本文整理自知乎专栏深度炼丹,转载请征求原作者同意。
本文的全部代码都在原作者GitHub仓库github
CS20SI是Stanford大学开设的基于Tensorflow的深度学习研究课程。
什么是TensorFlow
- 使用数据流图来做数值计算的开源软件
- Google Brain团队开发
TensorFlow的优势
- Python API
- 能够使用多个CPU和GPU。很容易部署到服务器上和移动端
- 足够灵活、非常底层
- tensorboard可视化做的好
- Checkpoints作为实验管理,随时保存模型
- 庞大的社区
几个重要的概念
tensor
- 0-d tensor: 标量
- 1-d tensor: 向量
- 2-d tensor: 矩阵
数据流图
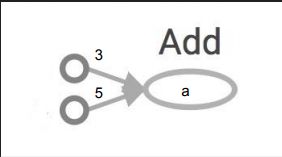
import tensorflow as tf
a = tf.add(3,5)
print(a)
>> Tensor("Add: 0", shape=(), dtype=int32)
要得到8,需要开启session,在session中操作能够被执行,Tensor能够被计算。这与一般的推断式编程(如PyTorch)不同。
import tensorflow as tf
a = tf.add(3,5)
with tf.Session() as sess:
print(sess.run(a))
>> 8
在Session().run调用的时候可以用[]来得到多个结果:
import tensorflow as tf
x = 2
y = 3
add_op = tf.add(x, y)
mul_op = tf.multiply(x, y)
useless = tf.multiply(x, add_op)
pow_op = tf.pow(add_op, mul_op)
with tf.Session() as sess:
z, not_useless = sess.run([pow_op, useless])
也可以将计算图的一部分放在特定的GPU或者CPU下
with tf.device('/gpu:2'):
a = tf.constant([[1.0,2.0,3.0],[4.0,5.0,6.0], name='a'])
b = tf.constant([[1.0,2.0],[3.0,4.0],[5.0,6.0]], name='b')
c = tf.matmul(a,b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print(sess.run(c))
尽量不要使用多个计算图,因为每个计算图需要一个
session,而每个session会使用所有的显卡资源,必须要用python/numpy才能在两个图之间传递数据,最好在一个图中建立两个不联通的子图
为什么使用Graph
-
节约计算资源,每次运算仅仅只需运行与结果相关的子图
-
可以将图分成小块进行自动微分
-
方便部署在多个设备上