1、垃圾回收机制
1.1、什么是垃圾回收机制
垃圾回收机制(简称GC)是Python解释器自带一种机,专门用来回收不可用的变量值所占用的内存空间
1.2、为什么要用垃圾回收机制
程序运行过程中会申请大量的内存空间,而对于一些无用的内存空间如果不及时清理的话会导致内存使用殆尽(内存溢出),导致程序崩溃,因此管理内存是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制把程序员从繁杂的内存管理中解放出来。
1.3、栈区与堆区
- 在定义变量时,变量名与变量值都是需要存储的,分别对应内存中的两块区域:堆区与栈区。
- 简单描述一个变量x=10,在内存中的栈区与堆区的存放情况
- 栈区:存放的是变量名与内存地址的对应关系,所以可以简单理解为:变量名存内存地址
- 堆区:存放的是变量值
- 强调:只站在变量名的角度去谈一件事情
变量名的赋值(x=y),还有变量名的传参(print(x)),传递的都是栈区的数据,而且栈的数据是变量名与内存地址的对应关系,或者说是对值得引用
案例1:
x,y = 10,20
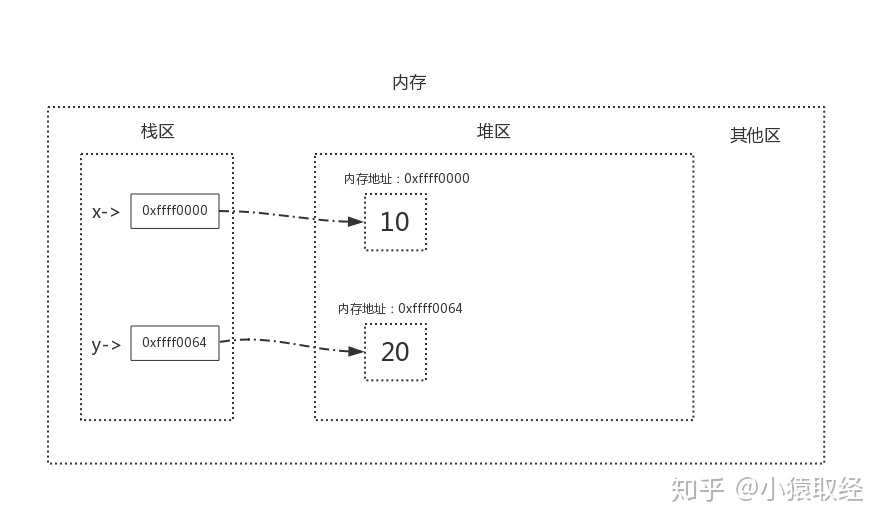
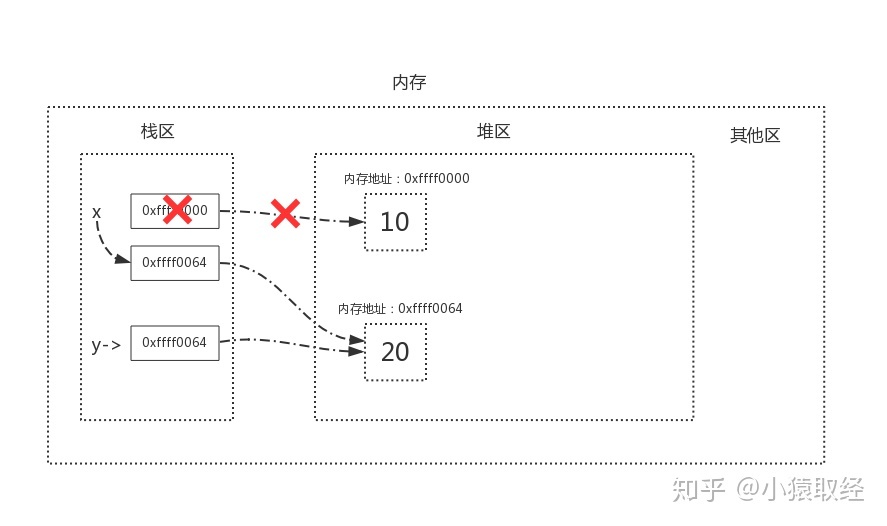
当我们执行x=y时,内存中的栈区与堆区变化如下
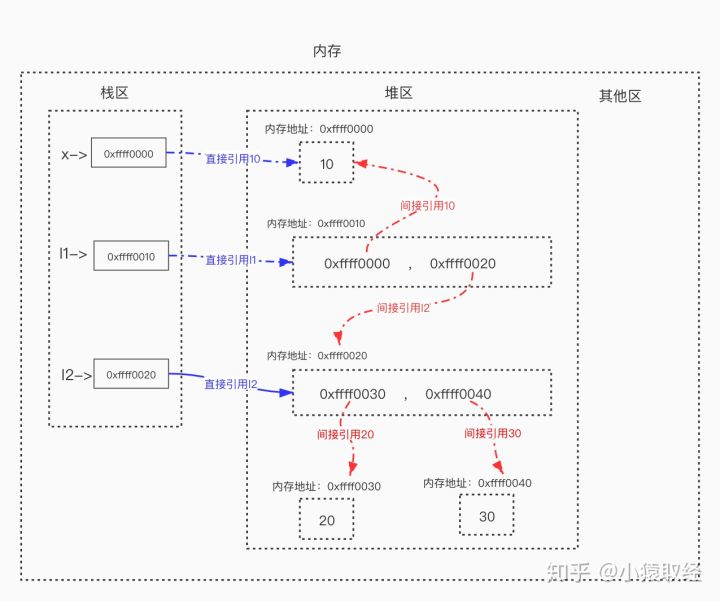
1.4、直接引用与间接引用
- 直接引用:从栈区出发直接引用到的内存地址。
- 间接引用:从栈区出发引用到堆区后,再通过进一步引用才能到达的内存地址。
l2 = [20, 30] # 列表本身被变量名l2直接引用,包含的元素被列表间接引用
x = 10 # 值10被变量名x直接引用
l1 = [x, l2] # 列表本身被变量名l1直接引用,包含的元素被列表间接引用
1.5、垃圾回收机制原理分析
-
垃圾回收机制主要运用了引用计数来跟踪和回收垃圾。
-
在引用技术的基础上,还可以通过标记-清除解决容器对象可能产生的循环引用的问题。
-
并且通过分代回收以空间换取时间的方式来进一步提高垃圾回收的效率。
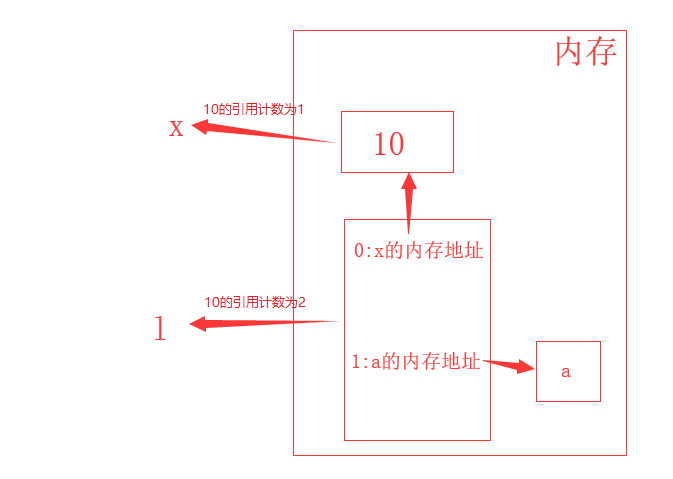
什么是引用计数?
- 用来清除直接引用垃圾
#直接引用
x = 10 # 10的引用计数为1
y = x # 10的引用计数为2
z = y # 10的引用计数为3
print(id(x))
print(id(y))
print(id(z))
# 间接引用
x = 10 # 10的引用计数为1
# 列表中存的是值的内存地址
l = [x, 'a'] # 10的引用计数为2
print(id(l[0]))
引用计数扩展阅读
-
标记-清除
- 用来清理循环引用情况下引用计数无法清除的垃圾
# 循环引用
l1 = [111, ]
l2 = [222, ]
l1.append(l2) # l1=[值111的内存地址, l2列表的内存地址]
l2.append(l1) # l1=[值222的内存地址, l1列表的内存地址]
print(id(li[1]))
print(id(l2))
print(id(l2[1]))
print(id(l1))
print(l2)
print(l1[1])
del l1 # 列表1的引用计数减1,列表1的引用计数变为1
del l2 # 列表2的引用计数减1,列表2的引用计数变为1
分代回收
- 降低了引用计数回收内存时的扫描频率,提高了回收效率,分代回收采用的是用“空间换时间”的策略。
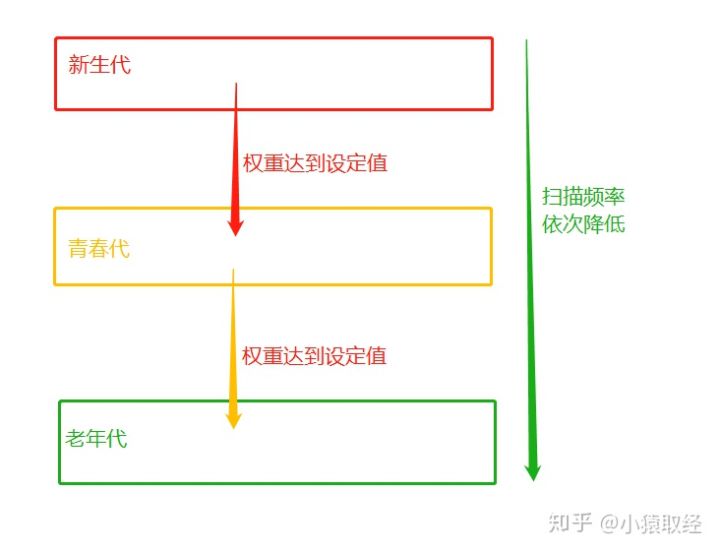
-
虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
''' 例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了, 该变量应该被回收,但青春代的扫描频率低于新生代,所以该变量的回收就会被延迟。 ''' ''' 没有十全十美的方案: 毫无疑问,如果没有分代回收,即引用计数机制一直不停地对所有变量进行全体扫描, 可以更及时地清理掉垃圾占用的内存,但这种一直不停地对所有变量进行全体扫描的方式效率极低, 所以我们只能将二者中和。 综上 垃圾回收机制是在清理垃圾&释放内存的大背景下, 允许分代回收以极小部分垃圾不会被及时释放为代价, 以此换取引用计数整体扫描频率的降低,从而提升其性能, 这是一种以空间换时间的解决方案目录 '''
2、程序与用户交互
2.1、什么是与用户交互?
- 用户交互就是人往计算机中input/输入数据,计算机print/输出结果
2.2、为什么要与用户交互?
- 为了让计算机能够与用户沟通交流
2.3、如何与用户交互?
交互的本质就是输入输出
- 输入(input)和输出(print)
# 在python3:input会将用户输入的所有内容都存成字符串类型
>>> age = input('age:')
age:18
>>> print(age,type(age))
18 <class 'str'>
>>>
>>> print(int(age),type(int(age)))
18 <class 'int'>
>>>
# 在python2:raw_input(),用法与python3的input一摸一样
```
# input():要求用户必须输入明确的数据类型,输入的什么类型就存成什么类型
```
> > > age = input('age:')
> > > age:18
> > > print(age,type(age))
> > > (18, <type 'int'>)
2.4、字符串的格式化输出
-
2.4.1、 什么是格式化输出
- 把一段字符串中的某些内容用自己定义的内容替换掉之后再输出
-
2.4.2、为什么要格式化输出
- 由于经常用到要输出固定格式的内容,普通的输出已经无法满足需求所以需要格式化输出
-
2.4.3、如何格式化输出
- 运用占位符来实现格式化输出,如:%、str.format、f''
# %s 可以接收任意类型的值
# %d 只能接收int
print("Life is short, I play %s,%d", %('python', 114514))
# 以字典的形式传值,打破位置的限制
res = "我的名字是 %(name)s 我的年龄是 %(age)s" % {"age": 18, "name": 'Umi'}
print(res)
# str.format python2.6后引入的(兼容性好,推荐使用)
# 按照位置取值
res = "我的名字是 {0} 我的年龄是 {1}".format('Umi', 18)
print(res)
# 按照key=value传值
name = input('your name:')
age = input('your age:')
res = "我的名字是 {name} 我的年龄是 {age}".format(age=age, name=name)
print(res)
# f'' python3.5后推出
name = input('your name:')
age = input('your age:')
res = f"我的名字是 {name} 我的年龄是 {age}"
print(res)
2.4.5、字符串的格式化输出补充知识
# f的新用法(了解):{}内的字符串可以被当作表达式运行
res=f'{10+3}'
print(res)
f'{print("aaa")}'
# format新增(了解)
# 我的名字是 {Umi} 我的年龄是 18
print("我的名字是 {{{name}}} 我的年龄是 {age}".format(age=18, name='Umi'))
# 先取到值,然后在冒号后设定填充格式:[填充字符][对齐方式][宽度]
# *<10:左对齐,总共10个字符,不够的用*号填充
print('{0:*<10}'.format('开始执行')) # 开始执行******
# *>10:右对齐,总共10个字符,不够的用*号填充
print('{0:*>10}'.format('开始执行')) # ******开始执行
# *^10:居中显示,总共10个字符,不够的用*号填充
print('{0:*^10}'.format('开始执行')) # ***开始执行***
# 保留小数后几位
print('{salary:.3f}'.format(salary=12321.123456)) # 12321.123