接上篇:https://www.cnblogs.com/Hleaves/p/11284316.html
环境:jdk1.8 + springboot 2.1.1.RELEASE + feign-hystrix 10.1.0,以下仅为个人理解,如果异议,欢迎指正。
上篇中,设置tomcat的max-connection=1
因为之前一直理解的这个参数是同一时刻可以处理的http请求的数量,比如说我用浏览器‘同时’发起2个http请求(可以通过debug在controller层断点之后再发起另一个请求)A、B,此时A请求只要响应之后(忽略tcp连接是否释放),B请求正常来说就可以立即被服务端处理,事实并不是这样的,B请求一直在等待连接,但是再次发起一个请求C,C请求可以立即被处理,B请求还是一直在等待,只能串行执行,这个到底是为什么呢?后来查了一些资料,说是http1.1的请求头中默认加了Connection:keep-alive

就是这个,使得在一个请求完成之后,不会马上释放tcp连接,发起其他请求(同一个url)时,会复用这个tcp连接(tcp的长连接),而且浏览器对同一个域名的tcp长连接最大数量有限制(具体自行查资料吧,参考:https://www.jianshu.com/p/1d535bd7fefb),所以建议不同服务使用多个域名部署,那tcp复用到底是怎么实现的呢?浏览器没有办法直观的看到如何去选择空闲的长连接的,feign的调用默认使用的也是http1.1,我们可以参考这个调用过程去探寻一下tcp连接和释放,整个生命周期是怎样的,feign使用的默认的Client.Default,请求方式HttpURLConnection,不是ApacheHttpClient,也不是OkHttpClient
-------------------下面是使用feign实验的结果,均为debug出的结果,可能中间有些理解的不到位的地方--------------------
先说一下大致流程,从feign.Client.Default#execute开始,
public Response execute(Request request, Options options) throws IOException { HttpURLConnection connection = this.convertAndSend(request, options); return this.convertResponse(connection, request); }
1. this.convertAndSend(request, options);准备connection的基本信息,比如连接超时时间,读取超时时间等等,此时并没有建立tcp连接
2.this.convertResponse(connection, request);
2.1 先调用HttpClient.New(..)获取一个可用的httpClient,这是一个静态方法,这个方法中会先去KeepAliveCache中查找是否有可用的httpClient,如果有的话直接拿过来用
2.2 没有的情况下,调用HttpClient的构造,新建一个httpClient对象,这个构造方法的最后一行调用了openServer()方法,这个时候才会去真正的建立tcp连接
2.3 有了连接,这个时候可以向server端写数据了,这个时候会调用HttpURLConnection的writeRequests,此方法会判断httpClient.isKeepAlive的,默认是true,所以在请求头中加上了Connection:keep-alive
2.4 写数据完成之后,会调用HttpClient.parseHTTP(..)方法,去解析服务端响应的数据,包括响应头,此时如果响应头中包含了Connection:keep-alive,并且还设置了Keep-Alive:timeout=xx,max=xxx(client端的‘空闲’超时时间,默认5s,最多处理多少个请求,默认5个),会将这个值覆盖掉刚才的httpClient对象的keepAliveTimeout和keepAliveConnections属性
2.5 读取完数据之后,最终会调用到httpClient.finished方法,划重点 ,这个地方是实现tcp连接复用的关键
protected static KeepAliveCache kac = new KeepAliveCache();
private static boolean keepAliveProp = true;
......
public void finished() { if (!this.reuse) { --this.keepAliveConnections; this.poster = null; if (this.keepAliveConnections > 0 && this.isKeepingAlive() && !this.serverOutput.checkError()) { this.putInKeepAliveCache(); } else { this.closeServer(); } } } protected synchronized void putInKeepAliveCache() { if (this.inCache) { assert false : "Duplicate put to keep alive cache"; } else { this.inCache = true; kac.put(this.url, (Object)null, this); } }
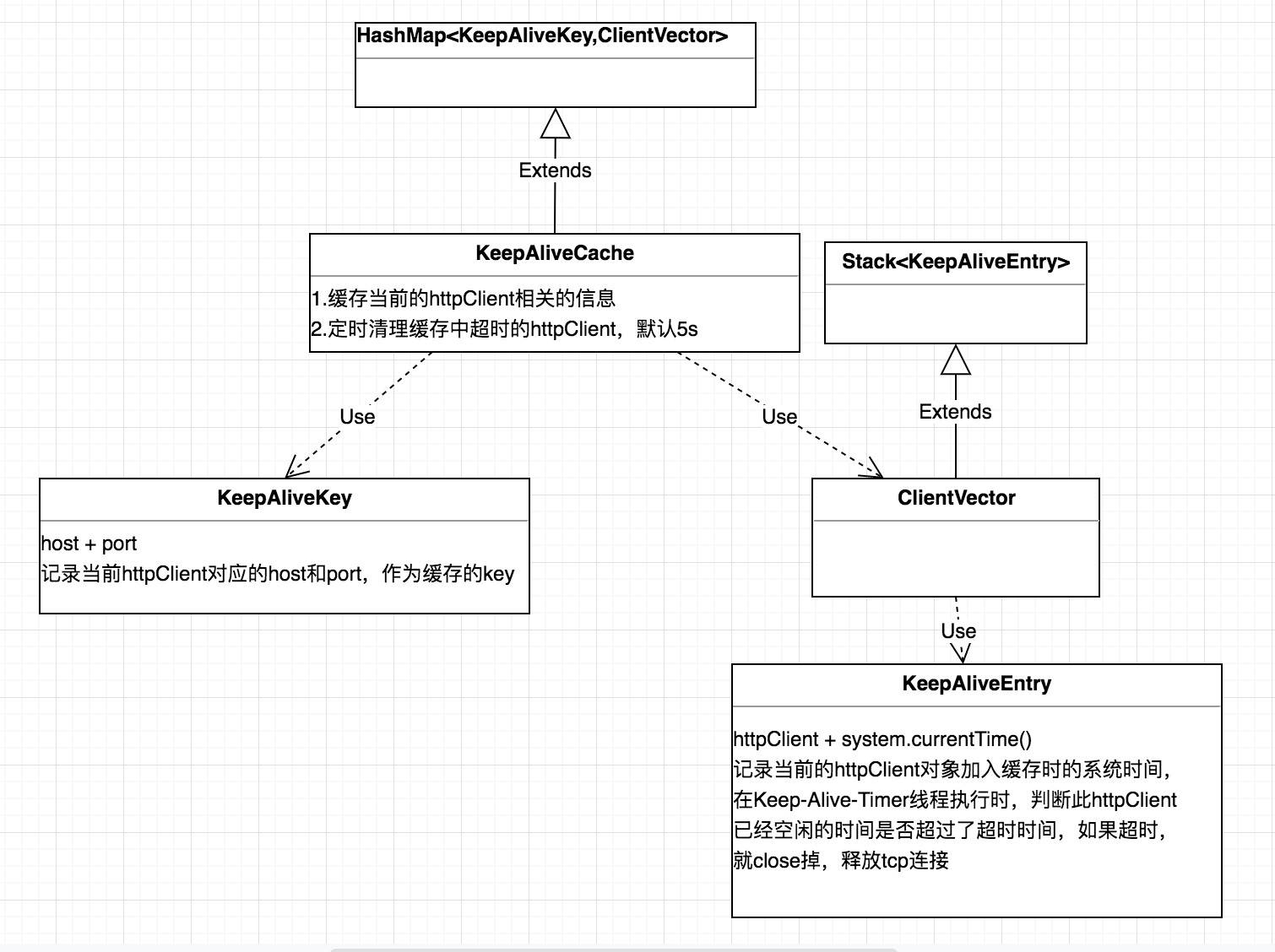
如果条件不成立,则直接close掉当前连接,就不会出现复用的情况了;反之会将当前对象存到KeepAliveCache中,KeepAliveCache继承了HashMap,本质上就是一个map,这里的key是host+port,跟前面说的浏览器是根据域名划分的好像是一致的(这个没有做深入的了解),我们看下KeepAliveCache的put操作都做了什么
public synchronized void put(URL var1, Object var2, HttpClient var3) {
boolean var4 = this.keepAliveTimer == null;
if (!var4 && !this.keepAliveTimer.isAlive()) {
var4 = true;
}
if (var4) {
this.clear();
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ThreadGroup var1 = Thread.currentThread().getThreadGroup();
for(ThreadGroup var2 = null; (var2 = var1.getParent()) != null; var1 = var2) {
}
KeepAliveCache.this.keepAliveTimer = new Thread(var1, KeepAliveCache.this, "Keep-Alive-Timer");
KeepAliveCache.this.keepAliveTimer.setDaemon(true);
KeepAliveCache.this.keepAliveTimer.setPriority(8);
KeepAliveCache.this.keepAliveTimer.setContextClassLoader((ClassLoader)null);
KeepAliveCache.this.keepAliveTimer.start();
return null;
}
});
}
KeepAliveKey var5 = new KeepAliveKey(var1, var2);
ClientVector var6 = (ClientVector)super.get(var5);
if (var6 == null) {
int var7 = var3.getKeepAliveTimeout();
var6 = new ClientVector(var7 > 0 ? var7 * 1000 : 5000);
var6.put(var3);
super.put(var5, var6);
} else {
var6.put(var3);
}
}
这几个类的关系和功能如下图所示,到此为止,为什么会复用,以及什么条件下可以复用基本上都明了了
------------延伸问题--------------------
feign中默认使用的jdk1.8中的HttpClient,每个请求都会有一个httpClient,一个httpClient都持有一个tcp长连接,所以tcp长连接的复用,其实就是httpClient的复用
1.首先是为什么feign调用会默认在请求头中加上Connection:keep-alive?
sun.net.www.http.HttpClient
static { String var0 = (String)AccessController.doPrivileged(new GetPropertyAction("http.keepAlive")); String var1 = (String)AccessController.doPrivileged(new GetPropertyAction("sun.net.http.retryPost")); String var2 = (String)AccessController.doPrivileged(new GetPropertyAction("jdk.ntlm.cache")); String var3 = (String)AccessController.doPrivileged(new GetPropertyAction("jdk.spnego.cache")); if (var0 != null) { keepAliveProp = Boolean.valueOf(var0); } else { keepAliveProp = true; } if (var1 != null) { retryPostProp = Boolean.valueOf(var1); } else { retryPostProp = true; } ....... }
可以看到这是取得一个系统配置http.keepAlive,如果没有增加或修改这个配置,默认就是keepAliveProp=true的,这个就是2.3中用来判断的其中一个条件
2.tcp连接复用的话,到底是谁先close的,server还是client端?
再上一篇中分析了springboot server 有一个connection-timeout的配置,默认是60s,就是client端请求完成之后,如果server端正常响应200,server端的org.apache.tomcat.util.net.NioEndpoint.Poller#timeout会判断当前的socket是否已超时,判断的依据是 (当前系统时间-最后一次读写的时间>connection-timeout时间),如果超时,就会close掉当前的socket,但是,在未达到超时时间时,通过命令行查看tcp的状态,发现服务端的端口状态是CLOSE_WAIT的,也就是说client已经主动关闭了连接,到底是什么时候在哪里关闭的连接?
在流程的2.5中,在缓存httpClient时会在KeepAliveEntry中记录一下当前的系统时间,标记为idleStartTime,顾名思义,就是你开始闲着的时间,哈哈,2.5中的Keep-Alive-Timer线程的run方法会去判断此httpClient是不是已经闲够了,闲够了就把它close掉,这个时间默认是5s,可以通过流程2.4,在response中修改这个值,不管是不是用的缓存的httpClient,每次请求完成都会调用2.5的finished方法,所以这个idleStartTime每次都会更新的。所以现在client端的‘超时’时间是5s,server端的超时时间是60s,所以就会出现client端先close掉,然后server端一直等到60s才去close的情况,所以server端的这个60s是不是有点多余了。。。。。。
ps: server端会判断即将响应的结果,如果是异常的,比如是以下的状态码,则会将scoket的状态标记为error,此时即使client设置了keepAlive,server也会自动close掉当前连接
return status == 400 /* SC_BAD_REQUEST */ ||
status == 408 /* SC_REQUEST_TIMEOUT */ ||
status == 411 /* SC_LENGTH_REQUIRED */ ||
status == 413 /* SC_REQUEST_ENTITY_TOO_LARGE */ ||
status == 414 /* SC_REQUEST_URI_TOO_LONG */ ||
status == 500 /* SC_INTERNAL_SERVER_ERROR */ ||
status == 503 /* SC_SERVICE_UNAVAILABLE */ ||
status == 501 /* SC_NOT_IMPLEMENTED */;
3. tcp连接复用的之http1.1和http2.0
参考:https://blog.csdn.net/CrankZ/article/details/81239654
http1.1的复用,是串行的,一个tcp连接,只能等一个请求完成才可以给另一个请求使用
http2.0的复用,可以并行处理,增加了HttpStream,一个tcp连接中可以同时处理多个HttpStream(同步代码块实现的),但是只支持https,server端和client端都要做改动,只是目前了解到的一丢丢而已,后续再做补充