用户数据报协议和IP分片
UDP是一种保留消息边界的简单的面向数据报的传输层协议。它仅提供差错检测。只是检测,而不是纠正,它只是把应用程序传给IP层的数据发送出去,但是并不会保证数据能够完好无损的到达目的地。
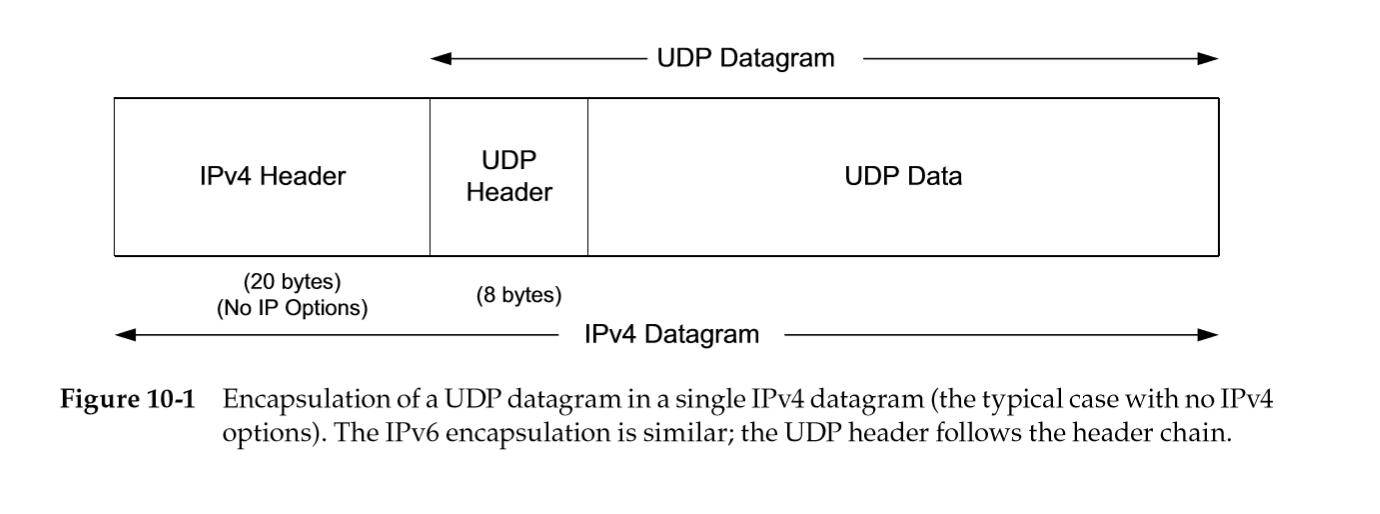
下图是UDP数据报的封装。
UDP头部
端口号就如同邮箱一样,用来辨别发送和接受进程。端口号长16比特。
UDP头部如图所示:

- 源端口号(可选),如果发送方并不要求回复,则置0
- 目的端口号,帮助分离IP层进入的数据
- 长度,UDP数据报的长度(包过头部和数据)
- 校验和
IP层根据协议头部可以将IP数据报分离到特定的传输协议。正因为如此,不同传输协议是独立的,即可以使用相同的端口号而不会引起冲突。
校验和字段是端到端的,是对包含了IP头部中的源和目的IP地址字段的UDP伪头部计算得到的,伪头部的目的是用于校验和的计算,他不会被发送出去。
UDP伪头部和头部的格式如图:

伪头部包含了IP头部的源和目的地址,以及协议或下一个头部字段。目的是让UDP层验证数据是不是到达真正的目的地,由于有了这样的结构,当该数据报经过一个NAT时候,不仅仅IP层头部的校验和要被修改,并且UDP伪头部的校验和也要被修改。
UDP-Lite
背景:有些应用程序可以容忍在发送和接收的数据里引入的比的差错。
为了避免建议连接的开销,或者为了使用广播或组播地址,这类程序会选择使用UDP。而UDP-Lit提供了部分校验和来解决这个问题。
其头部如下表示:

校验和覆盖范围字段表示被校验和覆盖的字节数。值为0表示整个数据包都被覆盖。由于整个头部总是要被覆盖的,所以值位1~7是无效的!
IP分片
为了保持IP数据报抽象与链路层细节的一致和分离,IP引入了分片和重组。
- IPv4的分片可以在发送主机和端到端路径上的路由器进行
- IPv6只允许源主机进行分片
重组只能发生在IP数据报到达最终目的地的时候。原因很显然,不同分片可能会经过不同的路径到达目的地,在路径上的路由器只能看到分片的一个子集,显然无法重组。
分片由IPV4头部中的标识,分片偏移,和更多分片字段控制。
- 标识,由原始发送方设置,在目的地依据标识区分组
- 分片偏移,表示分片中数据的第一个字节在原数据报的偏移量(8个字节为单位)
- 更多分片(MF),0表示最后一个分片,否则为1。
偏移的具体内容如下图所示:

第二个数据报偏移为185*8=1480=第一个分片负载,即在第一个分片零偏移的基础上偏移了185个单位。
当TCP报文段的一个分片丢失了,TCP会重传整个报文段,而重传一个分片是不可能的,因为在路径路由器可以分片数据报,源主机是不清楚数据报如何被分片的。
- 具有更大偏移量的分片要比第一个分片更优先投递,这样有利于接收主机确定所需的缓存空间最大值
- 收到任何一个分片,IP层就启动计时器,超时即丢弃数据报。
- UDP数据报长度有限,满额数据报并不能很好的被投递
- 本地协议实现的限制
- 接受应用程序并没有做好准备接收处理这么大的数据报