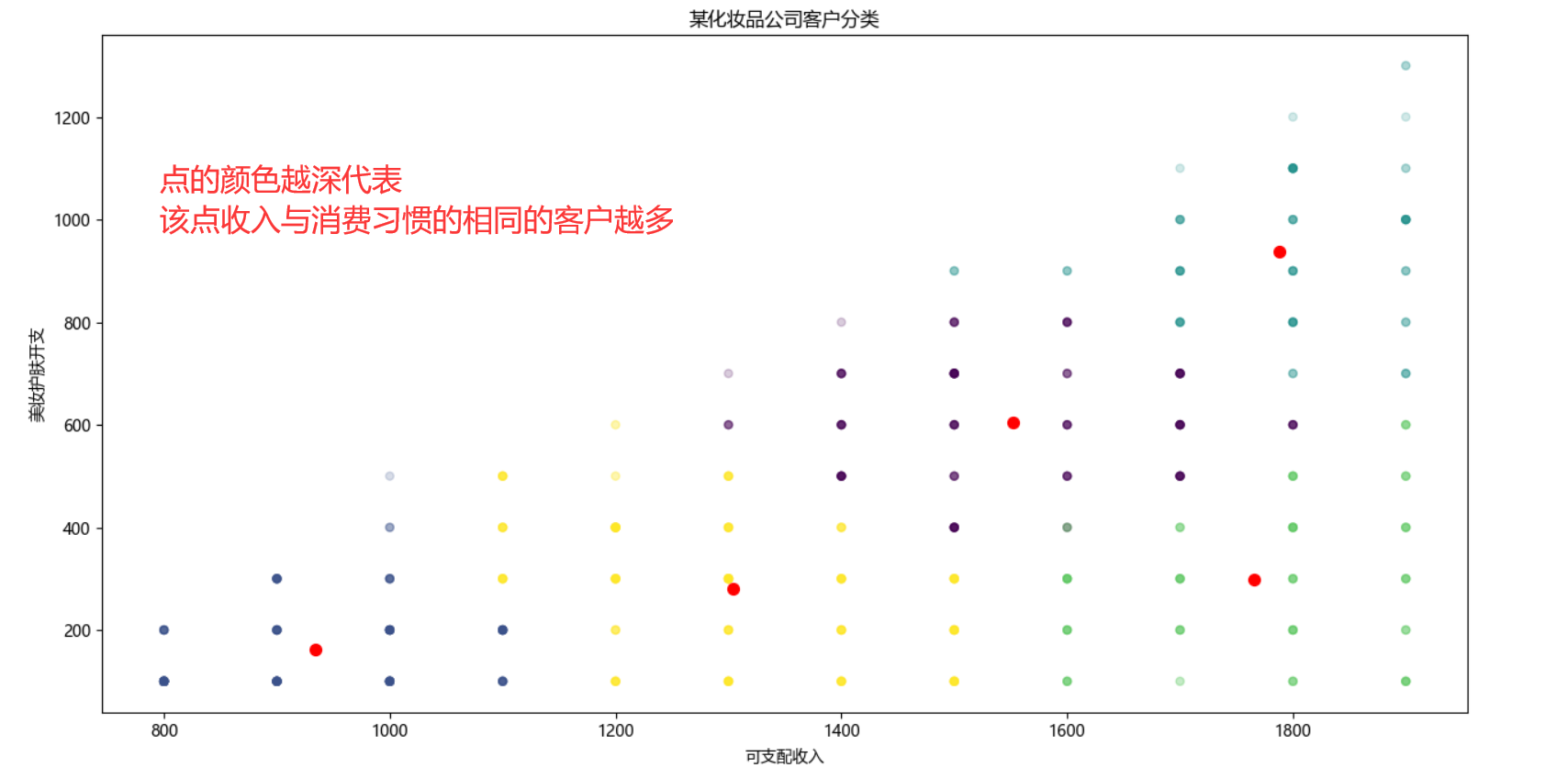
(3)绘制用户分类图
*因数据做了取整,所以导致消费习惯用户相同的客户较多。故这里对点的透明度做了调整,颜色越深的点证明改点消费习惯相同的客户越多。
#3.分类可视化 #散点作图以直观查看用户分类 mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.scatter(data.values[:,1],data.values[:,3],c=pre,s=25,alpha=0.2) #画出用户分类点 plt.scatter(model.cluster_centers_[:,1], model.cluster_centers_[:,3], s=50,color='red') #画出聚类中心 plt.title("某化妆品公司客户分类") plt.xlabel("可支配收入") plt.ylabel("美妆护肤开支") plt.show()
(4)客户分类预测
test=pd.DataFrame([[21,1200,800,300,3,3,3,2],[20,2000,800,1500,4,5,3,4],[19,1200,800,400,1,2,2,1]])#输入三组数据查看属于哪一类顾客 print("客户预测分类结果为:",model.predict(test))#输出分类结果

问题结果:进行kmeans分类后,可以看出一部分用户可支配收入高,在美妆方便也愿意投入一定的金钱。(结论皆同比)
用户分为5类,分类为第1类的客户,拥有中等可支配收入,必要开支少,愿在美妆上护肤上投入较高开支,对大牌要求为中等,使用新产品的意愿高,对国产品牌的接受程度也较高;
分类为第2类的用户,可支配收入少,必要开支中等,在美妆护肤上的投入少,护肤的专注程度低,对使用新产品的意向为中等,对国产品牌缺乏信心;
分类为第3类的用户,可支配收入高,必要开支较少,美妆护肤上的投入高,对品牌也有较高的要求,对使用新产品和使用国产品牌的想法较低;
分类为第4类的用户,可支配收入较高,必要开支高,在美妆上愿意投入中等开支,对品牌有着高要求,使用新产品的意向也较高,对国产品牌的接受程度也最高;
分类为第5类的用户,用有较少的可支配收入,必要开支较高,对美妆的开支较少,对护肤的执着程度和品牌要求也较低,不愿意使用新产品,对国牌接受程度为中等;
问题总结:综上所述,公司可以重点向客户分为类为第一类的客户可以发展为重点客户,着重向其推荐高端产品;次重点客户为第4类客户,可以多向其推荐中高端线产品;剩余3类的客户潜力较低,但也可以向其发放使用产品增强他们的用户潜力。
2、分类-朴素贝叶斯-中文文本分类
0.下载数据集
- 数据集:THUCNews中文文本数据集 http://thuctc.thunlp.org/ 按学号未位下载相应数据集。0369:时政、体育、星座、游戏、娱乐
1.对文本进行读取、分词处理,并存储进入content列表中。
- 文本预处理:遍历每个个文件夹下的每个文本文件。各种获取文件,写文件。除去噪声,如格式转换,去掉符号,整体规范化。
- jieba分词:下载、导入词库;增加专业词汇;维护自定义词库;可以用jieba.add_word('word')增加词,用jieba.load_userdict('wordDict.txt')导入词库。使用jieba分词,将中文文本进行切割。中文分词就是将一句话拆分为各个词语,因为中文分词在不同的语境中歧义较大,所以分词极其重要。
- 去掉停用词:维护停用词表——停用词表hit_stopwords.txt
2.数据划分—训练集和测试集数据划分
3.对处理之后的文本开始用TF-IDF的特征矩阵
4.贝叶斯预测种类
5.模型评价