数据归一化和两种常用的归一化方法
数据标准化(归一化)处理是数据挖掘的一项基础工作,不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。
以下是两种常用的归一化方法:
1. min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 - 1]之间。转换函数如下:

其中max为样本数据的最大值,min为样本数据的最小值。这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,就是当有新数据加入时,可能导致max和min的变化。如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代max和min。
2. Z-score标准化方法
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,转化函数为:

其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
例如:
import numpy as np
from sklearn import preprocessing
#准备工作 创建样本数据
data = np.array([[3,-1.5,2,-5.4],[0,4,-0.3,2.1],[1,3.3,-1.9,-4.3]])
#均值移除(Mean removal)
"""通常我们会把每个特征的平均值移除,以保证特征均值为0(即标准化处理)。这样做可以消
除特征彼此间的偏差(bias)。将下面几行代码加入之前打开的Python文件中: """
data_standardized = preprocessing.scale(data)
print("Mean = ", data_standardized.mean(axis = 0))
print("Std deviation = ",data_standardized.std(axis = 0))
输出:
Mean = [ 5.55111512e-17 3.70074342e-17 -7.40148683e-17 -7.40148683e-17]
Std deviation = [ 1. 1. 1. 1.]
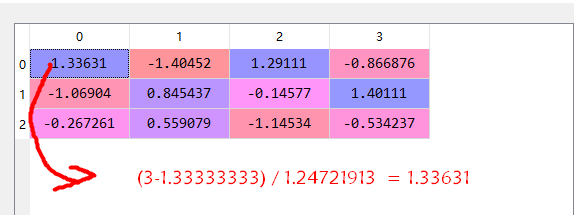
我们看下data里面的数据:

再看下data_standardized里面的数据:

注意axis = 0可以看成是逐行操作:
In [27]: data.mean(axis = 0)
Out[27]: array([ 1.33333333, 1.93333333, -0.06666667, -2.53333333])
In [28]: data.std(axis = 0)
Out[28]: array([ 1.24721913, 2.44449495, 1.60069429, 3.30689515])
再用公式:
即可得到上面data_standardized里面的值
独热编码 (One-Hot Encoding)
来一个sklearn的例子:
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]]) # fit来学习编码
enc.transform([[0, 1, 3]]).toarray() # 进行编码
输出:
array([[ 1., 0., 0., 1., 0., 0., 0., 0., 1.]])
分析
数据矩阵是4*3,即4个数据,3个特征维度(向量)。
0 0 3 # 观察左边的数据矩阵,第一列为第一个特征维度,有两种取值01. 所以分别对应编码方式为10 、01(即0对应10,1对应01)
1 1 0 # 同理,第二列为第二个特征维度,有三种取值012,所以分别对应编码方式为100、010、001
0 2 1 # 同理,第三列为第三个特征维度,有四中取值0123,所以分别对应编码方式为1000、0100、0010、0001
1 0 2
再来看要进行编码的参数[0 , 1, 3]:
0作为第一个特征编码为10, 1作为第二个特征编码为010, 3作为第三个特征编码为0001. 故此编码结果为 1 0 0 1 0 0 0 0 1
删除pandas DataFrame的某一/几列
- 方法1:直接del DF['column-name']
- 方法2:采用
drop方法,有下面三种等价的表达式:
1. DF= DF.drop('column_name', 1);
2. DF.drop('column_name',axis=1, inplace=True)
3. DF.drop([DF.columns[[0,1, 3]]], axis=1,inplace=True) # Note: zero indexed
注意:
凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换。也就是说,采用inplace=True之后,原数组名(如2和3情况所示)对应的内存值直接改变;而采用inplace=False之后,原数组名对应的内存值并不改变,需要将新的结果赋给一个新的数组或者覆盖原数组的内存位置(如1情况所示)。
参考资料:https://stackoverflow.com/questions/13411544/delete-column-from-pandas-dataframe-using-python-del