k-近邻算法根据特征比较,然后提取样本集中特征最相似数据(最邻近)的分类标签。那么,如何进行比较呢?
怎么判断红色圆点标记的电影所属的类别呢? 如下图所示。
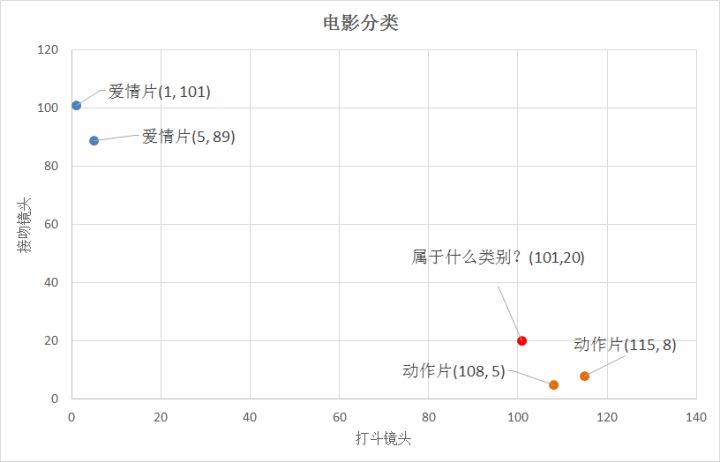
答:距离度量。这个电影分类的例子有2个特征,也就是在2维实数向量空间,可以使用两点距离公式计算距离,如图所示。
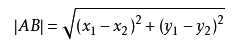
k-近邻算法步骤如下:
- 1.计算已知类别数据集中的点与当前点之间的距离;
- 2.按照距离递增次序排序;
- 3.选取与当前点距离最小的k个点;
- 4.确定前k个点所在类别的出现频率;
- 5.返回前k个点所出现频率最高的类别作为当前点的预测分类。
接下来就是使用Python3实现该算法,以电影分类为例。
(1)准备数据集
(2)k-近邻算法
根据两点距离公式,计算距离,选择距离最小的前k个点,并返回分类结果。
# -*- coding: utf-8 -*-
"""
k-近邻算法
标签分类
group:数据集
lables:标签分类
"""
import numpy as np
import operator
def createDataSet():
#四组二维特征
group = np.array([[1,101],[5,89],[108,5],[115,8]])
#四组特征的标签
labels = ['爱情片','爱情片','动作片','动作片']
return group,labels
# =============================================================================
# if __name__ == '__main__':
# #创建数据集
# group, labels = createDataSet()
# print(group)
# print(labels)
# =============================================================================
"""
k-近邻算法
根据两点距离公式,计算距离,选择距离最小的前k个点,并返回分类结果。
"""
def classify0(inX,dataSet, labels,k):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#print("dataSetSize:",dataSetSize)
#np.tile()表示:在行方向上重复inX数据共1次,在列方向重复inX共dataSetSize次
diffMat = np.tile(inX,(dataSetSize,1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#print(sqDiffMat)
#sum()表示所有元素相加,sum(0)列向量相加,sum(1)行向量分别相加
sqDistances = sqDiffMat.sum(axis = 1)
#print(sqDistances)
#开方求距离
distances = sqDistances**0.5
print(distances)
#argsort()返回的是distances中元素从小到大排序的索引值
sortedDistIndicies = distances.argsort()
print("sortedDostIndicies=",sortedDistIndicies)
#定义一个记录类别次数的字典
classCount = {}
for i in range(k):
print("sortedDistIndicies[",i,"] = ",sortedDistIndicies[i])
voteIlabel = labels[sortedDistIndicies[i]] #排名前k个贴标签
print("voteIlabel=",voteIlabel)
#dict.get(key,defualt = None),字典的get()方法,返回指定键的值,如果值不在字典中,返回默认值
#计算类别次数
#print ("类别 次数:",classCount.get(voteIlabel,0))
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1 #不断累加计数的过程,体现在字典的更新中
print("classCount[",voteIlabel,"]为 :",classCount[voteIlabel])
#python3中用items()替换python2中的iteritems()
#key = operator.itemgetter(1)根据字典的值进行排序
#key = operator.itemgetter(0)根据字典的键进行排列
#reverse降序排列字典
sortedClassCount = sorted(classCount.items(),key = operator.itemgetter(1),reverse = True)
print("sortedClassCount: ",sortedClassCount)
#返回出现次数最多的value的key
return sortedClassCount[0][0]
if __name__ == '__main__':
#创建数据集
group,labels = createDataSet()
test = [101,20]
#KNN分类
test_class = classify0(test,group,labels,3)
#打印分类结果
print(test_class)
----------------------------------------------------------------------------------------------
# 实现 classify0() 方法的第二种方式
---------------------------------------------------------------------------------------------
# """
# 1. 计算距离
# 欧氏距离: 点到点之间的距离
# 第一行: 同一个点 到 dataSet的第一个点的距离。
# 第二行: 同一个点 到 dataSet的第二个点的距离。
# ...
# 第N行: 同一个点 到 dataSet的第N个点的距离。
# [[1,2,3],[1,2,3]]-[[1,2,3],[1,2,0]]
# (A1-A2)^2+(B1-B2)^2+(c1-c2)^2
# inx - dataset 使用了numpy broadcasting,见 https://docs.scipy.org/doc/numpy-1.13.0/user/basics.broadcasting.html
# np.sum() 函数的使用见 https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.sum.html
# """
# dist = np.sum((inx - dataset)**2, axis=1)**0.5
# """
# 2. k个最近的标签
# 对距离排序使用numpy中的argsort函数, 见 https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.sort.html#numpy.sort
# 函数返回的是索引,因此取前k个索引使用[0 : k]
# 将这k个标签存在列表k_labels中
# """
# k_labels = [labels[index] for index in dist.argsort()[0 : k]]
# """
# 3. 出现次数最多的标签即为最终类别
# 使用collections.Counter可以统计各个标签的出现次数,most_common返回出现次数最多的标签tuple,例如[('lable1', 2)],因此[0][0]可以取出标签值
# """
# label = Counter(k_labels).most_common(1)[0][0]
# return label
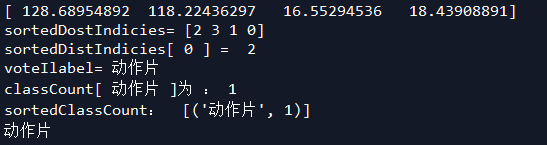
输出结果:
参考来源: