1 web应用,http协议,web框架
# ip+端口号唯一确定一个应用
# web框架是什么 C/S B/S
三次握手,四次挥手
# http协议
无状态,基于请求和相应,是在TCP/IP协议之上的应用层的协议,短链接
响应状态码
1xx 请求等待处理
2xx 请求成功
3xx 重定向跳转
4xx 资源不存在/请求有误
5xx 服务器错误
# wsgi协议,wsgiref,uWSGI分别是什么?
wsgi协议是py中的一个协议:规定了如何拆,封http协议
#模板文件是在什么时候完成渲染的?(*****)
在后端进行渲染,对于所需要调用的值都提供好对应的字符串数据后,进行返回,当离开了django框架后就是完整的html,css和js,不再是模板
2 django请求生命周期
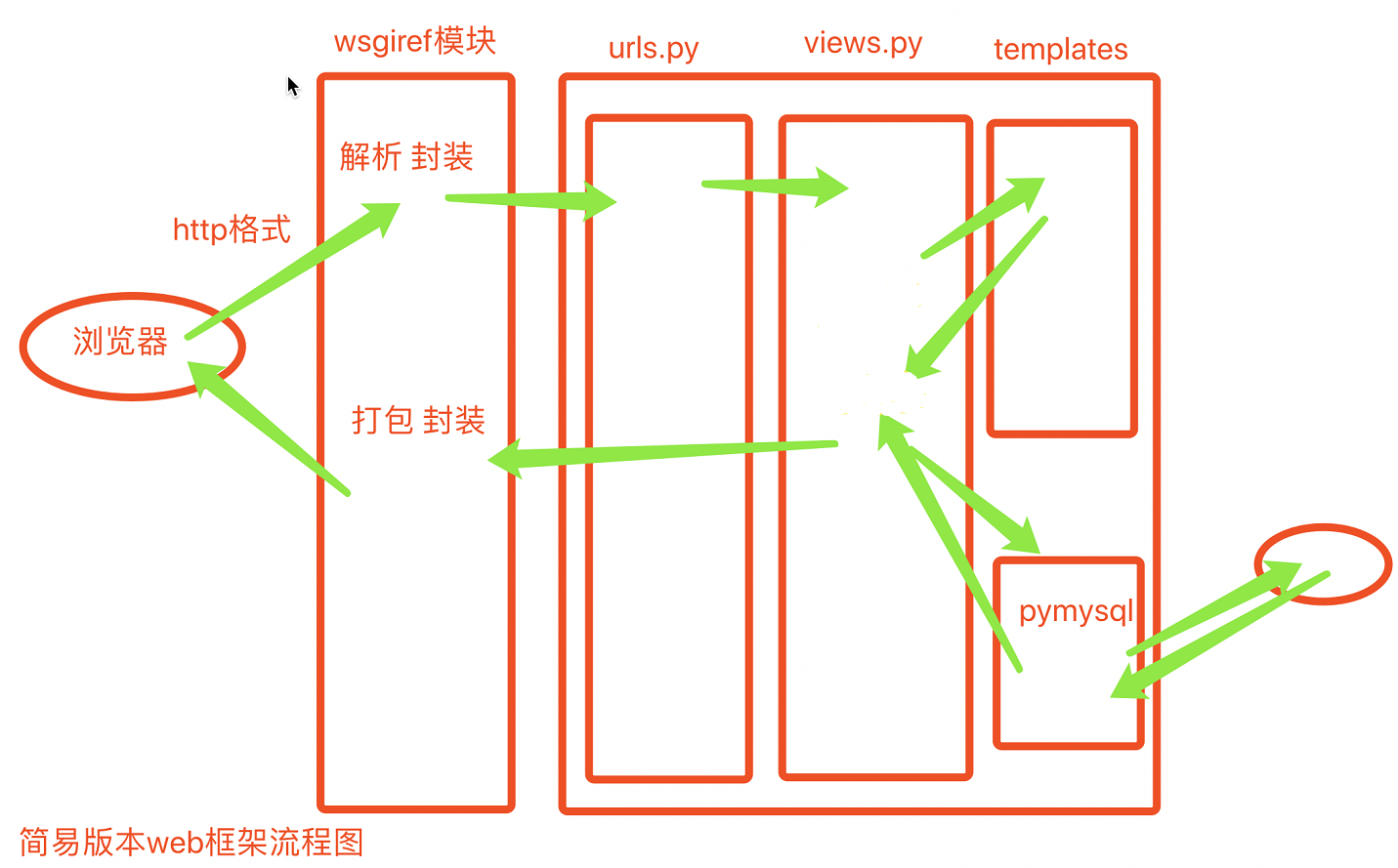
wsgiref效率相对较低之后的项目可以用uwsgi进行替换,提高程序的并发量
3 路由控制
# django是一个同步框架
如果使用了异步,则后续所有的模块都要使用异步的才可以
# 最新版本3.x
# URL与要为该URL调用的视图函数之间的映射表
# 1.x 和2.x版本路由稍微不同
1.x:url
2.x:path,re_path(原来的url)
# 写法
from django.conf.urls import url
urlpatterns = [
url(正则表达式, views视图函数,参数,别名),
]
正则表达式:一个正则表达式字符串
views视图函数:一个可调用对象,通常为一个视图函数或一个指定视图函数路径的字符串
参数:可选的要传递给视图函数的默认参数(字典形式)
别名:一个可选的name参数
# APPEND_SLASH 的用法
配置文件中的APPEND_SLASH默认是开启的,无需添加
作用: 是否开启URL访问地址后面不为/跳转至带有/的路径的配置项
即:
http://www.example.com/blog 和
http://www.example/com/blog/ 的区别
#
# 有名分组
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
# 无名分组
re_path(r'^articles/([0-9]{4})/$', views.year_archive),
# 路由分发
需要现在app中创建urls.py,之后在总路由进行路由分发
path('app01/', include(urls)),
#反向解析
###视图函数中
from django.shortcuts import reverse
url=reverse('test',args=(10,20)) # test是在url内配置的别名
###在模板中使用
{% url "test" 10 20%}
# 名称空间(了解)
url(r'app01/',include('app01.urls',namespace='app01')),
url(r'app02/',include('app02.urls',namespace='app02'))
url(r'app01/',include(('app01.urls','app01'))),
url(r'app02/',include(('app02.urls','app02')))
url=reverse('app02:index')
print(url)
url2=reverse('app01:index')
print(url2)
# path中内置了几个转换器
str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int,匹配正整数,包含0。
slug,匹配字母、数字以及横杠、下划线组成的字符串。
uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
使用方式:
path('order/<int:year>',views.order),
# path自定义转换器(了解)
4 视图层
#response对象: 三件套+JsonResponse 本质都是HttpResonse
#request对象:
request.GET:http://127.0.0.1:8000/index/123?name=lqz&age=18 name=lqz&age=18会被转成字典,放到GET中
request.POST:urlencoded,formdata两种编码的数据会被放在这个字典中
request.META:HTTP请求的其他东西,放在里面,入客户端ip地址:REMOTE_ADDR 请求的正文的MIME 类型 CONTENT_TYPE
request.FILES:上传的文件
request.session:用的session
request.user(使用auth):存的是登录用户的对象,未登录则存AnonymousUser的实例
#常用方法:
get_full_path() 获取完整的路由地址
is_ajax() 判断提交方式是否为ajax
# 301 和302的区别
1)301和302的区别。
他们都表示重定向,就是说浏览器在拿到服务器返回的这个状态码后会自动跳转到一个新的URL地址,
301表示旧地址的资源已经被永久地移除了(这个资源不可访问了),搜索引擎在抓取新内容的同时也将旧的网址交换为重定向之后的网址;
302表示旧地址A的资源还在(仍然可以访问),这个重定向只是临时跳转,搜索引擎会抓取新的内容而保存旧的网址。
2)重定向原因:
(1)网站调整(如改变网页目录结构);
(2)网页被移到一个新地址;
(3)网页扩展名改变(如应用需要把.php改成.Html或.shtml)。
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个404页面错误信息,访问流量白白丧失;再者某些注册了多个域名的网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
# JsonResponse
返回前端json数据的两种方式
方式一:
import json
data = {'name':'hr'}
return HttpResponse(json.dumps(data))
方式二:
from django.http import JsonResponse
data = {'name':'hr'}
return JsonResponse
# CBV和FBV
#文件上传(form表单中指定编码方式)
def index(request):
if request.method=='GET':
return render(request,'index.html')
else:
myfile=request.FILES.get('myfile') #文件对象
print(type(myfile))
# django.core.files.uploadedfile.InMemoryUploadedFile
name=myfile.name
print(myfile.field_name)
with open(name,'wb') as f:
for line in myfile:
f.write(line)
return HttpResponse('文件上传成功')
5 模板层
模版语法重点:
变量:{{ 变量名 }}
1 深度查询 用句点符
2 过滤器
标签:{{% % }}
内置过滤器:
{{obj|filter__name:param}} 变量名字|过滤器名称:变量
重点:safe
#xss攻击
<a href="https://www.baidu.com">点我<a> 如果原封不动的显示在html中,一定是a标签
所以为了方式xss攻击,对于展示到前端的内容用html的特殊字符进行替换 ,例如 碰到<a href="https://www.baidu.com">点我<a>需要展示,则前端替换为 <a href="https://www.baidu.com">点我<a> 展示出来的效果不会以标签的形式存在
for标签
{% for x in y%}
{% endfor %}
if标签
{% if x%}
{% elif y%}
{% else %}
{% endif %}
with标签
{% with x.y.z as c%}
{% endwith %}
{% with c = x.y.z%}
{% endwith %}
# {% csrf_token%}
{% csrf_token%}是一个隐藏的标签,value是值,name是csrfmiddlewaretoken
<input type="hidden"value="sadfasdfasdf" name="csrfmiddlewaretoken">
{{ csrf_token }} 是值,赋值的时候需要手动加引号
# 模板的导入和继承
include
extend:先用{% block title %},
再用{% extends "base.html" %}
{% block content %}
自己的内容
{% endblock %}
6 模型层
# 使用orm的步骤
1 在setting中配置(连数据库的地址,端口)
2 在 __init__中使用pymysql
import pymysql
pymysql.install_as_MySQLdb()
3 在models.py中写类,写属性
4 使用:数据库迁移的两条命令
python3 manage.py makemigrations #记录
python3 manage.py migrate # 真正的数据库同步
5 在视图函数中使用orm
# orm的api
<1> all(): 查询所有结果
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
<5> order_by(*field):对查询结果排序('-id')
<6> reverse(): 对查询结果反向排序
<7> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
<8> first(): 返回第一条记录
<9> last(): 返回最后一条记录
<10> exists(): 如果QuerySet包含数据,就返回True,否则返回False
<11> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列(列表套字典)
<12> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列(列表套元组)
<13> distinct(): 从返回结果中剔除重复纪录
# 下划线查询
Book.objects.filter(price__in=[100,200,300])
Book.objects.filter(price__gt=100)
Book.objects.filter(price__lt=100)
Book.objects.filter(price__gte=100)
Book.objects.filter(price__lte=100)
Book.objects.filter(price__range=[100,200])
Book.objects.filter(title__contains="python")
Book.objects.filter(title__icontains="python")
Book.objects.filter(title__startswith="py")
Book.objects.filter(pub_date__year=2012)
#删除
对象.delete() #删一条
queryset对象.delete() # 删多条
#更新
Book.objects.filter(title__startswith="py").update(price=120)