转摘:https://www.sohu.com/a/300171946_692358
引言:本文重点是用十分钟的时间帮读者建立Python数据分析的逻辑框架。其次,讲解“如何通过Python 函数或代码和统计学知识来实现数据分析”。
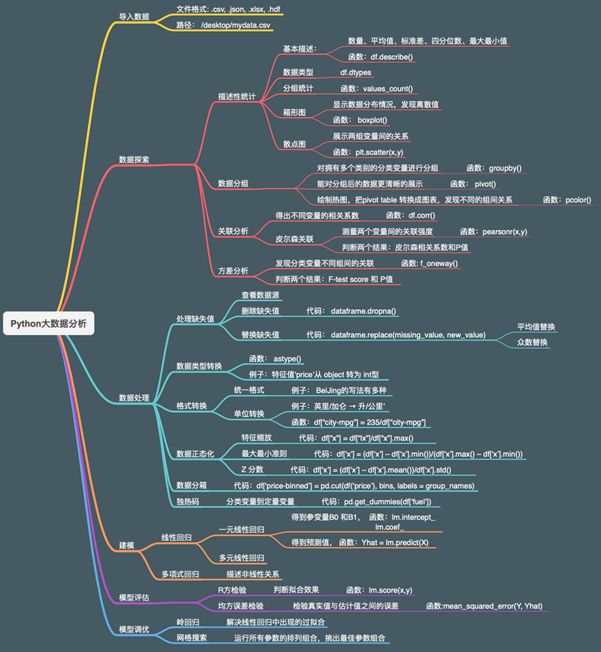
本次介绍的建模框架图分为六大版块,依次为导入数据,数据探索,数据处理,建模,模型评估,模型调优(完整的逻辑框架图请看文章末尾处)。
在实际商业项目中,建模前的工作占据整个项目70%左右的时间。读者可能会问你既然是模型预测,为什么不把更多时间放在模型和调参上?因为巧妇难为无米之炊,数据本身决定了模型预测的上限,而模型或算法只是无限逼近这个上限而已。正所谓兵马未动粮草先行,数据探索和数据处理能为之后建模打下坚实基础,因此团队做项目时会把大量时间投放在这两个部分,目的在于提高数据质量,发现变量间关系,选取恰当特征变量。下面我会依次介绍这六个版块,但详解数据探索和数据处理版块。
一 导入数据
Python数据分析的第一步是要把数据导入到Python中。导入数据需要做两件事,第一,告诉Python 你的文件格式,常用的格式有:.csv,.jason, .xlsx, .hdf。第二,告诉Python 你的文件路径。
举例:假如文件格式为.csv, 文件路径为:path =“C:Windows...desktopmydata.csv”
通过df.read_csv(path)函数,即可将数据导入Python。

二 数据探索
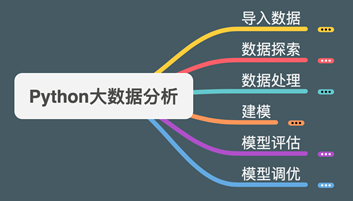
数据探索版块主要涉及描述性统计,数据分组,关联分析,方差分析。会涉及一些Python函数和统计学知识,笔者依次介绍。
描述性统计
Ø 基本描述
通过df.describe()函数可对数据有一个基本了解,比如平均值、标准差、四分位数、最大最小值等
Ø 数据类型
通过df.dtypes 函数,可知变量的数据类型,比如object型,int型,float型(为后面的数据处理做准备)
Ø 分组统计
通过value_counts(),可统计分类变量里不同组的数量
Ø 箱形图
通过sns.boxplot(x,y,data=df),可将数据以‘箱形’展示出来,查看数据分布情况,识别离散值
Ø 散点图
通过plt.scatter(x,y),可发现两组变量间的关系(正相关、负相关、不相关)
数据分组
数据分组部分主要介绍三个函数,分别为groupby(),pivot(), pcolor(),可视化效果依次提高,有助于快速发现不同组间的关系。
Ø 函数groupby(),可对一个或多个分类变量进行分组
Ø 函数pivot(), 能提高groupby()分组后的数据的可视化程度,实现更清晰的展示
Ø 函数pcolor(), 能把pivot table()处理后的数据转换成热图,更易发现不同组间关系
关联分析
Ø 通过df.corr(), 可得到所有变量间的相关系数
Ø 通过pearsonr(x,y),可得到皮尔森相关系数和P值,以此判断两个变量间的关联强度
· 皮尔森系数接近于1时,正相关;接近于-1时负相关;接近于0时,不相关
· P值,用来判断发生的可能性大小、原假设是否正确。若P<0.05, 有理由拒绝原假设。
方差分析
Ø f_oneway()实现方差分析,得到F-testscore 和P 值
Ø F-testscore 越大,关联越强; F-testscore 越小,关联越弱。
Ø P值,同上(参见关联分析P值)
笔者总结出(二)数据探索版块的逻辑框架图,见下图。

三 数据处理
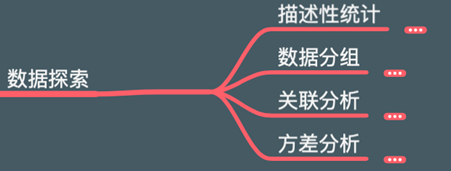
数据处理版块主要涉及处理缺失值,数据类型转换,格式转换,数据正态化,数据分箱,独热码。会涉及Python代码和统计学知识,笔者依次介绍。
处理缺失值
Ø 查看数据源
直接查看数据源头,看能否把缺失的数据找回
Ø 删除缺失值
通过函数dataframe.dropna(),可将缺失的数据删除
Ø 替换缺失值
通过函数data.replace(missing_value,new_value),可将缺失的数据替换为平均值或众数
数据类型转换
Ø 通过astype()函数,能把错误的数据类型转换为正确的数据类型
Ø 举例:若变量‘price’的数据类型为object型时,通过代码:df[‘price’]= df[‘price’].astype(‘int’),将变量‘price’转换为 int型。
格式转换
不同部门(比如市场部、物流部、IT部)通常会有不同的储存格式,需要对数据统一格式、单位转换,才可建模。
Ø 统一格式
举例:BeiJing的书写格式有多种,比如BeiJing, BEIJING, BJ, B.J, 需要统一为一种格式。
Ø 单位转换
· 对同一特征变量,要用统一的单位,举例:在评比汽车耗油量时经常用到两种单位,每加仑多少英里(mpg)和每百公里多少升(L/100km),在数据分析时需将其统一。
· 例子:通过函数df[‘city-mpg’]= 235/df[‘city-mpg’] 实现mpg 和 L/100km 单位间的转换(其实就是加减乘除),再通过df.rename()对变化后的列名进行修改

数据正态化
某些特征变量需要进行数据正态化,正态化后的特征变量才能对模型有相对公平的影响(若没懂,请看特征缩放中的例子)。常用的数据正态化的方法有三种:特征缩放,最大最小值,Z分数。

Ø 特征缩放:Xnew=Xold/Xmax
举例:变量‘age’的范围20 – 100 ,变量‘income’ 的范围20000 – 500000,由于数值大小的差距,变量‘age’和‘income’对模型的影响是完全不同和不公平的。经过特征缩放运算后,两个变量会拥有相似的取值范围,也因此对模型影响的程度会变得较为公平合理,代码见上图。

Ø 最大值最小值:Xnew=(Xold-Xnew)/(Xmax-Xmin), 代码见上图
Ø Z分数: Xnew = (Xold-μ)/σ, 代码见上图
数据分箱
数据分箱能对数据进行更明了的展示,可把数值变量转换为分类变量,通过cut()函数可对数据进行分箱,代码见下图。
举例:cut()函数能将变量‘price’的所有数值放入3个箱子中,将变量‘price’的数值变量转换为分类变量,运行结果见下图。

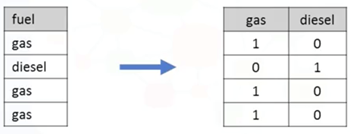
独热码
模型训练通常是不会接收object 或 string型,只能接收数值型,但独热码能将分类变量的object 或 string型转换为定量变量的数值型。
Ø 函数:get_dummies()
Ø 举例:‘fuel’ 有gas和dissel两类,通过pd.get_dummies(df[‘fuel’])将gas 和dissel 重新赋值0或1,将分类变量‘fuel’转换为数值型,结果见下图
笔者总结出(三)数据处理版块的逻辑框架图,见下图。

四 建模
本文涉及线性回归和多项式回归算法,其他众多算法比如神经网络、随机森林、支持向量机、时间序列等,不在此介绍。

五 模型评估
评判模型准确度时经常用到的两个指标, R方检验(R²)和均方误差检(MSE)。
Ø R²的值越接近于1,拟合效果越好,R²的值越接近于0,拟合效果越差
Ø MSE能反应出真实值与预计值间的误差,MSE越小,模型准确性越高
六 模型调优
模型调参能够优化模型的准确性,调参指调整参数,那如何找到最佳的参数组合呢? 有如下如下方法:
Ø 岭回归, 函数: Ridge(alpha),解决过拟合现象
Ø 网格搜索:用穷举法遍历所有不同的参数组合,筛选出模型效果最好的一组参数组合。函数: GridSearchCV(Ridge(), parameters, cv), cv指交叉验证次数。
结尾
至此,笔者已介绍如何导数到Python、如何探索和处理数据、如何建模、如何评估模型、如何调参。完整的逻辑框架会让读者对‘Python数据分析’有一个全面的认识,快速达到俯瞰全局的高度。最后笔者搭建出完整的逻辑框架图送给读者,希望对你们有帮助。