Java程序设计结构
Java基本数据类型
Java原生有8种基本数据类型:整型(int short long byte)浮点型(double float)字符型(char)布尔型(boolean)。注意:在Java中没有任何无符号(unsigned)形式的int long short 或byte类型。特别注意char是两个字节的,范围是0~65535,存的是Unicode编码(强烈建议不要在程序中使用char类型,除非确实要处理UTF-16代码单元。最好将字符串作为抽象数据类型处理)。short是两个字节,int是四个字节,long是八个字节,类型大小是固定的,与平台无关。boolean类型有两个值:false和true,用来判断逻辑条件。整型值和布尔值之间不能进行互相转换。
public class BasicTypeDemo {
public static void main(String[] args){
System.out.println("Byte");
System.out.println(Byte.MIN_VALUE); // -128
System.out.println(Byte.MAX_VALUE); // 127
System.out.println("Short");
System.out.println(Short.MIN_VALUE); // -32768
System.out.println(Short.MAX_VALUE); // 32767
System.out.println("Character");
System.out.println((int)Character.MIN_VALUE); // 0
System.out.println((int)Character.MAX_VALUE); // 65535
System.out.println("Integer");
System.out.println(Integer.MIN_VALUE); // -2147483648
System.out.println(Integer.MAX_VALUE); // 2147483647
System.out.println("Long");
System.out.println(Long.MIN_VALUE); // -9223372036854775808
System.out.println(Long.MAX_VALUE); // 9223372036854775807
System.out.println("Float");
System.out.println(Float.MIN_VALUE); // 1.4E-45, 最小精度值,而不是最小值(-Float.MAX_VALUE)
System.out.println(Float.MAX_VALUE); // 3.4028235E38
System.out.println("Double");
System.out.println(Double.MIN_VALUE); // 4.9E-324,最小精度值,而不是最小值(-Double.MAX_VALUE)
System.out.println(Double.MAX_VALUE); // 1.7976931348623157E308
}
但在实际使用过程中往往需要基本数据类型的包装类。严格来说Java并不是纯的面向对象的编程语言,因为其基本数据类型不是对象。但是可以通过包装类进行转换。这样基本数据类型就可以当作对象来使用。
| 基本数据类型 | 包装类 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
| boolean | Boolean |
控制流程
Java流程控制包括顺序控制、条件控制和循环控制。顺序控制就是按顺序执行代码.Java条件控制有两种,循环控制有三种.
//if条件语句
if(condition1){
...
}else if(condition2){
...
}else{
...
}
//switch条件语句
switch(condition){
case label1:
...;
break;
case label2:
...;
break;
...
default:
...;
break;
}
/*这里注意condition和label的类型可以是1.char,byte,short,int(或者他们的包装类)
2.枚举常量
3.Java SE7之后label还可以是字符串字面量.
*/
/*
switch的执行过程:
按顺序判断condition与label的值是否相等,如果相等则执行该label下的语句,如果不相等,则继续判断,知道所有的都判断完了,还没有相等,则执行default下的语句.当中间有匹配的label,执行完该label下的语句之后,如果有break;则跳出switch语句,不再往下执行.如果没有,则继续执行下面的语句.
*/
//for循环
for(计数器初始化; 循环条件; 如何更新计数器){
...
}
//while循环
while(循环条件){
...
}
//do...while循环
do{
...
}
while(循环条件);
break和continue
break跳出循环
continue跳出本次循环,继续执行下次循环
//break示例
for(int i = 0;i<=6;i++){
if(i == 3)break;
System.out.println("The number is:"+i);
}
结果为:
The number is:0
The number is:1
The number is:2
//continue示例
for(int i = 0;i<=5;i++){
if(i = =3)continue;
System.out.println("The number is:"+i);
}
结果为:
The number is:0
The number is:1
The number is:2
The number is:4
The number is:5
/*当有多层循环时,我们要跳出指定循环可以在循环前面设置标签,然后break 标签,就可以跳出指定循环.同理continue 标签,类似.
*/
数组
Java语言中提供的数组是用来存储固定大小的同类型元素。
int[] a;//声明数组
//int a[];(这种方法也可以但是推荐使用上面的那种,增强可读性,类型和变量更清晰)
a = new int[5];//创建数组,这里用new来创建一个数组。中括号里指明数组大小.
int[] b = {1, 2, 3, 4, 5};//直接初始化数组来创建数组。
//数组遍历可以用for循环带下标的遍历,也可以用如下方式不用下标遍历,这样遍历可以防止数组越界。
for(int i : b){
System.out.print(i + " ");
}
Arrays类
java.util.Arrays类能方便的操作数组,它所有的方法都是静态的。
1.filll方法 :给数组中的某段元素附上相同值。
2.sort方法:对数组中某段元素排序。
3.equals方法:比较两个数组,判断的是数组中元素值是否相等。
4.binarySearch方法:对排过序的数组进行二分法查找。
import java.util.Arrays;
public class UsingArrays {
/*
数组输出
*/
public static void output(int[] array){
if(array != null){
for(int i = 0 ; i < array.length; i++){
System.out.println(array[i] + " ");
}
}
System.out.println();
}
public static void main(String[] args){
//填充数组,将array[]中所有元素的值初始为0
int[] array0 = new int[5];
Arrays.fill(array0,5);
System.out.println("调用Arrays.fill(array0,5)后:");
UsingArrays.output(array0);
//将array0中的第2个到第三个元素的值赋为8
Arrays.fill(array0, 2, 4, 8);
System.out.println("调用Arrays.fill(array0,0,2,4,8)后:");
UsingArrays.output(array0);
//对数组进行排序
int[] array1 = new int[] { 7, 8, 3, 12, 6, 3, 5, 4};
//对数组的第二个到第6个元素进行排序
Arrays.sort(array1, 2, 7);
System.out.println("调用Arrays.sort(array1, 2, 7)后:");
UsingArrays.output(array1);
//对整个数组进行排序
Arrays.sort(array1);
System.out.println("调用Arrays.sort(array)后:");
UsingArrays.output(array1);
//比较数组元素是否相等
System.out.println(Arrays.equals(array0,array1));
int[] array2 = (int[]) array1.clone();
System.out.println("array1和array2是否相等?"
+ Arrays.equals(array1,array2));
//使用二分法在数组中查找指定元素所在的下标
//数组必须是先排好序的
Arrays.sort(array1);
System.out.println("元素3在array1中的位置:"
+ Arrays.binarySearch(array1,3));
//如果不存在,就返回负数
System.out.println("元素9在array1中的位置:"
+ Arrays.binarySearch(array1,9));
}
}
Java面向对象
Java面向对象有三大特点:继承(只能单一继承,不能多继承)封装(对象数据和操作该对象的指令都是对象自身的一部分,能够实现尽可能对外部隐藏数据。) 多态。
类和对象
什么是类?类是构造对象的模板或蓝图。什么是对象?是由类创建的实例,即通过类模板来创建具体的对象实例。对象有三个主要特征:对象的行为(可以对该对象施加那些操作或者说对象中包含哪些方法)对象的状态(施加方法后对象如何响应,体现在对象数据内容的变换)对象的标识(辨别具有相同行为与状态的不同对象,通常使用不同的对象变量)
/*
* 对象和类的基础演示
*/
//类的创建
class Student{
//定义数据域
private String name;
private int age;
private final int number;//由于被final修饰值确定后无法改变,只能被赋值一次。
public static final String SCHOOLNAME = "HNUST"; //定义静态常量,一般很少使用静态变量,静态常量是属于类的数据,可在外部通过类名访问,由于被final修饰值确定后无法改变
//对于final关键词修饰对象只是表示存储在变量中的对象引用不会再指示其他对象。不过对象可以改变。
/*
* 创建构造函数或者说是构造器
* 要求:构造器与类同名,每个类有一个以上的构造起,构造器可以有0个以上的参数,构造器没有返回值,构造器总是伴随着new操作一起调用
* */
public Student(String name, int age, int number){
this.name = name; //this表示隐式参数,this用途:使用this关键字引用成员变量,使用this关键字在自身构造方法内部引用其它构造方法,使用this关键字代表自身类的对象,使用this关键字引用成员方法
this.age = age;
this.number = number;
}
//构造器重载:下面的是无参数构造器,会设置对象的初始值。
public Student(){
this.name = "";
this.age = 0;
this.number = 0;
}
//在一个构造器中调用另一个构造器,需要this()来进行调用。并且放在当前构造器的第一行。
//定义方法
//更改器方法
public void setName(String name){
this.name = name;
}
public void setAge(int age){
this.age = age;
}
//访问器方法:只访问对象不改变对象
public String getName(){
return this.name;
}
public int getAge(){
return this.age;
}
public int getNumber(){
return this.number;
}
//静态方法:静态方法属于类,不属于某个对象。静态方法只能操作静态域。
public static String getSchool(){
return SCHOOLNAME;
}
}
//java中总是采用按值调用。方法的到的是所有参数值的一个拷贝,特别是方法不能改变传递给他的任何参数变量的内容。一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不同了,就相当于指针。
//Java中方法参数使用:方法不能改变一个基本数据类型的参数,方法可以改变一个对象参数的状态,方法不能让对象参数引用一个新的对象。
public class Main {
public static void main(String[] args) {
Student student = new Student("hank", 20, 6);
System.out.println(student.getName() + " " + student.getAge() + " " + student.getNumber() + " " + Student.getSchool());
student.setAge(21);
student.setName("hkh");
System.out.println(student.getName() + " " + student.getAge() + " " + student.getNumber() + " " + Student.getSchool());
}
}
类的设计技巧:1、一定要保证数据私有。2、一定要对数据初始化。3、不要再类中使用过多的基本数据类型。4、不是所有域都需要独立的域访问器和域更改器。5、将职责过多的类进行分解。6、类名和类方法要能够体现他们的职责。7、优先使用不可变类。
封装
通过封装,可以实现对属性的数据访问限制,同时增加了程序的安全性。
如何实现封装
(1)、修改属性的可见性来限制对属性的访问。
(2)、为每个属性创建一对赋值方法和取值方法,用于对这些属性的访问。
(3)、在赋值和取值方法中,加入对属性的存取的限制。
Java访问权限
private: Java语言中对访问权限限制的最窄的修饰符,一般称之为“私有的”。被其修饰的属性以及方法只能被该类的对象访问,其子类不能访问,更不能允许跨包访问。
default:即不加任何访问修饰符,通常称为“默认访问权限“或者“包访问权限”。该模式下,只允许在同一个包中进行访问。
protected: 介于public 和 private 之间的一种访问修饰符,一般称之为“保护访问权限”。被其修饰的属性以及方法只能被类本身的方法及子类访问,即使子类在不同的包中也可以访问。
public: Java语言中访问限制最宽的修饰符,一般称之为“公共的”。被其修饰的类、属性以及方法不仅可以跨类访问,而且允许跨包访问。
继承
类的继承,可以实现复用已有类的方法和域。关键字extends表明正在构造的新类派生于一个已存在的类。已存在的类称为超类,基类,或父类。新类称为子类,派生类或孩子类。
/*
* 类的继承
*/
class Animal{
private String name = "";
private int age = 0;
public Animal(String name, int age){
this.name = name;
this.age = age;
}
public String getName(){
return this.name;
}
public int getAge(){
return this.age;
}
public void act(){
System.out.println("我能动···");
}
}
class Bird extends Animal{
private int weight;
public Bird(String name, int age, int weight){
super(name, age); //通过super关键词对父类构造器的调用
this.weight = weight;
}
public int getWeight() {
return weight;
}
//对父类方法的覆盖重写
public void act(){
System.out.println("我能飞···");
}
}
public class Main {
public static void main(String[] args) {
Bird bird = new Bird("hank", 2, 10);
System.out.println(bird.getName());//Bird可以继承Animal的方法。
System.out.println(bird.getAge());
System.out.println(bird.getWeight());
bird.act();//Bird可以覆盖掉Animal的方法。
}
}
父类对象与子类对象之间的相互转换问题:
- 从子类转换为父类就比较直观。因为在继承关系中“is-a”,很明确的指出子类肯定是父类,例如:Bird肯定是Animal一样。那么就可以直接将子类对象赋值给父类对象变量。
- 从父类转换为子类则需要进行强制类型转换,再将父类对象赋值给子类变量。(只能在继承层次中进行类型转换。将父类转换为子类之前,应当使用instanceof进行检查,尽量少使用)
理解方法调用:
- 编译器查看对象的声明类型和方法名。
- 编译器将查看调用方法时提供的参数类型。(次二步用来确定调用哪一个方法)
- 如果是private方法static方法final方法或者构造器,那么编译器将可以准确的知道调用哪个方法,这种调用方式称为静态绑定(在程序运行前就已经知道方法是属于那个类的,在编译的时候就可以连接到类的中,定位到这个方法。在Java中,final、private、static修饰的方法以及构造函数都是静态绑定的,不需程序运行,不需具体的实例对象就可以知道这个方法的具体内容。)。与此对应的便是动态绑定(在程序运行过程中,根据具体的实例对象才能具体确定是哪个方法。)动态绑定是多态性得以实现的重要因素,它通过方法表来实现:每个类被加载到虚拟机时,在方法区保存元数据,其中,包括一个叫做 方法表(method table)的东西,表中记录了这个类定义的方法的指针,每个表项指向一个具体的方法代码。如果这个类重写了父类中的某个方法,则对应表项指向新的代码实现处。从父类继承来的方法位于子类定义的方法的前面。(绑定:把一个方法与其所在的类/对象 关联起来叫做方法的绑定。绑定分为静态绑定(前期绑定)和动态绑定(后期绑定))。
注意:子类继承父类的结果:
1.子类继承父类后,继承到了父类所有的属性和方法。 注:是所有
2.子类可调用的方法也要看情况而定:
子类和父类在同一个包下时 “子类和子类的对象”可以调用父类的默认的,受保护的,公有的属性以及方法
子类和父类在不同的包下时,在子类中可以调用受保护的,公有的属性以及方法,而子类的对象可以调用受保护的,公有的属性以及方法。
方法的重写:
1.当子类和父类都有某种方法,而子类的方法更加要求细致,或者实现功能不同,就需要方法的重写
2.重写条件:
1.必须要存在继承关系;
只有继承之间的关系才能有方法的重写
2.方法的返回值类型,方法名,参数个数,参数类型,参数顺序
继承的设计技巧:
1、将公共操作和域放在超类
2、不要使用受保护的类
3、使用继承实现“is-a”关系
4、除非所有继承的方法都有意义,否则不要使用继承
5、在覆盖方法时,不要改变预期的行为
6、尽量使用多态
7、不要过多的使用反射(关于反射日后再做详细讨论)
多态
定义:
多态:指允许不同类的对象对同一消息做出响应。即同一消息可以根据发送对象的不同而采用多种不同的行为方式。(发送消息就是函数调用)
实现多态的技术称为:动态绑定(dynamic binding),是指在执行期间判断所引用对象的实际类型,根据其实际的类型调用其相应的方法。
作用:消除类型之间的耦合关系。
下面是多态存在的三个必要条件
多态存在的三个必要条件:
1.要有继承;
2.要有重写;
3.父类引用指向子类对象。
Java中多态的实现方式:接口实现,继承父类进行方法重写,同一个类中进行方法重载。
抽象类
抽象类:
抽象类是具有普遍通用性的类。包含一个或多个抽象方法(用abstract修饰的方法)的类为抽象类,并且必须用abstract修饰该类。抽象方法充当着占位的角色,他们的具体实现在子类中。扩展抽象类可以有两种选择:1、在抽象类中定义部分抽象方法或不定义抽象方法,这样子类就必须标记为抽象类。2、定义全部的抽象方法,这样子类就不是抽象类了。
注意:抽象类不能被实例化,但是它的子类可以创建对象。
接口
接口:在Java中接口不是类是对类的一组需求描述。在接口中所有的方法自动地属于public,并且在接口声明时不必提供关键字public。实现接口的步骤:
- 将类声明为实现给定的接口。
- 对接口中所有的方法进行实现。(实现接口时必须将方法声明为public)
接口的特性:
- 接口不是类,尤其不能使用new实例化一个接口。但是接口能声明接口的变量。接口的变量必须引用实现了接口类的对象(这不是接口变量,而是一个接口类型的引用指向了一个实现给接口的对 象,这是java中的一种多态现象。java中的接口不能被实例化,但是可以通过接口引用指向一个对象,这样通过接口来调用方法可以屏蔽掉具体的方法的实现,这是在JAVA编程中经常用到的接口回调,也就是经常说的面向接口的编程)。
- 接口中不能包含实例域或静态方法,但是可以包含常量。与接口方法一样,接口中的域将被自动的设为public static final。按照Java语言规范在程序中不要书写多余的关键字。
- 一个类只能拥有一个父类,但可以实现多个接口(这解决了Java多继承的一部分问题)。
接口中的默认方法:在声明方法时使用defaul声明默认方法。在实现接口时就只需要考虑需要的方法就行了不必实现所有的接口方法。
超类与接口同名方法的冲突处理:1、超类优先。2、对于不同接口的同名方法,超接口将会被覆盖。
内部类
内部类是定义在另一个类中的类。为什么需要内部类呢?主要原因:
- 每个内部类都能独立地继承自一个接口的实现,所以无论外围类是否已经继承了某个接口的实现,对于内部类都没有影响(内部类可以有效的实现“多重继承”)
- 内部类方法可以访问该类定义所在的作用域的数据,包括私有的数据。
- 内部类可以对同一个包中的其他类隐藏起来。4、当要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。
成员内部类
定义在另一个类(外部类)的内部,而且与成员方法和属性平级叫成员内部类,相当于外部类的非静态方法,如果被static修饰,就变成静态内部类了。
/*
* 成员内部类中不能存在static关键字,即,不能声明静态属性、静态方法、静态代码块等。
* 成员内部类可以调用外部类的所有成员,但只有在创建了外部类的对象后,才能调用外部的成员。
* 创建成员内部类的实例使用:外部类名.内部类名 实例名 = 外部类实例名.new 内部类构造方法(参数),可以理解为隐式地保存了一个引用,指向创建它的外部类对象。
* 在成员内部类中访问外部类的成员方法和属性时使用:外部类名.this.成员方法/属性(同名的情况下使用,若不同名,则直接使用即可)。
* 内部类在编译之后生成一个单独的class文件,里面包含该类的定义,所以内部类中定义的方法和变量可以跟父类的方法和变量相同。
* 外部类无法直接访问成员内部类的方法和属性,需要通过内部类的一个实例来访问。
* 与外部类平级的类继承内部类时,其构造方法中需要传入父类的实例对象。且在构造方法的第一句调用“外部类实例名.super(内部类参数)”。
*/
class Outer{
private String OutName = "Outer";
public void outPrint(){
System.out.println("I'm " + OutName);
}
class Inner{
private String inName = "Inner";
public void inPrint(){
System.out.println("I'm " + inName);
System.out.println("Outer is " + OutName);
outPrint();
}
}
}
public class Main {
public static void main(String[] args) {
Outer out = new Outer();
Outer.Inner in = out.new Inner();
in.inPrint();
}
}
静态内部类(嵌套类)
使用static来修饰一个内部类,则这个内部类就属于外部类本身,而不属于外部类的某个对象。称为静态内部类(也可称为类内部类),这样的内部类是类级别的,static关键字的作用是把类的成员变成类相关,而不是实例相关。注意:1. 要创建嵌套类的对象,并不需要其外围类的对象。2. 不能从嵌套类的对象中访问非静态的外围类对象。(通常在不需要访问外部类的时候使用静态内部类)
/*
* 静态内部类只能访问外部类的静态成员(包括静态变量和静态方法)
* 静态内部类不能访问外部类的非静态成员(包括非静态变量和非静态方法)
* 外部类访问内部类的静态成员:内部类.静态成员
* 外部类访问内部类的非静态成员:实例化内部类即可
*/
class Outer{
private String OutName = "Outer";
static final String CONST = "static";
public void outPrint(){
System.out.println("I'm " + OutName);
}
static class Inner{
private String inName = "Inner";
public void inPrint(){
System.out.println("I'm " + inName);
System.out.println(Outer.CONST);
}
}
}
public class Main {
public static void main(String[] args) {
Outer.Inner in = new Outer.Inner(); //外部类名.内部类名 实例名 = new 外部类实例名.内部类构造方法(参数)
in.inPrint(); } }
static、final、static final详解
final可以修饰:属性,方法,类,局部变量(方法中的变量)
- final修饰的属性的初始化可以在编译期,也可以在运行期,初始化后不能被改变。
- final修饰的属性跟具体对象有关,在运行期初始化的final属性,不同对象可以有不同的值。
- final修饰的属性表明是一个常数(创建后不能被修改)。
- final修饰的方法表示该方法在子类中不能被重写,final修饰的类表示该类不能被继承。
对于基本类型数据,final会将值变为一个常数(创建后不能被修改);但是对于对象句柄(亦可称作引用或者指针),final会将句柄变为一个常数(进行声明时,必须将句柄初始化到一个具体的对象。而且不能再将句柄指向另一个对象。但是,对象的本身是可以修改的。这一限制也适用于数组,数组也属于对象,数组本身也是可以修改的。方法参数中的final句柄,意味着在该方法内部,我们不能改变参数句柄指向的实际东西,也就是说在方法内部不能给形参句柄再另外赋值)。
static可以修饰:属性,方法,代码段,内部类(静态内部类或嵌套内部类)
- static修饰的属性的初始化在编译期(类加载的时候),初始化后能改变。
- static修饰的属性所有对象都只有一个值。
- static修饰的属性强调它们只有一个。
- static修饰的属性、方法、代码段跟该类的具体对象无关,不创建对象也能调用static修饰的属性、方法等
- static和“this、super”势不两立,static跟具体对象无关,而this、super正好跟具体对象有关。
- static不可以修饰局部变量。
- **static修饰的属性,方法,代码段,内部类是从属于类而不是对象.直接通过类名引用.没有static修饰的从属于对象,需要具体对象来引用.
static final
static修饰的属性强调它们只有一个,final修饰的属性表明是一个常数(创建后不能被修改)。static final修饰的属性表示一旦给值,就不可修改,并且可以通过类名访问。
static final也可以修饰方法,表示该方法不能重写,可以在不new对象的情况下调用。
局部内部类(方法内部类)
在方法中定义的内部类称为局部内部类。与局部变量类似,局部内部类不能有访问说明符,因为它不是外围类的一部分,但是它可以访问当前代码块内的常量,和此外围类所有的成员。可以对外部完全地隐藏。
需要注意的是:
- 局部内部类只能在定义该内部类的方法内实例化,不可以在此方法外对其实例化。
- 局部内部类对象不能使用该内部类所在方法的非final局部变量。
- 局部类不能加访问修饰符,因为它们不是类成员
class Outer{
public void print(){
class Inner{
public void inprint(){
System.out.println("I'm Inner");
}
}
//局部内部类对于外界是隐藏的,因此需要在内部类里面完成对象的定义和引用
new Inner().inprint();
}
}
public class Main {
public static void main(String[] args) {
Outer out = new Outer();
out.print();
}
}
匿名内部类
简单地说:匿名内部类就是没有名字的内部类。什么情况下需要使用匿名内部类?如果满足下面的一些条件,使用匿名内部类是比较合适的:
- 只用到类的一个实例。
- 类在定义后马上用到。
- 类非常小(SUN推荐是在4行代码以下)
- 给类命名并不会导致你的代码更容易被理解。
在使用匿名内部类时,要记住以下几个原则:
-
匿名内部类不能有构造方法。
-
匿名内部类不能定义任何静态成员、方法和类。
-
匿名内部类不能是public,protected,private,static。
-
只能创建匿名内部类的一个实例。
-
一个匿名内部类一定是在new的后面,用其隐含实现一个接口或实现一个类。
-
因匿名内部类为局部内部类,所以局部内部类的所有限制都对其生效。
-
由于匿名内部类不能是抽象类,所以它必须要实现它的抽象父类或者接口里面所有的抽象方法.或者说要扩展实现的类。
abstract class Outer{
abstract void printOut();
}
public class Main {
public static void main(String[] args) {
Outer out = new Outer(){
public void printOut(){
System.out.println("I'm Inner");
}
};
out.printOut();
}
}
Lambda表达式
lambda表达式是一个可传递的代码块,可以在以后执行一次或多次。lambda表达式的语法:(参数)->{表达式}(如果没有参数也要加上括号)。lambda的表达式的返回类型不需要指定,其返回类型总是会由上下文推导得出。对于只有一个抽象方法的接口,当需要这种接口的对象时,就可以提供一个lambda表达式。这种接口称为函数式接口。lambda表达式所能做的也只是能转换为函数式接口。lambda表达式只能被需要函数式接口的方法使用。在lambda表达式中不能声明一个与局部变量同名的参数或局部变量。
方法引用:有时可能已经有现成的方法可以完成你想要传递到其他代码的某个动作,就可以通过方法引用来实现,相当于提供了方法参数的lambda表达式。用法:object::instanceMethod、Class::staticMethod、Class::instanceMethod。要用::双冒号操作符分隔方法名与对象名或类名。
处理lambda表达式:使用lambda表达式的重点是延迟执行。毕竟,如果axing立即执行代码,完全可以直接执行,而无需把它包装在lambda表达式中。原因在于:
- 在一个单独线程中运行代码。
- 在算法的适当位置运行代码。(如排序中的比较操作)
- 发生某种情况时执行代码。(如按钮点击)
- 只在必要时才运行代码。
@FunctionalInterface
interface Calculate {
void applay(int i);
}
public class Main {
public static void main(String[] args) {
//通过匿名内部类使用函数式接口
/*
Calculate calculate = new Calculate() {
@Override
public void applay(int i) {
System.out.println(i);
}
};
*/
//通过lambda使用函数式接口
Calculate calculate = param -> System.out.println(param);
calculate.applay(5);
}
}
Java常用类
String类
String类代表字符串。Java 程序中的所有字符串字面值(如 "abc" )都作为此类的实例实现。字符串是常量,它们的值在创建之后不能更改。字符串缓冲区支持可变的字符串。因为 String 对象是不可变的,所以可以共享。对String对象的任何改变都不影响到原对象,相关的任何change操作都会生成新的对象
public class Main {
public static void main(String[] args) {
//创建String对象
String str1 = "hello";
char[] str2 = {'w','o','r','l','d'};
String str3 = new String(str2); //String对象内部存储结构为char数组。
//String对象操作
System.out.println(str1.length()); //返回字符串长度
System.out.println(str3.charAt(1)); //返回指定位置的字符
String str13 = str1 + str3; //通过重载+运算符实现字符串拼接,等价于str1.concat(str3)
System.out.println(str13);
String str4 = str13.substring(2); //取出指定位置开始及其之后的子字符串
System.out.println(str4);
String str5 = str13.substring(2,4); //取出从2,3两个位置的子字符串
System.out.println(str5);
System.out.println(str13.indexOf("h")); //从字符串前面开始查找指定字符
System.out.println(str13.lastIndexOf("h")); //从字符串后面开始查找指定字符
String str6 = str13.toUpperCase(); //返回将当前字符串全部转成大写的新字符串,str13.toLowerCase()转成小写
System.out.println(str6);
String str7 = str13.replace("o", "n"); //用字符newChar替换当前字符串中所有的oldChar字符,并返回一个新的字符串。
//public String replaceFirst(String regex, String replacement)//该方法用字符replacement的内容替换当前字符串中遇到的第一个和字符串regex相匹配的子串,应将新的字符串返回。
//public String replaceAll(String regex, String replacement)//该方法用字符replacement的内容替换当前字符串中遇到的所有和字符串regex相匹配的子串,应将新的字符串返回。
System.out.println(str7);
//String trim()//截去字符串两端的空格,但对于中间的空格不处理。
//contains(String str)//判断参数s是否被包含在字符串中,并返回一个布尔类型的值。
//String[] split(String str)//将str作为分隔符进行字符串分解,分解后的字字符串在字符串数组中返回。
/*
1、字符串转换为基本类型
java.lang包中有Byte、Short、Integer、Float、Double类的调用方法:
1)public static byte parseByte(String s)
2)public static short parseShort(String s)
3)public static short parseInt(String s)
4)public static long parseLong(String s)
5)public static float parseFloat(String s)
6)public static double parseDouble(String s)
*/
/*
String类中提供了String valueOf()放法,用作基本类型转换为字符串类型。
1)static String valueOf(char data[])
2)static String valueOf(char data[], int offset, int count)
3)static String valueOf(boolean b)
4)static String valueOf(char c)
5)static String valueOf(int i)
6)static String valueOf(long l)
7)static String valueOf(float f)
8)static String valueOf(double d)
*/
}
}
StringBuffer与StringBuilder
StringBuffer与StringBuilder相比,StringBuffer是线程安全的,Stringbuilder则在执行拼接操作速度会快一点.而与String相比StringBuffer和StringBulider都比String快.
public class Main {
public static void main(String[] args) {
//创建String对象
StringBuffer strb1 = new StringBuffer("hello");
StringBuffer strb2 = new StringBuffer("world");
//StringBuffer方法
System.out.println(strb1.append(strb2)); //追加指定的字符序列
System.out.println(strb1.reverse()); //将字符序列反转
System.out.println(strb1.delete(1,3)); //删除指定段的子字符
System.out.println(strb1.insert(1,"h")); //在指定位置插入字符序列
System.out.println(strb1.replace(1,2,"h")); // 使用给定 String 中的字符替换此序列的子字符串中的字符。
/*
其他操作与String类似。
int capacity()
返回当前容量。
char charAt(int index)
返回此序列中指定索引处的 char 值。
void ensureCapacity(int minimumCapacity)
确保容量至少等于指定的最小值。
void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
将字符从此序列复制到目标字符数组 dst。
int indexOf(String str)
返回第一次出现的指定子字符串在该字符串中的索引。
int indexOf(String str, int fromIndex)
从指定的索引处开始,返回第一次出现的指定子字符串在该字符串中的索引。
int lastIndexOf(String str)
返回最右边出现的指定子字符串在此字符串中的索引。
int lastIndexOf(String str, int fromIndex)
返回 String 对象中子字符串最后出现的位置。
int length()
返回长度(字符数)。
void setCharAt(int index, char ch)
将给定索引处的字符设置为 ch。
void setLength(int newLength)
设置字符序列的长度。
CharSequence subSequence(int start, int end)
返回一个新的字符序列,该字符序列是此序列的子序列。
String substring(int start)
返回一个新的 String,它包含此字符序列当前所包含的字符子序列。
String substring(int start, int end)
返回一个新的 String,它包含此序列当前所包含的字符子序列。
String toString()
返回此序列中数据的字符串表示形式。
*/
}
}
若要详细了解其中细节,需要了解JVM.
System类
System 类包含一些有用的类字段和方法。它不能被实例化。在System 类提供的设施中,有标准输入、标准输出和错误输出流;对外部定义的属性和环境变量的访问;加载文件和库的方法;还有快速复制数组的一部分的实用方法。
public class Main {
public static void main(String[] args) {
int[] src = {1, 2, 3, 4};
int[] dest = new int[4];
System.arraycopy(src, 0, dest, 0, 4); //从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。
for(int i : dest){
System.out.print(i + " ");
}
System.out.println(System.currentTimeMillis()); // 返回以毫秒为单位的当前时间
System.out.println(System.getProperties()); // 获取当前系统属性
System.out.println(System.nanoTime()); //返回最准确的可用系统计时器的当前值,以毫微秒为单位。
System.exit(0); //退出当前虚拟机
}
}
Java异常
java异常处理参考 Java异常处理
Java泛型
为什么使用泛型
我们来看一段代码:
public class GenericTest {
public static void main(String[] args) {
List list = new ArrayList();
list.add("hank");
list.add(1);
for (int i = 0; i < list.size(); i++) {
String name = (String) list.get(i);//*
System.out.println("name:" + name);
}
}
}
定义了一个List类型的集合,先向其中加入了一个字符串类型的值,随后加入一个Integer类型的值。因为此时list默认的类型为Object类型,所以可以这样做.在之后的循环中,由于当取到第二个Integer类型的对象时,却还是用着String进行强制类型转换,又赋值给String类型,那么就会出现错误。因为编译阶段正常,而运行时会现“java.lang.ClassCastException”异常。因此,导致此类错误编码过程中不易发现。
为了解决这种问题,泛型就应运而生了.
在Java SE1.5之前,没有泛型的情况下,通过对Object的引用来实现参数的任意化,这种“任意化”的缺点就是就是要做显示的强制类型转换(就像上面的例子一样),而这种转换是要求开发者对实际参数类型可以预知的情况下进行.强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才会出现异常.
泛型的好处:使用泛型,可以保证类型转换的安全性,并且类型转换隐式进行,可以提高代码的重用率.
泛型概述
泛型,即“参数化类型”(在不创建新类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型).也就是说在使用泛型的时候,数据类型被指定为一个参数(像一个占位符),这种参数类型可以用在类,接口和方法中分别成为泛型类,泛型接口和泛型方法.当调用的时候传入具体的类型.
泛型类
泛型类型用于类的定义中,被称为泛型类。通过泛型可以完成对一组类的操作对外开放相同的接口.
class 类名称 <泛型标识:可以随便写任意标识号,标识指定的泛型的类型>{
private 泛型标识 /*(成员变量类型)*/ var;
.....
}
}
下面实现一个简单的泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
class Box<T> {
private T contains;
public void set(T contains){
this.contains = contains;
}
public T get(){
return contains;
}
}
public class Main {
public static void main(String[] args) {
Box<String> box = new Box<>();
box.set("hello");
System.out.println(box.get());
}
}
泛型接口
泛型接口与泛型类的定义及使用基本相同。泛型接口常被用在各种类的生产器中,可以看一个例子:
//定义一个泛型接口
public interface Generator<T> {
public T next();
}
当实现泛型接口的类,未传入泛型实参时:
/**
* 未传入泛型实参时,与泛型类的定义相同,在声明类的时候,需将泛型的声明也一起加到类中
* 即:class FruitGenerator<T> implements Generator<T>{
* 如果不声明泛型,如:class FruitGenerator implements Generator<T>,编译器会报错:"Unknown class"
*/
class FruitGenerator<T> implements Generator<T>{
@Override
public T next() {
return null;
}
}
当实现泛型接口的类,传入泛型实参时:
/**
* 传入泛型实参时:
* 定义一个生产器实现这个接口,虽然我们只创建了一个泛型接口Generator<T>
* 但是我们可以为T传入无数个实参,形成无数种类型的Generator接口。
* 在实现类实现泛型接口时,如已将泛型类型传入实参类型,则所有使用泛型的地方都要替换成传入的实参类型
* 即:Generator<T>,public T next();中的的T都要替换成传入的String类型。
*/
public class FruitGenerator implements Generator<String> {
private String[] fruits = new String[]{"Apple", "Banana", "Pear"};
@Override
public String next() {
Random rand = new Random();
return fruits[rand.nextInt(3)];
}
}
泛型方法
前面在介绍泛型类和泛型接口中提到,可以在泛型类、泛型接口的方法中,把泛型中声明的类型形参当成普通类型使用。**泛型类,是在实例化类的时候指明泛型的具体类型;泛型方法,是在调用方法的时候指明泛型的具体类型 。
例如:
public T get(){//将类型参数当作普通类型使用
return contains;
}
但在另外一些情况下,在类、接口中没有使用泛型时,定义方法时想定义类型形参,就会使用泛型方法。如下方式:
public class Main{
public static <T> void out(T t){
System.out.println(t);
}
public static void main(String[] args){
out("hansheng");
out(123);
}
}
所谓泛型方法,就是在声明方法时定义一个或多个类型形参。泛型方法的用法格式如下:
修饰符<T, S> 返回值类型 方法名(形参列表)
{
方法体
}
方法声明中定义的形参只能在该方法里使用,而接口、类声明中定义的类型形参则可以在整个接口、类中使用。
泛型的边界限定
有时候,类和方法要对类型参数加以约束.在类型参数部分指定 extends 或 super 关键字,分别用上限或下限限制类型,从而限制泛型类型的边界。例如,如果希望将某类型限制为特定类型或特定类型的子类型,请使用以下表示法:
<T extends UpperBoundType>
同样,如果希望将某个类型限制为特定类型或特定类型的超类型,请使用以下表示法:
<T super LowerBoundType>
类型通配符
我们知道Ingeter是Number的一个子类,同时在特性章节中我们也验证过Generic
为了弄清楚这个问题,我们使用Generic
public void showKeyValue1(Generic<Number> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
Generic<Integer> gInteger = new Generic<Integer>(123);
Generic<Number> gNumber = new Generic<Number>(456);
showKeyValue(gNumber);
// showKeyValue这个方法编译器会为我们报错:Generic<java.lang.Integer>
// cannot be applied to Generic<java.lang.Number>
// showKeyValue(gInteger);
通过提示信息我们可以看到Generic
回到上面的例子,如何解决上面的问题?总不能为了定义一个新的方法来处理Generic
我们可以将上面的方法改一下:
public void showKeyValue1(Generic<?> obj){
Log.d("泛型测试","key value is " + obj.getKey());
}
类型通配符一般是使用?代替具体的类型实参,注意了,此处’?’是类型实参,而不是类型形参。重要说三遍!此处’?’是类型实参,而不是类型形参 ! 此处’?’是类型实参,而不是类型形参 !再直白点的意思就是,此处的?和Number、String、Integer一样都是一种实际的类型,可以把?看成所有类型的父类。是一种真实的类型。
可以解决当具体类型不确定的时候,这个通配符就是 ? ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
VS <?>
不同点:
-
用于 泛型的定义,例如 class MyGeneric {...} - 用于 泛型的声明,即泛型的使用,例如 MyGeneric g = new MyGeneric<>();
相同点:都可以指定上界和下界,例如:
class MyGeneric
class MyGeneric
MyGeneric<? extends Collection> g = new MyGeneric<>();
MyGeneric<? super List> g = new MyGeneric<>();
泛型擦除和补偿
类型擦除的定义:编译通过后,准备进入JVM运行时,就不再有类型参数的概念,换句话说:每定义一个泛型类型,JVM会自动提供一个对应的原始类型;原始类型用第一个限定的类型来替换,如果没有给限定就用Object来替换.假设:
public class Test<T extends Comparable & Serializable>{
private T name1;
private T name2;
...
}
那么替换之后:
public class Test{
private Comparable name1;
private Comparable name2;
...
}
总结
Java泛型不是什么神奇的东西,只是编译器为我们提供的一个“语法糖”,泛型本身并不需要Java虚拟机的支持,只需要在编译阶段做一下简单的字符串替换即可。实质上Java的单继承机制才是保证这一特性的根本,因为所有的对象都是Object的子类.事实上泛型机制只是简化了编程,由编译器自动帮我们完成了强制类型转换而已。JDK 1.4以及之前版本不支持泛型,类型转换需要程序员显式完成。
Java集合
Java集合框架由Java类库的一系列接口、抽象类以及具体实现类组成。我们这里所说的集合就是把一组对象组织到一起,然后再根据不同的需求操纵这些数据。集合类型就是容纳这些对象的一个容器。也就是说,最基本的集合特性就是把一组对象放一起集中管理。根据集合中是否允许有重复的对象、对象组织在一起是否按某种顺序等标准来划分的话,集合类型又可以细分为许多种不同的子类型。
Java集合框架为我们提供了一组基本机制以及这些机制的参考实现,其中基本的集合接口是Collection接口,其他相关的接口还有Iterator接口、RandomAccess接口等。这些集合框架中的接口定义了一个集合类型应该实现的基本机制,Java类库为我们提供了一些具体集合类型的参考实现,根据对数据组织及使用的不同需求,只需要实现不同的接口即可。Java类库还为我们提供了一些抽象类,提供了集合类型功能的部分实现,我们也可以在这个基础上去进一步实现自己的集合类型。
Java集合框架的优势有以下几点:
- 这种框架是高性能的。对基本类集(动态数组,链接表,树和散列表)的实现是高效率的。一般很少需要人工去对这些“数据引擎”编写代码(如果有的话)。
- 框架允许不同类型的类集以相同的方式和高度互操作方式工作。
- 类集是容易扩展和/或修改的。为了实现这一目标,类集框架被设计成包含一组标准的接口。对这些接口,提供了几个标准的实现工具(例如LinkedList,HashSet和TreeSet),通常就是这样使用的。如果你愿意的话,也可以实现你自己的类集。为了方便起见,创建用于各种特殊目的的实现工具。一部分工具可以使你自己的类集实现更加容易。
- 增加了允许将标准数组融合到类集框架中的机制。

从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象
实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。Collections和Arrays工具类实现了集合框架中有用的方法.
除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
迭代器
迭代器是一种模式、详细可见其设计模式,可以使得序列类型的数据结构的遍历行为与被遍历的对象分离,即我们无需关心该序列的底层结构是什么样子的。只要拿到这个对象,使用迭代器就可以遍历这个对象的内部。
Iterable:实现这个接口的集合对象支持迭代,是可以迭代的。实现了这个可以配合foreach使用.
Iterator:迭代器,提供迭代机制的对象,具体如何迭代是这个Iterator接口规范的。
/*
Iterable中有一个返回Iterator类型的iterator()方法,和一个forEach()方法.
*/
public interface Iterable<T>
{
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
}
因为有foreach()方法所以实现了Iterable接口的对象可以用forEach()来遍历.而Iterator包含以下方法:
public interface Iterator<E> {
boolean hasNext();//每次next之前,先调用此方法探测是否迭代到终点
E next();//返回当前迭代元素 ,同时,迭代游标后移
/*
删除最近一次已近迭代出出去的那个元素。
只有当next执行完后,才能调用remove函数。
比如你要删除第一个元素,不能直接调用 remove()而要先
next一下( );
在没有先调用next 就调用remove方法是会抛出异常的。
*/
void remove()
{
throw new UnsupportedOperationException("remove");
}
}
迭代出来的元素都是原来集合元素的拷贝.
Java集合中保存的元素实质是对象的引用,而非对象本身.
迭代出的对象也是引用的拷贝,结果还是引用。那么如果集合中保存的元素是可变类型的,那么可以通过迭代出的元素修改原集合中的对象。
for循环,增强for循环和forEach
引入增强for循环的原因:在JDK5以前的版本中,遍历数组或集合中的元素,需要先获得数组的长度或集合的迭代器,比较麻烦。
JDK5中定义了一种新的语法----增强for循环,以简化此类操作。增强for循环只能用在数组或实现Iterable接口的集合上。
for(变量类型 变量:需迭代的数组或集合){
}
在JAVA中,遍历集合和数组一般有以下三种形式:
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i) + ",");
}
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + ",");
}
for (Integer i : list) {
System.out.print(i + ",");
}
第一种是普通的for循环遍历、第二种是使用迭代器进行遍历,第三种我们一般称之为增强for循环(foreach)。
实现原理
可以看到,第三种形式是JAVA提供的语法糖,这里我们剖析一下,这种增强for循环底层是如何实现的。
我们对以下代码进行反编译:
for (Integer i : list) {
System.out.println(i);
}
反编译后的代码其实比较复杂,我们按照执行顺序拆解一下:
Integer i;
for(Iterator iterator = list.iterator(); iterator.hasNext(); System.out.println(i)){
i = (Integer)iterator.next();
}
/*
Integer i; 定义一个临时变量i
Iterator iterator = list.iterator(); 获取List的迭代器
iterator.hasNext(); 判断迭代器中是否有未遍历过的元素
i = (Integer)iterator.next(); 获取第一个未遍历的元素,赋值给临时变量i
System.out.println(i); 输出临时变量i的值
*/
通过反编译,我们看到,其实JAVA中的增强for循环底层是通过迭代器模式来实现的。
总结
由于使用for循环遍历集合时,需要先获得数组的长度或集合的迭代器,比较麻烦。所以出现了增强for(foreach).在说法上注意Iterable接口中的forEach()方法.forEach()方法专门用来遍历集合,不能遍历数组.
具体应用与详解
参考优秀文章
本人才疏学浅只好站在巨人的肩膀上了.
Java IO体系
IO流用来处理设备之间的数据传输,Java程序中,对于数据的输入/输出操作 都是以“流”的方式进行的。java.io包下提供了各种“流”类的接口,用以获取不同种类的数据,并通过标准的方法输入或输出数据。对于计算机来说,数据都是以二进制形式读出或写入的。我们可以把文件想象为一个桶,我们可以通过管道将桶里的水抽出来。这里的管道也就相当于Java中的流。流的本质是一种有序的数据集合,有数据源和目的地。
简单介绍一下JavaIO体系:
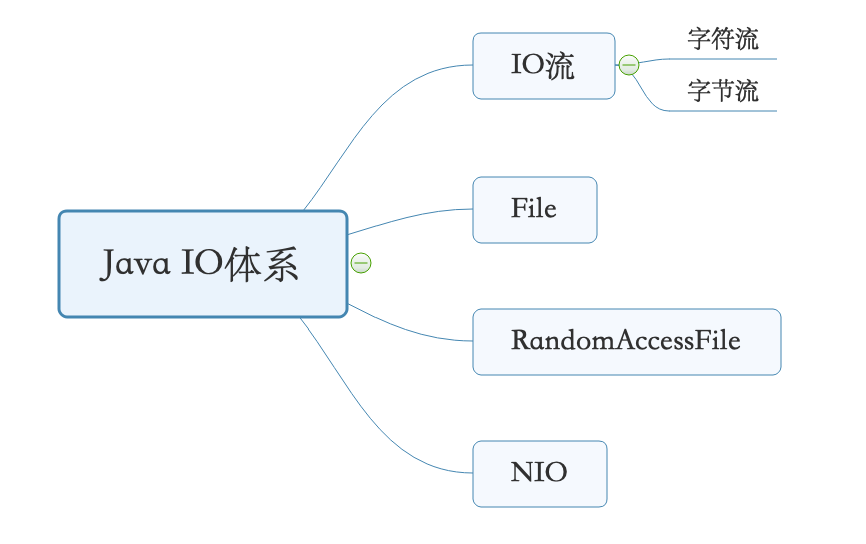

Java IO
字符流
Reader
Reader用于读取字符流的抽象类.子类必须实现的方法只有read(char[],int,int)和close().但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能。也就是说该类的子类实现将磁盘(文件)中的数据读入内存中.
public abstract class Reader implements Readable, Closeable {
protected Object lock;
protected Reader() {
this.lock = this;
}
protected Reader(Object lock) {
if (lock == null) {
throw new NullPointerException();
}
this.lock = lock;
}
//试图将字符读入指定的字符缓冲区。缓冲区可照原样用作字符的存储库:所做的唯一改变是 put 操作的结果。不对缓冲区执行翻转或重绕操作。
public int read(java.nio.CharBuffer target) throws IOException {}
//读取单个字符。在字符可用、发生 I/O 错误或者已到达流的末尾前,此方法一直阻塞。 用于支持高效的单字符输入的子类应重写此方法。
public int read() throws IOException { }
//将字符读入数组。在某个输入可用、发生 I/O 错误或者已到达流的末尾前,此方法一直阻塞。
public int read(char cbuf[]) throws IOException {}
// 将字符读入数组的某一部分。在某个输入可用、发生 I/O 错误或者到达流的末尾前,此方法一直阻塞。
abstract public int read(char cbuf[], int off, int len) throws IOException;
//跳过字符。在某个字符可用、发生 I/O 错误或者已到达流的末尾前,此方法一直阻塞。
public long skip(long n) throws IOException {}
//判断是否准备读取此流。
public boolean ready() throws IOException { }
//判断此流是否支持 mark() 操作。默认实现始终返回 false。子类应重写此方法。
public boolean markSupported() {}
//标记流中的当前位置。对 reset() 的后续调用将尝试将该流重新定位到此点。并不是所有的字符输入流都支持 mark() 操作。
public void mark(int readAheadLimit) throws IOException { }
//重置该流。如果已标记该流,则尝试在该标记处重新定位该流。如果已标记该流,则以适用于特定流的某种方式尝试重置该流,
//例如,通过将该流重新定位到其起始点。并不是所有的字符输入流都支持 reset() 操作,有些支持 reset() 而不支持 mark()。
public void reset() throws IOException { }
//关闭该流并释放与之关联的所有资源。在关闭该流后,再调用 read()、ready()、mark()、reset() 或 skip() 将抛出 IOException。关闭以前关闭的流无效。
abstract public void close() throws IOException;
}
下面介绍一下常用字符读取类.
InputStreamReader
InputStreamReader将字节输入流转换为字符输入流。是字节流通向字符流的桥梁,可以指定字节流转换为字符流的字符集。
InputStreamReader(InputStream in) //创建一个使用默认字符集的 InputStreamReader。
InputStreamReader(InputStream in, String charsetName) //创建使用指定字符集的 InputStreamReader。
//public int read() throws IOException
//读取单个字符。在字符可用、发生 I/O 错误或者已到达流的末尾前,此方法一直阻塞。
public static void readOneStr() throws IOException{
InputStreamReader isr=new InputStreamReader(new FileInputStream("E:\test\javaIo\1.txt"));
int ch=0;
while((ch=isr.read())!=-1){
System.out.print((char)ch);
}
isr.close();
}
//public int read(char[] cbuf) throws IOException
//将字符读入数组。在某个输入可用、发生 I/O 错误或者已到达流的末尾前,此方法一直阻塞。
public static void readOneStrArr() throws IOException{
InputStreamReader isr=new InputStreamReader(new FileInputStream("E:\test\javaIo\1.txt"));
char [] ch=new char[1024];
int len=0;
while((len=isr.read(ch))!=-1){
System.out.print(new String(ch,0,len));
}
isr.close();
}
//public int read(char[] cbuf) throws IOException
//将字符读入数组的某一部分。在某个输入可用、发生 I/O 错误或者到达流的末尾前,此方法一直阻塞。
public static void readOneStrArrLen() throws IOException{
InputStreamReader isr=new InputStreamReader(new FileInputStream("E:\test\javaIo\1.txt"));
char [] ch=new char[1024];
int len=0;
while((len=isr.read(ch,0,ch.length))!=-1){
System.out.print(new String(ch,0,len));
}
isr.close();
}
FileReader
FileReader用来读取字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是适当的。要自己指定这些值,可以先在 FileInputStream 上构造一个 InputStreamReader。
FileReader 用于读取字符流。要读取原始字节流,请考虑使用 FileInputStream。
FileReader fr = new FileReader(String fileName);
//使用带有指定文件的String参数的构造方法。创建该输入流对象。并关联源文件。
//该类读取文件方式与InputStreamReader基本一样,使用该类代码较简洁建议使用.
//简单使用
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
try{
FileReader fr=new FileReader(path);
char[] ch=new char[1024];
int len=0;
while((len=fr.read(ch))!=-1){
System.out.println(new String(ch,0,len));
}
fr.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
BufferedReader(缓冲流)
从字符输入流中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。可以指定缓冲区的大小,或者可使用默认的大小。大多数情况下,默认值就足够大了。
通常,Reader 所作的每个读取请求都会导致对底层字符或字节流进行相应的读取请求。因此,建议用 BufferedReader 包装所有其 read() 操作可能开销很高的 Reader(如 FileReader和InputStreamReader)。例如,
BufferedReader in = new BufferedReader(new FileReader("foo.in"));
将缓冲指定文件的输入。如果没有缓冲,则每次调用 read() 或 readLine() 都会导致从文件中读取字节,并将其转换为字符后返回,而这是极其低效的。
通过用合适的 BufferedReader 替代每个 DataInputStream,可以对将 DataInputStream 用于文字输入的程序进行本地化。
//public String readLine()throws IOException读取一个文本行。通过下列字符之一即可认为某行已终止:换行 ('
')、回车 ('
') 或回车后直接跟着换行。
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
try {
BufferedReader br = new BufferedReader(new FileReader(path));
String str = null;
while ((str = br.readLine()) != null) {
System.out.println(str);
}
br.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
LineNumberReader(关于行号缓冲流)
跟踪行号的缓冲字符输入流。此类定义了方法 setLineNumber(int) 和 getLineNumber(),它们可分别用于设置和获取当前行号。
默认情况下,行编号从 0 开始。该行号随数据读取在每个行结束符处递增,并且可以通过调用 setLineNumber(int) 更改行号。但要注意的是,setLineNumber(int) 不会实际更改流中的当前位置;它只更改将由 getLineNumber() 返回的值。可认为行在遇到以下符号之一时结束:换行符('
')、回车符('
')、回车后紧跟换行符。
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
try {
LineNumberReader lnr=new LineNumberReader(new FileReader(path));
//public void setLineNumber(int lineNumber)设置当前行号。 如果不设置该值 行号默认从0开始
lnr.setLineNumber(10);
String str=null;
while((str=lnr.readLine())!=null){
//public int getLineNumber()获得当前行号。
System.out.println(lnr.getLineNumber()+":"+str);
}
lnr.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
Writer
Writer 写入字符流的抽象类。子类必须实现的方法仅有 write(char[], int, int)、flush() 和 close()。但是,多数子类将重写此处定义的一些方法,以提供更高的效率和/或其他功能。
public abstract class Writer implements Appendable, Closeable, Flushable {
private char[] writeBuffer;
private final int writeBufferSize = 1024;
protected Object lock;
protected Writer() {
this.lock = this;
}
protected Writer(Object lock) {
}
// 写入单个字符。要写入的字符包含在给定整数值的 16 个低位中,16 高位被忽略。 用于支持高效单字符输出的子类应重写此方法。
public void write(int c) throws IOException {
}
//写入字符数组。
public void write(char cbuf[]) throws IOException {
}
//写入字符数组的某一部分。
abstract public void write(char cbuf[], int off, int len) throws IOException;
//写入字符串
public void write(String str) throws IOException {
}
//写入字符串的某一部分。
public void write(String str, int off, int len) throws IOException {
}
//将指定字符序列添加到此 writer。
public Writer append(CharSequence csq) throws IOException {
}
//将指定字符序列的子序列添加到此 writer.Appendable。
public Writer append(CharSequence csq, int start, int end) throws IOException {
CharSequence cs = (csq == null ? "null" : csq);
write(cs.subSequence(start, end).toString());
return this;
}
//将指定字符添加到此 writer
public Writer append(char c) throws IOException {
write(c);
return this;
}
//刷新该流的缓冲。如果该流已保存缓冲区中各种 write() 方法的所有字符,则立即将它们写入预期目标。
//然后,如果该目标是另一个字符或字节流,则将其刷新。因此,一次 flush() 调用将刷新 Writer 和 OutputStream 链中的所有缓冲区。
abstract public void flush() throws IOException;
//关闭此流,但要先刷新它。在关闭该流之后,再调用 write() 或 flush() 将导致抛出 IOException。关闭以前关闭的流无效
abstract public void close() throws IOException;
}
OutputStreamWriter
OutputStreamWriter 是字符流通向字节流的桥梁:可使用指定的 charset 将要写入流中的字符编码成字节。它使用的字符集可以由名称指定或显式给定,否则将接受平台默认的字符集。每次调用 write() 方法都会导致在给定字符(或字符集)上调用编码转换器。在写入底层输出流之前,得到的这些字节将在缓冲区中累积。可以指定此缓冲区的大小,不过,默认的缓冲区对多数用途来说已足够大。注意,传递给 write() 方法的字符没有缓冲。为了获得最高效率,可考虑将 OutputStreamWriter 包装到 BufferedWriter 中,以避免频繁调用转换器。例如:
Writer out = new BufferedWriter(new OutputStreamWriter(System.out));
代理对 是一个字符,它由两个 char 值序列表示:高 代理项的范围为 'uD800' 到 'uDBFF',后跟范围为 'uDC00' 到 'uDFFF' 的低 代理项。错误代理元素 指的是后面不跟低代理项的高代理项,或前面没有高代理项的低代理项。
此类总是使用字符集的默认替代序列 替代错误代理元素和不可映射的字符序列。如果需要更多地控制编码过程,则应该使用 CharsetEncoder 类。
//public OutputStreamWriter(OutputStream out, String charsetName); 可以设置编码格式
//public OutputStreamWriter(OutputStream out)创建使用默认字符编码的 OutputStreamWriter。
OutputStreamWriter将内存中的数据写入文件的5中方式如下:
//public void write(int c)throws IOException
//写入单个字符。要写入的字符包含在给定整数值的 16 个低位中,16 高位被忽略。
public static void writerOneChar() throws IOException{
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("E:\test\javaIo\1.txt"));
osw.write(97);//char ch=(char)97;
osw.write('c');
osw.flush();
osw.close();
}
//public void write(char[] cbuf)throws IOException 写入字符数组。
public static void writerCharArr() throws IOException{
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("E:\test\javaIo\1.txt"));
char [] ch=new char[]{'我','爱','中','国'};
osw.write(ch);
osw.flush();
osw.close();
}
//public abstract void write(char[] cbuf,int off,int len)throws IOException 写入字符数组的某一部分。
public static void writerCharArrLen() throws IOException{
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("E:\test\javaIo\1.txt"));
char [] ch=new char[]{'我','爱','中','国'};
osw.write(ch,0,ch.length-1);
osw.flush();
osw.close();
}
//public void write(String str) throws IOException 写入字符串。
public static void writerOneStr() throws IOException{
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("E:\test\javaIo\1.txt"));
osw.write("中国");
osw.flush();
osw.close();
}
//public void write(String str,int off, int len)throws IOException; 写入字符串的某一部分。
public static void writerOneStrArrLen() throws IOException{
OutputStreamWriter osw=new OutputStreamWriter(new FileOutputStream("E:\test\javaIo\1.txt"));
String str="我爱中国";
osw.write(str,0,str.length()-2);
osw.flush();
osw.close();
}
FileWriter
用来写入字符文件的便捷类。此类的构造方法假定默认字符编码和默认字节缓冲区大小都是可接受的。要自己指定这些值,可以先在 FileOutputStream 上构造一个 OutputStreamWriter。
文件是否可用或是否可以被创建取决于底层平台。特别是某些平台一次只允许一个 FileWriter(或其他文件写入对象)打开文件进行写入。在这种情况下,如果所涉及的文件已经打开,则此类中的构造方法将失败。
FileWriter 用于写入字符流。要写入原始字节流,请考虑使用 FileOutputStream。
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
try {
FileWriter fw=new FileWriter(path);
String str="爱我中华";
fw.write(str);
fw.flush();
fw.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
BufferedWriter(缓冲流)
将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
可以指定缓冲区的大小,或者接受默认的大小。在大多数情况下,默认值就足够大了。
该类提供了 newLine() 方法,它使用平台自己的行分隔符概念,此概念由系统属性 line.separator 定义。并非所有平台都使用新行符 ('
') 来终止各行。因此调用此方法来终止每个输出行要优于直接写入新行符。
通常 Writer 将其输出立即发送到底层字符或字节流。除非要求提示输出,否则建议用 BufferedWriter 包装所有其 write() 操作可能开销很高的 Writer(如 FileWriters 和 OutputStreamWriters)。例如,
PrintWriter out = new PrintWriter(new BufferedWriter(new FileWriter("foo.out")));
将缓冲 PrintWriter 对文件的输出。如果没有缓冲,则每次调用 print() 方法会导致将字符转换为字节,然后立即写入到文件,而这是极其低效的。
在这里我们演示他特有的newLine( )方法。
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
try {
BufferedWriter bw=new BufferedWriter(new FileWriter(path));
bw.write("爱我");
bw.newLine();
bw.write("中华");
bw.flush();
bw.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
字节流
InputStream
此抽象类是表示字节输入流的所有类的超类。需要定义 InputStream 子类的应用程序必须总是提供返回下一个输入字节的方法。实现了此类的子类必须实现read() 方法 (从下面就可以看出,此方法是抽象方法).
int available()
//返回此输入流下一个方法调用可以不受阻塞地从此输入流读取(或跳过)的估计字节数。
void close()
//关闭此输入流并释放与该流关联的所有系统资源。
void mark(int readlimit)
//在此输入流中标记当前的位置。
boolean markSupported()
//测试此输入流是否支持 mark 和 reset 方法。
abstract int read()
//从输入流中读取数据的下一个字节。
int read(byte[] b)
//从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
int read(byte[] b, int off, int len)
//将输入流中最多 len 个数据字节读入 byte 数组。
void reset()
//将此流重新定位到最后一次对此输入流调用 mark 方法时的位置。
long skip(long n)
//跳过和丢弃此输入流中数据的 n 个字节。
FileInputStream
FileInputStream 从文件系统中的某个文件中获得输入字节。哪些文件可用取决于主机环境。
FileInputStream 用于读取诸如图像数据之类的原始字节流。要读取字符流,请考虑使用 FileReader。
import java.io.*;
public class Main {
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
File file = new File(path);
try {
//通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的 File 对象 file 指定。
FileInputStream fileInputStreamf = new FileInputStream(file);
//通过打开一个到实际文件的连接来创建一个 FileInputStream,该文件通过文件系统中的路径名 name 指定。
FileInputStream pathInputStream = new FileInputStream(path);
byte[] bytes = new byte[5];
//从此输入流中将最多 b.length 个字节的数据读入一个 byte 数组中。
fileInputStreamf.read(bytes);
//从输入流中跳过并丢弃 n 个字节的数据。
fileInputStreamf.skip(5);
System.out.println(new String(bytes));
//关闭此文件输入流并释放与此流有关的所有系统资源。
fileInputStreamf.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
}
BufferInputStream
BufferedInputStream 为另一个输入流添加一些功能,即缓冲输入以及支持 mark 和 reset 方法的能力。在创建 BufferedInputStream 时,会创建一个内部缓冲区数组。在读取或跳过流中的字节时,可根据需要从包含的输入流再次填充该内部缓冲区,一次填充多个字节。mark 操作记录输入流中的某个点,reset 操作使得在从包含的输入流中获取新字节之前,再次读取自最后一次 mark 操作后读取的所有字节。
// 创建一个 BufferedInputStream并保存其参数,即输入流in,以便将来使用。
BufferedInputStream(InputStream in)
// 创建具有指定缓冲区大小的 BufferedInputStream并保存其参数,即输入流in以便将来使用
BufferedInputStream(InputStream in, int size)
import java.io.*;
public class Main {
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
File file = new File(path);
try {
InputStream in = new FileInputStream(path);
// 字节缓存流
BufferedInputStream bis = new BufferedInputStream(in);
byte[] bs = new byte[20];
int len = 0;
while ((len = bis.read(bs)) != -1) {
System.out.print(new String(bs, 0, len));
}
// 关闭流
bis.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
}
OutputStream
此抽象类是表示输出字节流的所有类的超类。输出流接受输出字节并将这些字节发送到某个接收器。
需要定义 OutputStream 子类的应用程序必须始终提供至少一种可写入一个输出字节的方法。
void close()
//关闭此输出流并释放与此流有关的所有系统资源。
void flush()
//刷新此输出流并强制写出所有缓冲的输出字节。
void write(byte[] b)
//将 b.length 个字节从指定的 byte 数组写入此输出流。
void write(byte[] b, int off, int len)
//将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。
abstract void write(int b)
//将指定的字节写入此输出流。
FileOutputSream
文件输出流是用于将数据写入 File 或 FileDescriptor 的输出流。文件是否可用或能否可以被创建取决于基础平台。特别是某些平台一次只允许一个 FileOutputStream(或其他文件写入对象)打开文件进行写入。在这种情况下,如果所涉及的文件已经打开,则此类中的构造方法将失败。
FileOutputStream 用于写入诸如图像数据之类的原始字节的流。要写入字符流,请考虑使用 FileWriter。
import java.io.*;
public class Main {
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
File file = new File(path);
try {
//创建一个向指定 File 对象表示的文件中写入数据的文件输出流。
FileOutputStream fileOutputStream = new FileOutputStream(file);
//创建一个向具有指定名称的文件中写入数据的输出文件流。
FileOutputStream pathOutputStream = new FileOutputStream(path);
//将 b.length 个字节从指定 byte 数组写入此文件输出流中。
fileOutputStream.write("hello".getBytes());
//关闭此文件输出流并释放与此流有关的所有系统资源。
fileOutputStream.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
}
BufferedOutputStream
在前面介绍的FileOutputStream,是在程序里面读取一个字节,就往外写一个字节。在这种情况下,频繁的跟IO设备打交道,I/O的处理速度跟CPU的速度根本就不在一个量级上(I/O是一种物理设备),在信息量很多的时候,就比较消耗性能。基于这种问题,JAVA提供了缓冲字节流,通过这种流,应用程序就可以将各个字节写入底层输出流中,而不必针对每次字节写入调用底层系统。
// 创建一个新的缓冲输出流,以将数据写入指定的底层输出流
BufferedOutputStream(OutputStream out)
// 创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流
BufferedOutputStream(OutputStream out, int size)
import java.io.*;
public class Main {
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
File file = new File(path);
try {
FileOutputStream fileOutputStream = new FileOutputStream(path);
//创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
// 将指定 byte 数组中字节写入此缓冲的输出流。
bufferedOutputStream.write("hello".getBytes());
//刷新此缓冲的输出流。
bufferedOutputStream.flush();
//关闭此文件输出流并释放与此流有关的所有系统资源。
bufferedOutputStream.close();
}catch(IOException e){
System.out.println(e.toString());
}
}
}
缓冲输出流在输出的时候,不是直接一个字节一个字节的操作,而是先写入内存的缓冲区内。直到缓冲区满了或者我们调用close方法或flush方法,该缓冲区的内容才会写入目标。才会从内存中转移到磁盘上。
File
File类简介
在操作文件之前必须创建一个指向文件的链接或者实例化一个文件对象,也可以指定一个不存在的文件从而创建它。Java 中的 File 类是文件和目录路径名的抽象形式。使用 File 类可以获取文件本身的一些信息,例如文件所在的目录、文件长度、文件读写权限等。
在 Java 中,File 类是 java.io 包中唯一代表磁盘文件本身的对象。File 类定义了一些与平台无关的方法来操作文件,File类主要用来获取或处理与磁盘文件相关的信息,像文件名、 文件路径、访问权限和修改日期等,还可以浏览子目录层次结构。
File 类表示处理文件和文件系统的相关信息。也就是说,File 类不具有从文件读取信息和向文件写入信息的功能,它仅描述文件本身的属性。
File类使用
- 构造函数
import java.io.File;
import java.io.IOException;
public class Main {
public static void main(String[] args) {
/*
* 创建一个File实例,File类的实例是不可变的;也就是说,一旦创建,File 对象表示的抽象路径名将永不改变。
* 简单来说File类是用来抽象文件和文件夹的,不同的File类实例代表着不同的文件或者文件夹。
*/
//通过将给定路径名字符串转换为抽象路径名来创建一个File实例。
File file = new File("/Users/hank/JavaProjects/JavaTest/src/draft");
/*
File类中一些创建操作
*/
//当且仅当不存在具有此抽象路径名指定名称的文件时,不可分地创建一个新的空文件。如果指定的文件不存在并成功地创建,则返回 true;如果指定的文件已经存在,则返回 false。
try{
file.createNewFile();
} catch (IOException e){
System.out.println(e.toString());
}
//在指定位置创建一个单级文件夹。
file.mkdir();
//在指定位置创建一个多级文件夹。
file.mkdirs();
//如果目标文件与源文件是在同一个路径下,那么renameTo的作用是重命名, 如果目标文件与源文件不是在同一个路径下,那么renameTo的作用就是剪切,而且还不能操作文件夹。
file.renameTo(file);
/*
File类中一些删除操作
*/
//删除文件或者一个空文件夹,不能删除非空文件夹,马上删除文件,返回一个布尔值。
file.delete();
//jvm退出时删除文件或者文件夹,用于删除临时文件,无返回值。
file.deleteOnExit();
/*
File类中一些判断操作
*/
//文件或文件夹是否存在。
file.exists();
//是否是一个文件,如果不存在,则始终为false。
file.isFile();
//是否是一个目录,如果不存在,则始终为false。
file.isDirectory();
//是否是一个隐藏的文件或是否是隐藏的目录。
file.isHidden();
//测试此抽象路径名是否为绝对路径名。
file.isAbsolute();
/*
File类中一些获取文件信息操作
*/
//获取文件或文件夹的名称,不包含上级路径。
file.getName();
//获取文件的绝对路径,与文件是否存在没关系
file.getAbsolutePath();
//获取文件的大小(字节数),如果文件不存在则返回0L,如果是文件夹也返回0L。
file.length();
//返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回null。
file.getParent();
//获取最后一次被修改的时间。
file.lastModified();
/*
File类中一些获取文件夹相关操作
*/
//列出所有的根目录(Window中就是所有系统的盘符)
File.listRoots();
//返回目录下的文件或者目录名,包含隐藏文件。对于文件这样操作会返回null。
file.list();
//返回目录下的文件或者目录对象(File类实例),包含隐藏文件。对于文件这样操作会返回null。
file.listFiles();
}
}
RandomAccessFile
RandomAccessFile简介
RandomAccessFile类的实例支持对随机访问文件的读取和写入。随机访问文件的行为类似存储在文件系统中的一个大型byte数组。存在指向该隐含数组的光标或索引,称为文件指针;输入操作从文件指针开始读取字节,并随着对字节的读取而前移此文件指针。如果随机访问文件以读取/写入模式创建,则输出操作也可用;输出操作从文件指针开始写入字节,并随着对字节的写入而前移此文件指针。写入隐含数组的当前末尾之后的输出操作导致该数组扩展。该文件指针可以通过getFilePointer方法读取,并通过seek方法设置。
通常,如果此类中的所有读取例程在读取所需数量的字节之前已到达文件末尾,则抛出 EOFException(是一种 IOException)。如果由于某些原因无法读取任何字节,而不是在读取所需数量的字节之前已到达文件末尾,则抛出 IOException,而不是 EOFException。需要特别指出的是,如果流已被关闭,则可能抛出 IOException。
当我们需要对一个txt文件的末尾追加一行文字时,我们可能会将该文件全部加载到内存,然后再对它进行追加操作.这可能只适应文件大小较小的情况,如果你的电脑内存只有4GB,而文件却有5GB,那么你如果还这样操作,可能就不太现实.那么这个时候RandomAccessFile就有用武之地了.它基本上可以实现零内存追加.
RandomAccessFile是Java中输入,输出流体系中功能最丰富的文件内容访问类,它提供很多方法来操作文件,包括读写支持,与普通的IO流相比,它最大的特别之处就是支持任意访问的方式,程序可以直接跳到任意地方来读写数据。如果我们只希望访问文件的部分内容,而不是把文件从头读到尾,使用RandomAccessFile将会带来更简洁的代码以及更好的性能。
RandomAccessFile使用
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
public class Main {
public static void main(String[] args) {
String path = "/Users/hank/JavaProjects/JavaTest/src/test";
try{
/*
创建RandomAccessFile类实例,有两种创建方法
RandomAccessFile(File file, String mode) 创建从中读取和向其中写入(可选)的随机访问文件流,该文件由 File 参数指定。
RandomAccessFile(String name, String mode) 创建从中读取和向其中写入(可选)的随机访问文件流,该文件具有指定名称。
其中有三种访问模式:r读模式,w写模式,rw读写模式(此模式下如果问件不存在会自动新建)。
*/
RandomAccessFile randomAccessFile = new RandomAccessFile(path, "rw");
/*
读文件相关操作
*/
try{
//返回此文件的长度。
randomAccessFile.length();
//返回此文件中的当前偏移量。
randomAccessFile.getFilePointer();
//从此文件中读取一个数据字节。
randomAccessFile.read();
//将最多 byte_read.length 个数据字节从此文件读入 byte 数组。
byte[] byte_read = new byte[10];
randomAccessFile.read(byte_read);
//从此文件读取文本的下一行。以及其他的读取指定类型的数据在次不必赘述。需要时查看文档即可。
randomAccessFile.readLine();
//设置到此文件开头测量到的文件指针偏移量,在该位置发生下一个读取或写入操作。从文件开头以字节为单位测量的偏移量位置,在该位置设置文件指针。
randomAccessFile.seek(1);
//设置此文件的长度。
randomAccessFile.setLength(1);
//尝试跳过输入的 n 个字节以丢弃跳过的字节。
randomAccessFile.skipBytes(2);
}catch(IOException e){
System.out.println(e.toString());
}
/*
写文件相关操作
*/
try{
//将 byte_write.length 个字节从指定 byte 数组写入到此文件,并从当前文件指针开始。
byte[] byte_write = new byte[10];
randomAccessFile.write(byte_write);
//按字符序列将一个字符串写入该文件。以及其他的写入指定类型的数据在次不必赘述。需要时查看文档即可。
randomAccessFile.writeChars("hello");
}catch(IOException e){
System.out.println(e.toString());
}
}catch (FileNotFoundException e){
System.out.println(e.toString());
}
}
}
Java流库
Java流提供了一种让我们可以在比集合更高的概念级别上指定计算的视图.通过使用流我们可以只需要知道我们要完成什么任务,而不用去管如何实现它.注意这里的流与IO流没有任何关系. 这是Java8用来处理集合的新方式.
从迭代到流
在处理集合时,我们会通常使用迭代来便利他的元素,并对每个元素进行操作.例如现在我们需要对某本书中的长单词进行计数.
String contents = new String(Files.readAllBytes(Path.get("alice.txt")),StandardCharsets.UTF-8)
List<String> words = Arrays.asList(contents.split("\PL+"));
//我们可以使用迭代来计数
long count = 0;
for(String w : words){
if(w.length()>12)
count++;
}
//使用流操作
long count = words.stream()
.filter(w->w.length()>12)
.count();
对比上面的迭代版本与流版本.我们可以看出流的版本比循环迭代版本要更易读,因为我们不必扫描整个代码去查找过滤和计数操作,方法名就可以直接告诉我们这段代码是用来做什么的.
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。Stream 的并行操作依赖于 Java7 中引入的 Fork/Join 框架(JSR166y)来拆分任务和加速处理过程。
流表面上看起来和集合很类似,都可以转换和获取数据。但是,它们之间存在着显著的差异:
- 流并不存储元素.这些元素可能存储在底层的集合中,或者是按需生成的.
- 流操作不修改数据源.例如,filter方法不会从流中移除元素,而是生成一个新的流,其中不包括被过滤掉的元素.
- 流操作是尽可能惰性执行.即按需执行.
流的创建
- 从上面我们知道Collection接口的steam方法将任何集合转换为一个流.
- 如果我们有一个数组,那么可以使用静态方法Stream.of方法.将数组转成流.也可以使用Arrays.stream()将数组转换成流.
- 为了创建不包含任何元素的流,可以使用静态的Stream.empty方法
- Stream 接口有两个用于创建无限流的静态方法。generate方法会接受一个不包含任何引元的函数(或者是一个Suplier
接口的对象)。无论何时,只需要一个流类型的值,该函数就会被调用产生一个这样的值。Stream echos = Stream.generate(()->"Echo");或者像下面这样获取一个随机数流:
Streamrandoms = Stream.generate(Math::random);
为了产生无限序列,可以使用iterate方法。它会接受一个种子值,以及一个函数(从技术上讲,是一个UnaryOperation),并且会反复将该函数应用到之前的结果上。
Streamintegers
= Stream.iterate(BigInteger.ZERO,n->add(BigInteger.ONE));
流的操作
filter,map和flatMap方法
- Stream
filter(Predicate<? super T> predicate)
产生一个流,它包含当前流中所有满足断言条件的元素。如将一个字符串流转换为了只含长单词的另一个流:
List<String> wordList = ...;
Stream<String> longWords = wordList.stream().filter(w -> w.length() > 12);
Stream map(Function<? super T,? extends R> mapper)
产生一个流,它包含将mapper应用于当前流中所有元素所产生的结果。如:将所有单词都转换为小写:
Stream<String> lowercaseWords = words.stream().map(String::toLowerCase);
Stream flatMap(Function<? super T,? extends R> mapper)
产生一个流,它通过将mapper应用于当前流中所有元素所产生的结果连接到一起而获得的。(这里的每个结果都是一个流。)
抽取子流和连接流
- Stream
limit(long maxSize)
产生一个流,其中包含了当前流中最初的maxSize个元素(如果原来的流更短,那么就会在流结束时结束)。这个方法对于裁剪无限流的尺寸会显得特别有用,如:产生一个包含100个随机数的流
Stream<Double> randoms = Stream.generate(Math::random).limit(100);
-
Stream
skip(long n)
产生一个流,它的元素是当前流中除了前n个元素之外的所有元素。 -
static
Stream concat(Stream<? extends T> a, Stream<? extends T> b)
产生一个流,它的元素是a的元素后面跟着b的元素。
其他转换流
- Stream
distinct()
产生一个流,包含当前流中所有不同的元素。
Stream<String> uniqueWords
= Stream.of ("merrily","merrily","merrily","gently").distinct ();
//Only one "merrily" is retained
- Stream
sorted()Stream sorted(Comparator<? super T> comparator)
产生一个流,它的元素是当前流中的所有元素按照顺序排列的。第一方法要求元素实现了Comparable的类的实例。
Stream<String> longestFirst = words.stream().sorted(Comparator.comparing(String::length).reversed());
//长字符排在前
- Stream
peek(Consumer<? super T> action)
产生一个流,它与当前流中的元素相同,在获取其中每个元素是,会将其传递给action。如:
Object[] powers = Stream.iterate (1.0,p -> p*2)
.peek (e -> System.out.println ("Fetching" + e))
.limit (20).toArray ();
当实际访问一个元素时,就会打印出一条消息。通过这种方式,你可以验证iterate返回的无限流是被惰性处理的。
对应调试,你可以让peek调用一个你设置了断点的方法。
由于目前应用较少流操作日后补齐
Java反射
理解Class类
Java程序在运行时,Java运行时系统一直对所有的对象进行所谓的运行时类型标识,即所谓的RTTI。这项信息纪录了每个对象所属的类。虚拟机通常使用运行时类型信息选准正确方法去执行,用来保存这些类型信息的类是Class类。Class类封装一个对象和接口运行时的状态,当装载类时,Class类型的对象自动创建。
简单的说:
- Class类也是类的一种,只是名字和class关键字高度相似。Java是大小写敏感的语言。
- Class类的对象内容是你创建的类的类型信息,比如你创建一个shapes类,那么,Java会生成一个内容是shapes的Class类的对象
- Class类的对象不能像普通类一样,以 new shapes() 的方式创建,它的对象只能由JVM创建,因为这个类没有public构造函数
- Class类的作用是运行时提供或获得某个对象的类型信息,和C++中的typeid()函数类似。这些信息也可用于反射。
Class类就像是JVM为每个类创建一个镜像一样,就像照镜子一样.
Class类封装了什么信息?
Class是一个类,封装了当前对象所对应的类的信息
一个类中有属性,方法,构造器等,比如说有一个Person类,一个Order类,一个Book类,这些都是不同的类,现在需要一个类,用来描述类,这就是Class,它应该有类名,属性,方法,构造器等.Class是用来描述类的类.
- Class类是一个对象照镜子的结果,对象可以看到自己有哪些属性,方法,构造器,实现了哪些接口等等.
- 对于每个类而言,JRE 都为其保留一个不变的 Class 类型的对象。一个 Class 对象包含了特定某个类的有关信息.
- Class 对象只能由系统建立对象,一个类(而不是一个对象)在 JVM 中只会有一个Class实例.
对象为什么需要照镜子呢?
- 有可能这个对象是别人传过来的
- 有可能没有对象,只有一个全类名
通过反射,可以得到这个类里面的信息
获取Class对象
可以通过如下方法获取Class对象:
- 通过类名获取 类名.class
- 通过对象获取 对象名.getClass()
- 通过全类名获取 Class.forName(全类名)
class Person {
public String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//包含一个带参的构造器和一个不带参的构造器
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Person() {
super();
}
}
public class Main {
public static void main(String[] args) {
Class PerClass = null;
//1.通过 类名.class
PerClass = Person.class;
//2.通过 对象名.getClass()
Person person = new Person();
PerClass = person.getClass();
//3.通过全类名(会抛出异常)
//一般框架开发中这种用的比较多,因为配置文件中一般配的都是全类名,通过这种方式可以得到Class实例
try {
PerClass = Class.forName("Person");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
//字符串例子
Class StrClass = String.class;
StrClass = "javaTest".getClass();
try {
StrClass = Class.forName("java.lang.String");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
System.out.println();
}
}
Class常用方法:
| 方法名 | 说明 |
|---|---|
| static Class forName(String name) | 返回指定类名 name 的 Class 对象 |
| Object newInstance() | 调用缺省构造函数,返回该Class对象的一个实例 |
| Object newInstance(Object []args) | 调用当前格式构造函数,返回该Class对象的一个实例 |
| getName() | 返回此Class对象所表示的实体(类、接口、数组类、基本类型或void)名称 |
| Class getSuperClass() | 返回当前Class对象的父类的Class对象 |
| Class [] getInterfaces() | 获取当前Class对象的接口 |
| public Method[] getMethods() | 返回一个包含某些 Method 对象的数组,这些对象反映此 Class 对象所表示的类或接口(包括那些由该类或接口声明的以及从超类和超接口继承的那些的类或接口)的公共 member 方法。 |
| public Field[] getFields() | 返回一个包含某些 Field 对象的数组,这些对象反映此 Class 对象所表示的类或接口的所有可访问公共字段。返回数组中的元素没有排序,也没有任何特定的顺序。如果类或接口没有可访问的公共字段,或者表示一个数组类、一个基本类型或 void,则此方法返回长度为 0 的数组。 |
反射
反射概述
Reflection(反射)是Java被视为动态语言的关键,反射机制允许程序在执行期借助于Reflection API取得任何类的內部信息,并能直接操作任意对象的内部属性及方法。
Java反射机制主要提供了以下功能:
- 在运行时构造任意一个类的对象
- 在运行时获取任意一个类所具有的成员变量和方法
- 在运行时调用任意一个对象的方法(属性)
- 生成动态代理
Class 是一个类,一个描述类的类.
- 封装了描述方法的 Method,
- 描述字段的 Filed,
- 描述构造器的 Constructor 等属性.
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
class Person {
public String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
//包含一个带参的构造器和一个不带参的构造器
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public Person() {
super();
}
}
public class Main {
public static void main(String[] args) {
Class PerClass = null;
PerClass = Person.class;
//获取方法,不能获取private方法,且获取从父类继承来的所有方法。
Method[] methods = PerClass.getMethods();
for(Method method:methods){
System.out.print(" "+method.getName());
}
System.out.println();
//要想获得所有方法可以用getDeclaredMethods(),所有声明的方法,都可以获取到,且只获取当前类的方法。
/*
methods = PerClass.getDeclaredMethods();
for(Method method:methods){
System.out.print(" "+method.getName());
}
System.out.println();
*/
//获取指定的方法,需要参数名称和参数列表,无参则不需要写.
Method method = null;
// 而对于方法public void setName(int age) { }
try {
method = PerClass.getDeclaredMethod("setName", String.class);
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
System.out.println(method);
/*
// 而对于方法public void setAge(int age) { }
try {
method = PerClass.getDeclaredMethod("setAge", int.class);
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
System.out.println(method);
*/
//使用invoke执行方法
//invoke第一个参数表示执行哪个对象的方法,剩下的参数是执行方法时需要传入的参数
//创建一个实例
Object obj = null;
try {
obj = PerClass.newInstance();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
try {
method.invoke(obj,"hank");
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
//将Object对象转成Person对象
Person person = (Person)obj;
System.out.println(person.getName());
//私有方法的执行,必须在调用invoke之前加上一句method.setAccessible(true);
}
}
Java注解(元数据)
在了解注解之前首先我们来看一个与之相近的概念:注释.所谓注释就是用文字性的东西将程序的功能描述清楚,为了让程序员可以很轻松地阅读程序,它就像一个程序的说明书一样.那么注解可以说是用文字性的东西(与注释不同的是,注解用@开头)来解释说明程序的,为了让计算机清楚地运行程序,它就像给程序打了一个标签一样,解释说明注解下的代码有什么作用.
注解作用
编写文档
通过代码里标识的注解生成文档.例如将下列代码生成文档.
/**
* 通过注解生成文档
* @author hank
* @version 1.0
* @since 1.5
*/
public class TestAnno {
/**
* 计算两数的和
* @param a int
* @param b int
* @return 两数的和
*/
public int add(int a ,int b){
return a + b;
}
}
使用javadoc命令根据文档注释中的注解生成文档.会生成如下结果:
编译检查
通过代码里标识的注解让编译器能够实现基本的类型检查.例如:@override.
代码分析
通过代码里标识的注解对代码进行分析.(使用反射机制)
在编写文档和编译检查中的注解一般都是JDK自带的我们知道如何使用就好.最重要的是了解代码分析,这也是很多框架中常用的技术.了解清楚注解的机制对我们阅读框架会有很大帮助.
基本注解
JDK自带注解
- @Override 重写, 标识覆盖它的父类的方法.当子类重写父类方法时,子类可以加上这个注解,那这有什么什么用?这可以确保子类确实重写了父类的方法,避免出现低级错误.
- @Deprecated 已过期,表示方法是不被建议使用的.这个注解用于表示某个程序元素类,方法等已过时,当其他程序使用已过时的类,方法时编译器会给出警告(删除线,这个见了不少了吧).
- @Suppvisewarnings 压制警告,抑制警告.被该注解修饰的元素以及该元素的所有子元素取消显示编译器警告,例如修饰一个类,那他的字段,方法都是显示警告
- @Functionallnterface 函数式接口注解,当接口使用此注解是那么这个接口可用于lambda表达式.什么是函数式?如果接口中只有一个抽象方法(可以包含多个默认方法或多个static方法)接口体内只能声明常量字段和抽象方法,并且被隐式声明public,static,final。接口里面不能有私有的方法或变量。这个注解有什么用?这个注解保证这个接口只有一个抽象方法,注意这个只能修饰接口.
元注解(注解的注解)
-
@Target 表示该注解用于什么地方,可取的值包括:
ElemenetType.CONSTRUCTOR 构造器声明
ElemenetType.FIELD 域声明(包括 enum 实例)
ElemenetType.LOCAL_VARIABLE 局部变量声明
ElemenetType.METHOD 方法声明
ElemenetType.PACKAGE 包声明
ElemenetType.PARAMETER 参数声明
ElemenetType.TYPE 类,接口(包括注解类型)或enum声明
ElementType.ANNOTATION_TYPE 注解 -
@Retention 表示在什么级别保存该注解信息。可选的 RetentionPolicy 参数包括:
RetentionPolicy.SOURCE 注解将被编译器丢弃
RetentionPolicy.CLASS 注解在class文件中可用,但会被VM丢弃
RetentionPolicy.RUNTIME JVM将在运行期也保留注释,因此可以通过反射机制读取注解的信息。 -
@Documented 将此注解包含在 javadoc 中
-
@Inherited 允许子类继承父类中的注解
自定义注解
基本格式
public @interface TestAnnotation {
String name();//成员以无参数,无异常声明
int age() default 18;//可以用default为成员指定默认值
}
//例如:
@TestAnnotation(name="hank",age=20)
使用@interface定义注解
在注解中声明的方法,可以说是注解中的属性或成员.需要在使用注解时为成员赋值.如果只有一个成员可以忽略成员名和=
成员类型是受限的,只能是基本类型,String,Class,注解和枚举类型
注解本质
//这是上面注解反编译后的代码
public interface TestAnnotation extends java.lang.annotation.Annotation {
public abstract java.lang.String name();
public abstract int age();
}
注解的本质其实就是接口.
注解解析
@TestAnnotation(name = "hank",age = 20)
public class Main {
public static void main(String[] args) {
//判断要解析的类是否含有目标注解
boolean hasAnnotation = Main.class.isAnnotationPresent(TestAnnotation.class);
if ( hasAnnotation ) {
//获取类中注解的成员
TestAnnotation testAnnotation = Main.class.getAnnotation(TestAnnotation.class);
System.out.println("id:"+testAnnotation.name());
System.out.println("msg:"+testAnnotation.age());
}
}
}
JDBC
相关概念
什么是JDBC
JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语言编写的类和接口组成。JDBC提供了一种基准,据此可以构建更高级的工具和接口,使数据库开发人员能够编写数据库应用程序。
数据库驱动
我们安装好数据库之后,我们的应用程序也是不能直接使用数据库的,必须要通过相应的数据库驱动程序,通过驱动程序去和数据库打交道。其实也就是数据库厂商的JDBC接口实现,即对Connection等接口的实现类的jar文件。
常用接口和类
Driver接口
每个驱动程序类必须实现Driver接口。Java SQL框架允许多个数据库驱动程序。每个驱动程序都应该提供一个实现Driver接口的类。
DriverManager会试着加载尽可能多的它可以找到的驱动程序,然后,对于任何给定连接请求,它会让每个驱动程序依次试着连接到目标 URL。
强烈建议每个Driver类应该是小型的并且是单独的,这样就可以在不必引入大量支持代码的情况下加载和查询 Driver 类。
在加载某一Driver类时,它应该创建自己的实例并向DriverManager注册该实例。这意味着用户可以通过调用以下程序加载和注册一个驱动程序
Class.forName("foo.bah.Driver")
Connection接口
Connection接口与特定数据库的连接(会话)。在连接上下文中执行 SQL语句并返回结果。
Connection对象的数据库能够提供描述其表、所支持的SQL语法、存储过程、此连接功能等等的信息。此信息是使用getMetaData方法获得的。
常用方法
- createStatement():创建向数据库发送sql的statement对象。
- prepareStatement(sql) :创建向数据库发送预编译sql的PrepareSatement对象。
- prepareCall(sql):创建执行存储过程的callableStatement对象。
- setAutoCommit(boolean autoCommit):设置事务是否自动提交。
- commit() :在链接上提交事务。
- rollback() :在此链接上回滚事务。
Statement接口
Statement接口用于执行静态 SQL 语句并返回它所生成结果的对象。
在默认情况下,同一时间每个 Statement 对象在只能打开一个 ResultSet 对象。因此,如果读取一个 ResultSet 对象与读取另一个交叉,则这两个对象必须是由不同的 Statement 对象生成的。如果存在某个语句的打开的当前 ResultSet 对象,则 Statement 接口中的所有执行方法都会隐式关闭它。
常用方法
- execute(String sql):运行语句,返回是否有结果集
- executeQuery(String sql):运行select语句,返回ResultSet结果集。
- executeUpdate(String sql):运行insert/update/delete操作,返回更新的行数。
- addBatch(String sql) :把多条sql语句放到一个批处理中。
- executeBatch():向数据库发送一批sql语句执行。
PreparedStatement接口
PreparedStatement接口表示预编译的 SQL 语句的对象。
SQL 语句被预编译并存储在 PreparedStatement 对象中。然后可以使用此对象多次高效地执行该语句。(推荐使用PreparedStatement而不是Statement.他可以防止SQL注入攻击)
常用方法
- execute(String sql):运行语句,返回是否有结果集
- executeQuery(String sql):运行select语句,返回ResultSet结果集。
- executeUpdate(String sql):运行insert/update/delete操作,返回更新的行数。
- addBatch(String sql) :把多条sql语句放到一个批处理中。
- executeBatch():向数据库发送一批sql语句执行。
ResultSet接口
ResultSet接口表示数据库结果集的数据表,通常通过执行查询数据库的语句生成。
ResultSet 对象具有指向其当前数据行的光标。最初,光标被置于第一行之前。next 方法将光标移动到下一行;因为该方法在 ResultSet 对象没有下一行时返回 false,所以可以在 while 循环中使用它来迭代结果集。
ResultSet提供检索不同类型字段的方法,常用的有:
- getString(int index)、getString(String columnName):获得在数据库里是varchar、char等类型的数据对象。
- getFloat(int index)、getFloat(String columnName):获得在数据库里是Float类型的数据对象。
- getDate(int index)、getDate(String columnName):获得在数据库里是Date类型的数据。
- getBoolean(int index)、getBoolean(String columnName):获得在数据库里是Boolean类型的数据。
- getObject(int index)、getObject(String columnName):获取在数据库里任意类型的数据。
ResultSet还提供了对结果集进行滚动的方法:
- next():移动到下一行
- Previous():移动到前一行
- absolute(int row):移动到指定行
- beforeFirst():移动resultSet的最前面。
- afterLast() :移动到resultSet的最后面。
使用后依次关闭对象及连接:ResultSet → Statement(PreparedStatement) → Connection
JDBC操作流程
加载JDBC驱动程序
- Class.forName(“com.MySQL.jdbc.Driver”);
推荐这种方式,不会对具体的驱动类产生依赖。但是在JDK6之后可以不用显示的加载驱动了,加载驱动由DriverManager自动加载 - DriverManager.registerDriver(com.mysql.jdbc.Driver);
会造成DriverManager中产生两个一样的驱动,并会对具体的驱动类产生依赖。
建立数据库连接Connection
直接使用DriverManager建立连接
Connection conn = DriverManager.getConnection(url, user, password);
URL用于标识数据库的位置,通过URL地址告诉JDBC程序连接哪个数据库,URL的写法为:
创建执行SQL的语句PreparedStatement以及处理执行结果ResultSet
import java.sql.*;
public class Main {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:3306/test?useSSL=false&useUnicode=true&";
String username = "root";
String password = "root5271106";
/*
try{
Class.forName("com.mysql.cj.jdbc.Driver");
}catch (ClassNotFoundException e){
e.printStackTrace();
}
*/
Connection connection = null;
PreparedStatement PStatement = null;
String sql = "SELECT * FROM Student;";
try {
connection = DriverManager.getConnection(url, username, password);
PStatement = connection.prepareStatement(sql);
ResultSet rs = PStatement.executeQuery();
while(rs.next())
{
String number = rs.getString(1);
String name = rs.getString(2);
String sex = rs.getString(3);
int age = rs.getInt(4);
String dept = rs.getString(5);
System.out.println(number + " " + name + " " + sex + " " + age+ " " + dept);
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/*
结果为:
201215121 李勇 男 20 CS
201215122 刘晨 女 19 CS
201215123 王敏 女 18 MA
201215125 张立 男 19 IS
201215126 李刚 男 20 MA
*/
释放资源
//数据库连接(Connection)非常耗资源,尽量晚创建,尽量早的释放
//都要加try catch 以防前面关闭出错,后面的就不执行了
try {
if (rs != null) {
rs.close();
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
if (PStatement != null) {
PStatement.close();
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}