Matplotlib里有两种画散点图的方法,一种是用ax.plot画,一种是用ax.scatter画。
一. 用ax.plot画
ax.plot(x,y,marker="o",color="black")
二. 用ax.scatter画
ax.scatter(x,y,marker="o",s=sizes,c=colors)
ax.plot和ax.scatter的区别:
ax.plot:各散点彼此复制,因此整个数据集中所有的点只需配置一次颜色和大小。对大型数据集而言,ax.plot方法效率更高。
ax.scatter:灵活性高,可以单独控制每个散点,使其具有不同的属性(大小,填充颜色,边框颜色等)。
下面利用Nathan Yau所著的《鲜活的数据:数据可视化指南》一书中的数据,学习画图。
数据地址:http://datasets.flowingdata.com/flowingdata_subscribers.csv (用于散点图)
http://datasets.flowingdata.com/crimeRatesByState2005.csv(用于气泡图)
准备工作:先导入matplotlib和pandas,用pandas读取csv文件,然后创建一个图像和一个坐标轴
import pandas as pd from matplotlib import pyplot as plt subscriber=pd.read_csv(r"http://datasets.flowingdata.com/flowingdata_subscribers.csv")
fig,ax=plt.subplots()
让我们先看看第一个数据文件的前5行:
Date Subscribers Reach Item Views Hits
0 01-01-2010 25047 4627 9682 27225
1 01-02-2010 25204 1676 5434 28042
2 01-03-2010 25491 1485 6318 29824
3 01-04-2010 26503 6290 17238 48911
4 01-05-2010 26654 6544 16224 45521
我们把文件中的订阅人数根据日期的推进画出来:
import pandas as pd from matplotlib import pyplot as plt subscriber=pd.read_csv(r"http://datasets.flowingdata.com/flowingdata_subscribers.csv") fig,ax=plt.subplots() time=[pd.to_datetime(i) for i in subscriber["Date"]] ax.plot(time,subscriber["Subscribers"],"o",color="blue") ax.set(xlabel="Date",ylabel="Number of subsribers") ax.set_title("Growth of subscribers --- Jan 2010") ax.annotate("2 days where it went wrong",xy=(0.43,0.06),xycoords='axes fraction', xytext=(0.56,0.1),textcoords='axes fraction', arrowprops=dict(facecolor='black', shrink=0.05)) ax.annotate("25047",xy=(0.046,0.8),xycoords='axes fraction', xytext=(0.004,0.68),textcoords='axes fraction', arrowprops=dict(arrowstyle="-")) ax.annotate("27611 (+10%)",xy=(0.955,0.92),xycoords='axes fraction', xytext=(0.905,0.76),textcoords='axes fraction', arrowprops=dict(arrowstyle="-")) ax.spines["left"].set_visible(False) ax.spines["right"].set_visible(False) ax.spines["top"].set_visible(False) plt.show()
图像如下:
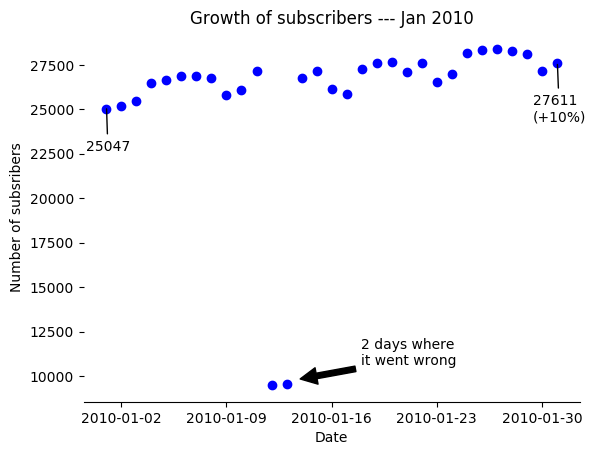
可以看到有两个点情况异常,由于原因未知,添加注释进行说明。
接下来看看第二个数据文件的前5行:
state murder forcible_rape robbery aggravated_assault 0 United States 5.6 31.7 140.7 291.1 1 Alabama 8.2 34.3 141.4 247.8 2 Alaska 4.8 81.1 80.9 465.1 3 Arizona 7.5 33.8 144.4 327.4 4 Arkansas 6.7 42.9 91.1 386.8 burglary larceny_theft motor_vehicle_theft population 0 726.7 2286.3 416.7 295753151 1 953.8 2650.0 288.3 4545049 2 622.5 2599.1 391.0 669488 3 948.4 2965.2 924.4 5974834 4 1084.6 2711.2 262.1 2776221
这是美国各州各种犯罪行为的发生率(每10万人口)。
让我们看看各州谋杀率和入室盗窃率之间是否有关联,同时把各州的人口也显示出来,看看人口多的州是否这两种犯罪率同时也高。
首先把第一行United States的平均数据去除,然后把population,state,murder,burglary这几项数据分别拣出。在scatter命令中,以murder为x轴,burglary为y轴,s(气泡面积)按population调整,alpha为透明度。其中有一个州的谋杀率特别高,因此把x轴的上下限调整一下,以便更好地看出谋杀率和入室盗窃率之间的关系。这样,一个三维图像就画了出来。
import pandas as pd from matplotlib import pyplot as plt crime=pd.read_csv(r"http://datasets.flowingdata.com/crimeRatesByState2005.csv") fig,ax=plt.subplots(figsize=(10,5)) crime=crime[1:] population=crime["population"].values state=crime["state"].values murder=crime["murder"].values burglary=crime["burglary"].values ax.scatter(murder,burglary,s=population/40000,alpha=0.6) ax.set(xlim=(0,11),ylim=(200,1300), xlabel="Murder per 100,000 population", ylabel="Burglary per 100,000 population", title="Murder & Burglary in USA") for i,j,z in zip(murder,burglary,state): ax.text(x=i-0.3,y=j-0.1,s=z,fontsize=7) ax.spines["top"].set_visible(False) ax.spines["left"].set_visible(False) ax.spines["right"].set_visible(False) plt.show()
图像如下:
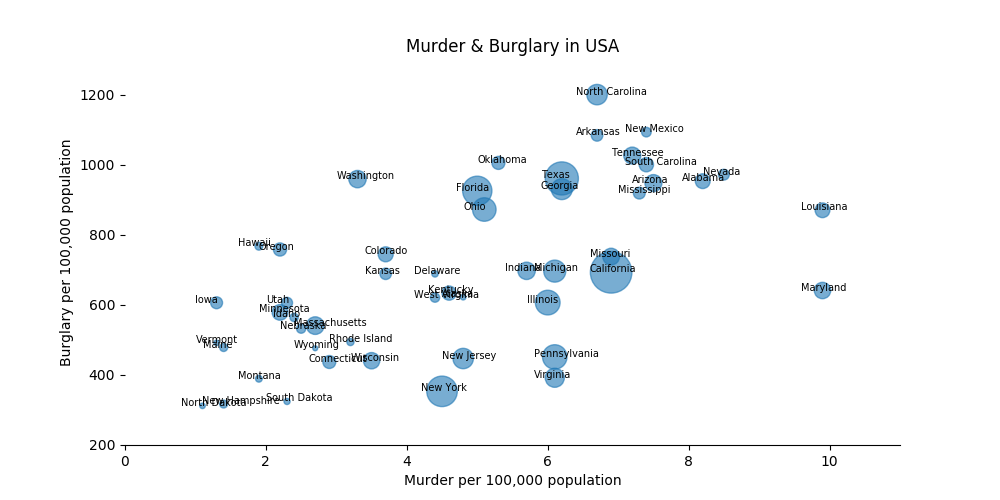
可以看出谋杀率和入室盗窃率之间是呈正比关系的,但是人口多的州并非这两种犯罪率就高。
此外,可以通过设置scatter命令中的c(颜色)参数,进而来展示四维图像。