训练技巧
1.首先用小批量数据,查看是否代码有问题,理论上模型应该能将损失降到0左右,准确率为1.
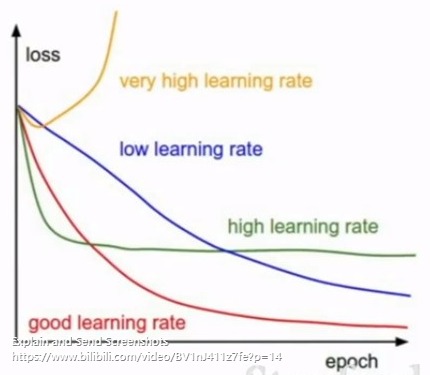
2.使用较小的学习率比如1e-6,观察损失值的变化,如果损失不怎么动就是学习率太小了,增大学习率。

一般对于损失的计算来说:像位置坐标这种是连续值变化的东西,倾向于回归损失如L1 或L2损失
其他的比如score得分:会用交叉熵损失或softmax等
卷积过程的可视化:(目的,理解神经网络每一层在干什么)
可视化的是每层的卷积核(卷积核类似模板匹配的模板,只有与卷积核类似的形态才会得到最大的激活)
可以理解成卷积核到底在找什么样的东西。
可视化1
比如minit数据集经过alex-net的全连接层输出的4096维特征进行降维(PCA/t-SNE)嵌入,得到二维特征表示(x,y),降维后你会发现,相同的类别的点离的很近,本质上就是做了个分类过程。

可视化2:
选择某个layer及通道,运行图片前馈,记录下特征图的值,针对特征图上被激活的区域,可视化所有在这个channel被激活的位置对应的原始图像图块

可视化3:
遮挡排除法
每次遮挡(mask)一个位置之后将图像馈入分类器,得到正确分类的概率,那么当我们在整张图像上所有位置都滑动一次mask遮挡然后分类后,就可以得到一张关于每个mask位置的概率的热图。
反映了到底哪个部位的特征对于分类是至关重要的。

可视化4:(原理同3)
显著图
计算类别得分对于图像中每个像素的梯度:即如果梯度小,则此像素点对于最终的分类得分影响不明显。梯度越大,说明对此像素点加入扰动会显著影响最终的分类效果。

一个很有意思的现象:(我们原以为要愚弄分类器,需要做给大象加个考拉熊的耳朵这种类似的操作,但是事实不是这样)
当我们将一个为大象类别的图像,计算最大化类别得分为考拉熊时 得分对于像素的梯度,发现明显变量的区域并不是考拉熊的样子,而是很大一片随机噪点,为什么呢???
结果:只要对原始图片的一些像素点做扰动就可以使最终的分类非常confirmly的发生错误!

*Deepdream项目
特征反演(feature inversion):
发现底层特征图是几乎可以完全反演得到输入图像的,而高层的特征图反演后得到的图像的细节颜色等会丢失无法恢复,因为底层的特征还没有被高度抽象(丢失信息)

神经纹理合成(neural texture synthesis)与格莱姆矩阵

风格迁移
结合了纹理合成与特征反演
风格图像的分辨率会影响最终的生成的结果图的类型

还可以多张风格图同时对一张内容图进行风格迁移!

fast style transfer