当训练集特别大的时候(数万条起步),每一轮训练仅仅希望从中随机取出一部分数据(比如batch_size=64)计算模型损失值、执行梯度下降,这就是SGD随机梯度下降。
下面是一个demo,其实训练集一共只有四条数据。
看代码1:
#encoding=utf-8
import torch
import torch.nn as nn
import torch.utils.data as Data
dataX = torch.LongTensor([
[1, 2, 3, 4, 0],
[9, 0, 1, 2, 3],
[0, 4, 2, 3, 6],
[7, 8, 9, 7, 0]])
dataY = torch.arange(8).view(4,2)
class Database(Data.Dataset):
def __init__(self, feature, label):
super(Database, self).__init__()
self.feature = feature # [N, src_len] int64
self.label = label # [N, tgt_len] int64
self.dataset_train = Data.TensorDataset(self.feature, self.label)
# 下面两段代码是Data.Dataloader的关键,不可删除
def __len__(self):
return self.feature.shape[0]
def __getitem__(self, index):
return self.dataset_train[index]
db = Database(dataX, dataY)
loader = Data.DataLoader(db, batch_size = 2, shuffle = False)
for epoch in range(4):
print("----> Epoch [%d] <----" % epoch)
for X,Y in loader:
print("X:
", X)
print("Y:
", Y)
代码主程序模拟了训练多轮的过程,每轮都会把loader中的数据全跑遍以后退出。
值得说明的是,源数据dataX、dataY的行数(dim = 0)必须一致,表示多少条数据,其次列数不一定相等。
执行效果

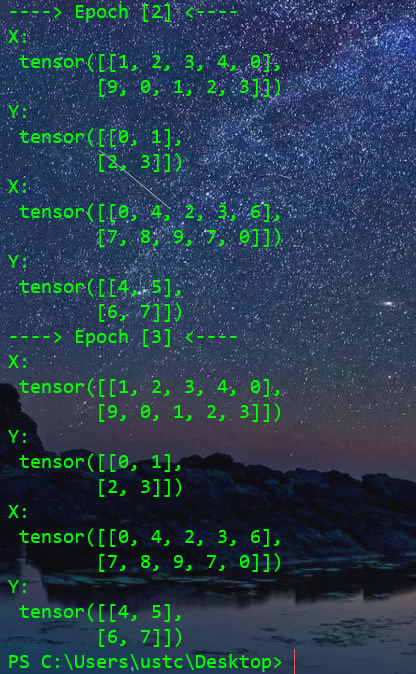
shuffle 设为 True效果

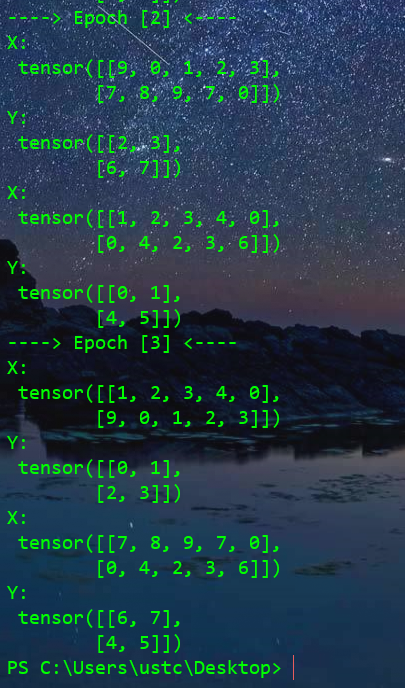
可以发现此时每一轮次生成的训练数据是打乱顺序的,但是feature和label的对应序号是一致的。
也就是说两者是同步变序的。
主程序的再一种变种
上述程序中虽然设置了batch_size,但是每个完整的Epoch都会跑完训练集的所有数据(loader数据走一遍),数据集合很大的时候每轮的训练时间就很长,期望每个Epoch仅仅训练batch_size个数据,这样epoch执行速度看起来更快。
总样本数目设为N = 10000,batch_size = 200,这样运行 total_epoches = N/batch_size = 50轮次就能把数据集合完整执行一遍。
可在实际中,我们希望把这个训练集遍历多次(执行很多个50次)以得到更小的损失值、更好的拟合效果。可是从代码1看到,此种形式的代码结构在跑完loader后就结束了,到末尾了。
看代码2:
loader = Data.DataLoader(db, batch_size = 2, shuffle = False)
for epoch in range(4):
print("----> Epoch [%d] <----" % epoch)
for X,Y in loader:
break
print("X:
", X)
print("Y:
", Y)
执行效果:

可以看到效果糟透了,每次都只取得数据及前batch_size=2个数据,无法实现遍历训练集,修改shuffle 设为 True效果:

现在效果好多了,采用乱序会随机打乱数据集合的样本顺序只返回乱序后前面batch_size个数据。