学会了Redis的基本操作还不够,再来看看升级部分
1. 数据删除策略
惰性删除+定期删除(默认)
定期删除:默认是每隔 100ms 就轮询各个库随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。每隔100ms就遍历所有的设置过期时间的 key 的话,是个损耗。
惰性删除:定期删除会导致很多过期 key 到了时间并没有被删除掉。除非系统去查询才会删除。如果靠定期删除,和没有走惰性删除的话会导致一大部分过期数据没有删除,这时候就出现了内存淘汰机制
2. 内存淘汰机制
在数据进入内存的时候发现内存不够了,就采用内存淘汰机制,不一定淘汰过期的
其配置有:
- maxmemory:最大可用内存
- maxmemory-samples:每次选取删除数据的个数
- maxmemory-policy:删除策略
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)最近最久未使用
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)最近最少使用
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)随机淘汰
- allkeys-lru:在全库数据中(server.db[i].dict),最近最久未使用(这个是最常用的)
- allkeys-lfu:在全库数据中(server.db[i].dict),最近最少使用
- allkeys-random:在全库数据中(server.db[i].dict)随机淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用
3. 限制登录次数功能
- 判断用户是否被限制登录
- 有:做相应的提示
- 没有
- 登录成功:清除失败错误次数
- 登录不成功(查询key是否存在,即是否第一次 错误)
- 第一次错误:设次数为1,user:loginCount:fail:用户名进行赋值,同时设置失效期
- 不是第一次
- (判断是否4次,是的话这次加1等于5,限制1小时),user:loginCount:fail:用户名+1
- 小于第四次,失败次数加1
// 这里笔者用了不规范的返回值,返回数值大于10表示被限制登录
public long login(String username, String password) {
// 先判断是否被限制,
if (jedis.exists("user:loginCount:limit:" + username)) {
return jedis.ttl("user:loginCount:limit:" + username);
}
// 然后查询数据库返回结果,这里模拟查询设数据库,密码输入错误
if (!username.equals(password)) {
long count = 0;
// 第一次错误,键不存在,设置过期时间,10秒内可以错误5次
if (!jedis.exists("user:loginCount:fail:" + username)) {
jedis.setex("user:loginCount:fail:" + username, 10, "1");
return 1;
} else {
count = jedis.incr("user:loginCount:fail:" + username);
if (count == 5) {
jedis.setex("user:loginCount:limit:" + username, 10, ""); // 设置登录限制时间
jedis.del("user:loginCount:fail:" + username); // 删除登录次数,因为被登录限制
}
return count; // 返回已尝试次数
}
}
// 密码正确,清除错误次数
jedis.del("user:loginCount:fail:" + username);
return 0L; // 表示密码正确
}
4. 消息订阅
subscribe channel[channel] 订阅频道
psubscribe pattern[pattern] 订阅匹配的频道
publish channel message 将消息发送到指定频道
unsubscribe [channel | channel] 退订频道
punsubscribe [pattern | pattern] 退订匹配的频道
应用场景:
- 构建实时消息系统
- 普通的即时聊天,群聊
- 粉丝订阅之后,发布新文章的消息推送,公众号模式
5. 缓存雪崩
Redis过期是惰性删除+定期删除,如果缓存数据设置的过期时间相同,那么当这些数据全部过期时,就会在这段时间全部请求走数据库中。简单就是Redis某段时间,或直接挂了,请求全走数据库,那么导致数据库支持不住而宕机。
解决方法:
- 给过期时间加上一个随机值(数据分类过期),减少大幅度同一时间过期问题
- 事前:可以用集群或高可用来尽量避免
- 事发中:使用本地缓存+限流(比如验证码)
- 事发后:redis的持久化,从硬盘上恢复数据
6. 缓存穿透
大量查询不存在的数据,导致每次返回空,Redis不起作用,相当于直接访问数据库。
解决方法:
- 请求参数的校验,使之不能进入到redis,更不要说数据库了
- 查询不存在数据时,也将这个数据放入Redis,下次访问可以从里面获取,当然要设置过期时间
- 布隆过滤器、限流算法、令牌桶
7. 缓存与数据库的读写一致
读:
- 如果查询数据缓存里有,直接返回
- 缓存里没有,去数据库查询,将查询结果放入缓存,并返回给客户端
对于更新时:会导致缓存数据和数据库不一致,可以先修改数据库,再修改缓存。或者先修改缓存,再修改数据库,重点在于我们要是这两个操作突显原子性,这样数据才不会出错
操作缓存:可以选择更新和删除,但一般采取删除操作。因为删除相对比更新更直接简单,如果每次更新数据库都要更新缓存,如果频繁更新的话,会频繁修改一定程度损耗性能,不如直接删除,再次读取时缓存没有就到数据库查找
先更新数据库再删除缓存:也有概率出错但很低,比如缓存失效,线程A查询数据库得到旧值,期间线程B将新值写入数据库,线程B删除缓存,然后线程A才将旧址写入缓存。删除缓存失败策略是,不断重试删除,直到成功。
先删除缓存,再更新数据库:如果原子性被破坏了,第一步成功删除缓存,第二步更新数据库失败,那么数据库数据是一致的,如果第一步删除缓存失败了,可以直接返回错误,数据库数据和缓存还是一致。
但是:线程A删除了缓存,期间线程B查询会走数据库得到旧值,并把旧值写入缓存,然后线程A才将新值写入数据库,导致数据不一致,解决方法:将删除缓存,修改数据库,读取缓存等操作挤压到队列里,实现串行化。
二者对比:
前者:高并发下表现优异,原子性破坏时不好
后者:高并发下串行,原子性破坏时优异
8. 持久化
Redis是基于内存的,万一遇到宕机那么内存中的数据则会丢失,而持久化则是将内存中的数据保存到硬盘防止丢失。Redis支持两种方式的持久化方式:RDB、AOF
1. RDB
创建内存中数据的二进制快照来实现持久化,可对快照备份或把快照复制到其他服务器使之成为服务器副本,还可以将快照留在原地以便重启服务器加载使用,默认持久化文件为dump.rdb
save命令执行一次就保存一次,若数据量过大,加入单线程任务执行会阻塞任务,所以不建议使用
bgsave命令后台运行,fork子进程来进行持久化,成功后记录到日志中
自动执行持久化:需在redis.conf中配置,执行多少次非查询操作就保存
- save 900 1
- save 300 10
- save 60 10000
优点:
- 紧凑压缩的二进制文件,存储效率高
- 存储的是某个时间点的快照,适合数据备份,全量复制
- 恢复数据速度比AOF快很多
- 应用:每隔一段时间执行bgsave备份,用于灾难恢复
缺点:
- 不能实时持久化,间隔时间段的数据可能丢失
- fork子进程,内存额外消耗
- 数据量大时,持久化速度慢,全部数据持久化
2. AOF
将除查询外的命令追加保存到AOF文件中,重启时重新执行AOF文件中的命令达到恢复数据的目的,是主流的持久化方式,默认没有开启,持久化文件为appendonly.aof
持久化数据的三种策略(写命令刷新到aof命令缓冲区)
- always 每次
- everysec 每秒
- no 系统控制
配置文件
- appendonly yes|no
- appendfsync always|everysec|no
AOF重写机制
将Redis进程内的数据转化为写命令同步到新的AOF文件的过程,即将对同一个数据的若干命令的执行结果合并成一条操作指令(忽略超时数据,忽略无效指令删除等,合并重复指令),可降低文件大小,提高持久化与恢复效率,其也有重写缓冲区,下面是重写命令:
- bgrewriteaof 手动重写
- auto-aof-rewrite-min-size size 配置自动重写(当aof缓存了多少)
- auto-aof-rewrite-percentage percentage 配置自动重写(%)
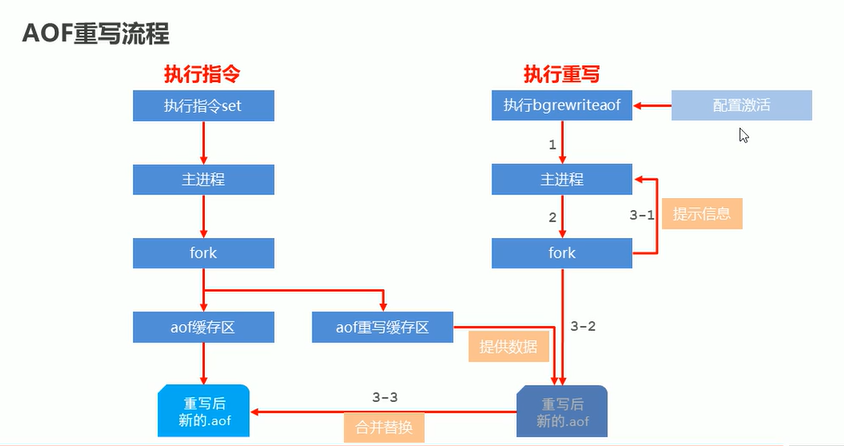
参考黑马教程
优点:
- AOF持久化的实时性更好
- 持久化速度快,追加命令
缺点:
- 因为记录命令,持久化文件大
- 恢复数据慢,要执行命令
9. 事务
Redis 通过 MULTI、EXEC命令来实现事务(transaction)功能,其事务实质是将多个命令打包后一次性地按顺序执行,期间不会执行其他客户端的命令请求,简单来说是命令串行化执行功能,没有回滚功能。关系型数据库用 ACID 检验事务功能的可靠性和安全性。而 Redis 中,事务总是具有原子性、一致性、隔离性,当持久化时,事务也具有持久性
MULTI:开启事务,创建队列,命令来了加入队列
EXEC:执行事务,队列中执行命令,完后销毁队列
DISCARD:取消事务,销毁队列
流程:
- 开始事务
- 命令入队,命令不会立即执行
- 执行事务,按上面入队顺序执行
举例转账:multi开始事务,exec执行事务
set account:a 100
set account:b 100
multi
get account:a
"QUEUED"
get account:b
"QUEUED"
decrby account:a 10
"QUEUED"
incrby account:b 10
"QUEUED"
exec
1) "100"
2) "100"
3) "90"
4) "110"
Redis的事务是没有回滚功能的,在进行事务的时候,只有报错的命令不会执行(例外:语法错误整个队列都不会执行,类型错误会执行),其他命令都会执行。只是单纯的执行事务的时候不会有其他命令加塞
场景:动物园给熊猫投喂竹子,这里有很多个饲养员,只要其中一个投喂了,其他饲养员就不用再投喂,使用watch解决
WATCH:执行事务前,监视Key是否被修改,若有则取消事务,返回nil(针对同时修改用处大)
UNWATCH:取消监视
watch eat
// 中间可以执行其他命令,必须在开启事务前watch
multi
set panda 1
exec
10. 主从复制
repl-backlog-size 设置指令缓冲区
slave-server-stale-data yes|no slave关闭写功能
- 建立连接

方式1:
客户端发送 slaveof <masterip> <masterport>
auth <password>
方式2:
启动式服务器参数 redis-server -slavveof <masterip> <masterport>
方式3
slave配置文件:slaveof <masterip> <masterport>
masterauth 123456
主从复制低版本不能复制高版本的数据,笔者在这里花了挺久时间才找出问题所在
- 数据同步
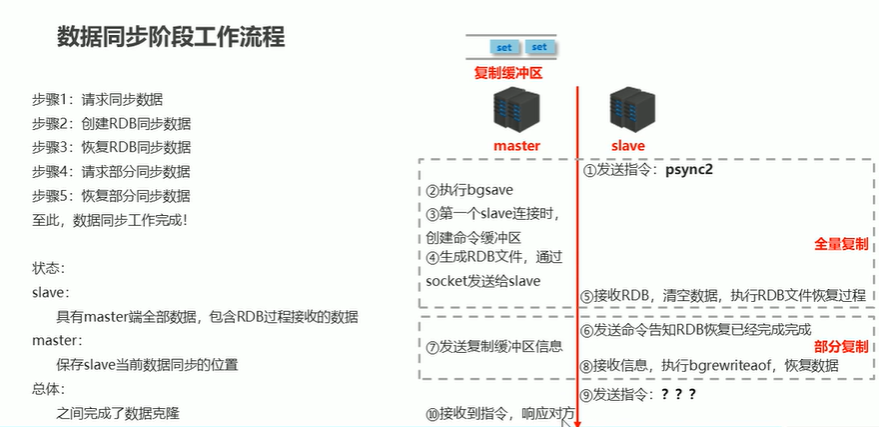
- 命令传播

- 心跳机制
进入命令传播阶段时,master和slave的信息交换使用心跳机制维护,实现双方连接保持在线
主从复制的作用
- master写,slave读,提高读写负载能力
- 负载均衡,基于主从结构,配合读写分离
- 故障恢复,当master故障时,由slave提供服务,实现快速恢复
- 数据冗余,实现数据热备份
- 高可用基础
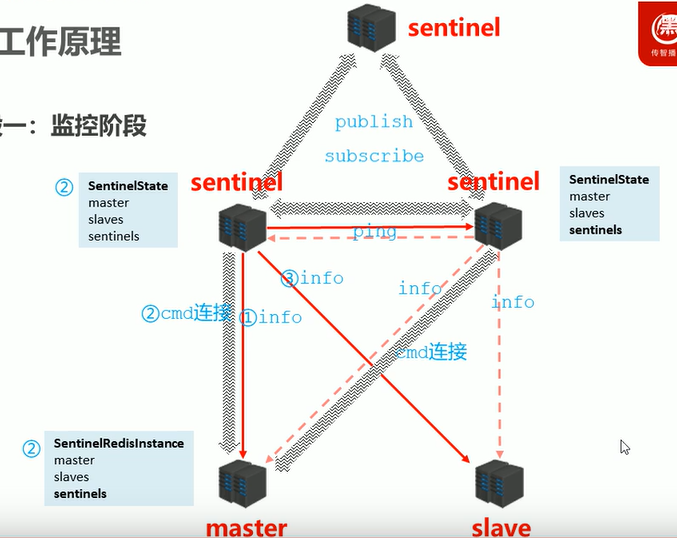
11. 哨兵模式Sentinel(主备切换)
哨兵是一个分布式系统,也是一台redis服务器,对于主从结构中的每台服务器进行监控,出现故障时投票机制选择新的master并将所有slave连接到新的master,演示搭建三个哨兵和1主2从
sentinel.conf的配置文件
monitor mymaster 127.0.0.1 6379 2 // 监听主服务器,自定义名字,后面2表示多少个哨兵认为宕机才有效
down-after-millisecoinds mymaster 30000 // 多久才认为宕机
parallel-syncs mymaster 1 // 命令传播
failover-timeout mymaster 180000 // 复制超时时间
先启动1主2从,再启动哨兵
redis-sentinel sentinel-26379.conf
redis-sentinel sentinel-26380.conf
redis-sentinel sentinel-26381.conf
启动哨兵后,每台服务器的配置都会有对应的修改
哨兵模式的流程:
- 1.监控阶段
- 获取各sentinel的状态(是否在线)
- 获取master的状态
- master属性
- runId
- role:master
- 各个slave的详细信息
- master属性
- 获取所有slave的状态(根据master中的slave信息)
- slave属性
- runId
- role:slave
- master_host、master_port
- offset
- slave属性
- 2.通知阶段
- 不停地用ping去测试
- 3.故障转移
- 发现问题
- 竞选负责人
- 优选新master
- 在线的
- 响应快的
- 与原master断开时间最短的
- 优先原则:优先级、offset、runId
- 新master上线,其他slave切换master,原master作为slave故障恢复后连接

12. 集群
分散单台服务器的访问压力,即负载均衡
其底层存储原理:
- 将key进行两次算法运算得key应该保存的位置(CRC16(key) % 16384)
- 将所有Redis服务器的总存储空间计划切割成16384份,每台主机保存一部分
- 加Redis服务器的话,原本服务器将槽分给新的服务器、删除服务器则相反
- 集群内部通讯:记录各服务器槽范围,一次命中OK,否则服务器查询通讯录让请求去对应槽服务器(最多2次命中)
- 内部通讯这样就不用虚拟IP了
配置3主3从(官方自带,每个服务器都要配置)
cluster-enabled yes // 开启集群节点
cluster-config-file nodes-6379 // 集群配置文件
cluster-node-timeout 10000 // 宕机时间
src下有redis-trib.rb(需要Ruby、Gem支持)
./redis-trib.rb create --replicas 1 // 其中1表示1主拖1从
127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381
127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
客户端启动
redis-cli -c
// 不然key和服务器没有对应上会报错,让你去连对应的服务器。加了配置会帮你重定向
故障处理:
- 从服务器下线,各个节点能收到通知,对应master节点会标记一下宕机从服务器
- 主服务器下线,对应从服务器重试,失败就执行上面的主从切换,切换的从顶替了主集群。原主上线变成slave
13. 并发竞争Key问题
所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同
推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
参考
https://www.bilibili.com/video/BV1CJ411m7Gc?p=101