目录
-
cat查看文档
-
more可分页查看文档
-
less相比较more功能更强大
-
head查看文档的前N行
-
tail查看文档的后N行或试试刷新查看
-
tr替换文本字符
-
wc统计文本行数
-
stat查看文档存储和时间信息
-
cut按列提取文本字符
-
diff比较多个文件差异
一、cat命令
cat命令用于查看纯文本文件(内容较少的)。由于cat命令查看文档时会将文档内容全部显示,当文档内容过多时,使用cat命令就会很不方便浏览了,这时可以使用less,more,head,tail命令。cat还可以查看多个文件,中间使用空格分隔即可。
cat的作用不局限于查看文档。
1)一次查看完整文档
2)从键盘创建文件(只能创建新文件,不能编辑已有的文件,编辑已有的文件会清空文件的内容)
3)将几个文件合并为一个文件
[root@VM_0_10_centos ~]# cat hello lo >> test.sh
[root@VM_0_10_centos ~]# cat test.sh
cjsnc;avnaovnj
hello
lolol
格式:
-A, --show-all 等价于 -vET
-b, --number-nonblank 显示行号,但不显示换行或空行的行号
-e 等价于 -vE
-E, --show-ends 在每一行的末尾加上$符号
-n, --number 显示所有行号包括换行和空行的行号
-s, --squeeze-blank 如果有两行及以上空白行,替换为一行
-t 等价于-vT
-T, --show-tabs 将有使用tab字符的位置换成^I
-u 忽略
-v, --show-nonprinting 使用 ^ and M- 注释, 除了 LFD and TAB
补充:
cat还可以和EOF连用,表示创建,连接文件。这里可以参考我的另一篇博客文章:https://www.cnblogs.com/HeiDi-BoKe/p/11692079.html
PS:需要注意的是输入输出符,">"表示创建,如果是已有的文件使用该输出符需要注意是否想清空这个文件的内容,如果不想清空,请使用">>"追加的方式。
二、more命令
more命令用于查看纯文本文件(针对内容较多的文档)。使用more命令查看文档底部会显示阅读的百分比,可以使用空格键或回车键向下翻页。
格式:
more [选项] 文件名
选项:
+NUM 从笫n行开始显示
-NUM 定义屏幕大小为n行
+/pattern 在每个档案显示前搜寻该字串(pattern),然后从该字串前两行之后开始显示
-c 从顶部清屏,然后显示
-d 提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-l 忽略Ctrl+l(换页)字符
-p 通过清除窗口而不是滚屏来对文件进行换页,与-c选项相似
-s 把连续多个空行显示为一行
-u 把文件内容中的下画线去掉
常用操作命令:
Enter 向下n行,需要定义。默认为1行
Ctrl+F 向下滚动一屏
空格键 向下滚动一屏
Ctrl+B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
V 调用vi编辑器
!命令 调用Shell,并执行命令
q 退出more
实例:
1)显示文件从第5行开始
[root@VM_0_10_centos ~]# more +5 /etc/passwd
2)定义屏幕大小为每5行为一屏
[root@VM_0_10_centos ~]# more -5 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
3)从文件中查看var字符串,并从该行前两行输出显示
[root@VM_0_10_centos ~]# more +/var /etc/passwd
...skipping
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
三、less命令
less命令比more命令功能更强大,能向前向后翻页(PgUp,PgDn键),more只能向后翻页。
格式:
less [参数] 文件名
参数:
-b <缓冲区大小> 设置缓冲区的大小
-e 当文件显示结束后,自动离开
-f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
-g 只标志最后搜索的关键词
-i 忽略搜索时的大小写
-m 显示类似more命令的百分比
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-Q 不使用警告音
-s 显示连续空行为一行
-S 行过长时间将超出部分舍弃
-x <数字> 将“tab”键显示为规定的数字空格
-V 进入vim模式,可以编辑当前文档
&pattern 匹配模式的行,而不是整个文件
常用操作:
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
b 向后翻一页
d 向后翻半页
j 向前移动
k 向后移动
G 移动到最后一行
g 移动到第一行
h 显示帮助界面
Q或q或ZZ 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页
ctrl + F 向前移动一屏
ctrl + B 向后移动一屏
ctrl + D 向前移动半屏
ctrl + U 向后移动半屏
实例:
1)浏览多个文件
[root@VM_0_10_centos ~]# less hello lo
PS:输入:n 切换到下一个文件lo;输入:p 切换到前面一个文件hello;输入:e 文件名 再打开一个文件
四、head命令
head命令用于查询文档的前N行,默认显示前10行。查询多个文件,在每一段输出前会给出文件名作为文件头。如果不指定文件,或者文件为"-",则从标准输入读取数据。
格式:
head [参数] 文件名
参数:
-c, --bytes=[-]K 显示每个文件的前K 字节内容;如果附加"-"参数,则除了每个文件的最后K字节数据外 显示剩余全部内容
-n, --lines=[-]K 显示每个文件的前K 行内容;如果附加"-"参数,则除了每个文件的最后K行外 显示剩余全部内容
-q, --quiet, --silent 不显示包含给定文件名的文件头
-v, --verbose 总是显示包含给定文件名的文件头
1)显示文件前3行
[root@VM_0_10_centos ~]# head -n 3 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
2)输出文件,显示除了最后33行的全部内容
[root@VM_0_10_centos ~]# head -n -33 /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
3)显示文件前5个字节
[root@VM_0_10_centos ~]# head -c 5 /etc/passwd
root:
4)显示除了最后3个字节以外的内容
[root@VM_0_10_centos ~]# head -c -3 hello
hel
五、tail命令
tail命令用于查看纯文本文档最后N行或持续刷新的内容。
格式:
tail [选项] [文件]
选项:
-f 循环读取,实时刷新
-q 不显示处理信息
-v 显示详细的处理信息
-c<数目> 显示的字节数
-n<行数> 显示文件的尾部 n 行内容
--pid=PID 与-f合用,表示在进程ID,PID死掉之后结束
-q, --quiet, --silent 从不输出给出文件名的首部
-s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
PS:和head命令使用一样
六、tr命令
tr(translate)命令用于替换或删除文档中的字符。tr主要用于删除文件中控制字符或进行字符转换。使用tr时要转换两个字符串:字符串1用于查询,字符串2用于处理各种转换。tr刚执行时,字符串1中的字符被映射到字符串2中的字符,然后转换操作开始。
格式:
tr [选项] [原始字符] [目标字符]
或
Usage: tr [OPTION]... SET1 [SET2]
选项:
-c, -C, –complement 用SET1的字符串替换,要求字符集为ASCII。
-d, –delete 删除SET1中的字符而不是转换
-s, –squeeze-repeats 删除所有重复出现字符序列,只保留第一个;即将重复出现字符串压缩为一个字符串。
-t, –truncate-set1 先删除第一字符集较第二字符集多出的字符
字符集合范围:
NNN 八进制值的字符 NNN (1 to 3 为八进制值的字符)
\ 反斜杠
a Ctrl-G 铃声
Ctrl-H 退格符
f Ctrl-L 走行换页
Ctrl-J 新行
Ctrl-M 回车(^M)
Ctrl-I tab键
v Ctrl-X 水平制表符(�11)
CHAR1-CHAR2 :字符范围从 CHAR1 到 CHAR2 的指定,范围的指定以 ASCII 码的次序为基础,只能由小到大,不能由大到小。
[CHAR*] :这是 SET2 专用的设定,功能是重复指定的字符到与 SET1 相同长度为止
[CHAR*REPEAT] :这也是 SET2 专用的设定,功能是重复指定的字符到设定的 REPEAT 次数为止(REPEAT 的数字采 8 进位制计算,以 0 为开始)
[:alnum:] :所有字母字符与数字
[:alpha:] :所有字母字符
[:blank:] :所有水平空格
[:cntrl:] :所有控制字符
[:digit:] :所有数字
[:graph:] :所有可打印的字符(不包含空格符)
[:lower:] :所有小写字母
[:print:] :所有可打印的字符(包含空格符)
[:punct:] :所有标点字符
[:space:] :所有水平与垂直空格符
[:upper:] :所有大写字母
[:xdigit:] :所有 16 进位制的数字
[=CHAR=] :所有符合指定的字符(等号里的 CHAR,代表你可自订的字符)
实例:
1)实现文件中字符的大小写转换(其中grep -v “^$”去除空白行)
[root@VM_0_10_centos tmp]# head -n 5 passwd | grep -v "^$" |tr a-z A-Z
LIBSTORAGEMGMT:X:998:997:DAEMON ACCOUNT FOR LIBSTORAGEMGMT:/VAR/RUN/LSM:/SBIN/NOLOGIN
RPC:X:32:32:RPCBIND DAEMON:/VAR/LIB/RPCBIND:/SBIN/NOLOGIN
或
[root@VM_0_10_centos tmp]# head -n 5 passwd | grep -v "^$" |tr [:lower:] [:upper:]
LIBSTORAGEMGMT:X:998:997:DAEMON ACCOUNT FOR LIBSTORAGEMGMT:/VAR/RUN/LSM:/SBIN/NOLOGIN
RPC:X:32:32:RPCBIND DAEMON:/VAR/LIB/RPCBIND:/SBIN/NOLOGIN
PS:数字转换也是同样,如 [0-9] [a-z]
2)将file1文件中的“wsxrfv”替换为“change”
[root@VM_0_10_centos tmp]# cat file1 | tr "wsxrfv" "qazedc"
qazedc
PS:在file1文件中出现的"w"字母,都替换成"c"字母,"s"字母替换为"h"字母,"x"字母替换为"a"字母。而不是将字符串"wsxrfv"替换为字符串"change"。这里的替换不修改源文件
3)删除文件中出现的字符“wx”。(和上面一样,不单单是删除字符串,而是包含了w和x和字符)
[root@VM_0_10_centos tmp]# cat file1 | tr -d "wx"
srfv
PS:如果要删除空格和换行,需要用转义字符。如:-d " "
4)删除Windows文件造成的"^M"字符
[root@VM_0_10_centos tmp]# cat file1 | tr -d " "
或
[root@VM_0_10_centos tmp]# cat file1 | tr -s " " " "
5)加密解密
[root@VM_0_10_centos tmp]# echo 110002222 | tr [0-9] [123456]
221113333
[root@VM_0_10_centos tmp]# echo 221113333 | tr [123456] [0-9]
110002222
6)古罗马时期发明的凯撒加密的一种变体ROT13(ROT13是它自己本身的逆反;也就是说,要还原ROT13,套用加密同样的算法即可得,故同样的操作可用再加密与解密。非常神奇!)
[root@VM_0_10_centos tmp]# echo "hi,this is amosli" | tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' 'NOPQRSTUVW
XYZABCDEFGHIJKLMnopqrstuvwxyzabcdefghijklm'uv,guvf vf nzbfyv
[root@VM_0_10_centos tmp]# echo "uv,guvf vf nzbfyv" | tr 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz' 'NOPQRSTUVW
XYZABCDEFGHIJKLMnopqrstuvwxyzabcdefghijklm'hi,this is amosli
7)字符集补集(set1的补集意味着从这个集合中包含set1中没有的所有字符。最典型的用法就是从输入文本中将不在补集中的所有字符全部删除。例如:)
[root@VM_0_10_centos tmp]# echo "hello 123 world " | tr -d -c '0-9 '
123
PS:在这里,补集中包含了除数字、空格字符和换行符之外的所有字符,因为指定了-d,所以这些字符全部都会被删除。
8)只删除空白行(比如一个文档中有多处不连续的空白行,我们需要做的就是将这些空白行删除或替换掉)(5种方法实现)
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | tr -s ' ' # -s删除重复出现的指定符号,合并为一个
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | grep -v "^$" # -v取反,^$以空白行开头
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | sed '/^$/d' # d参数表示删除
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | awk '{if($0 != "")print}' #$0取出文件中所有内容,将不等于空的内容打印出来
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | awk '{if(length != 0)print}' # 将长度不等于0的打印处理。及空白行不打印
参考网址:https://www.cnblogs.com/ginvip/p/6354440.html
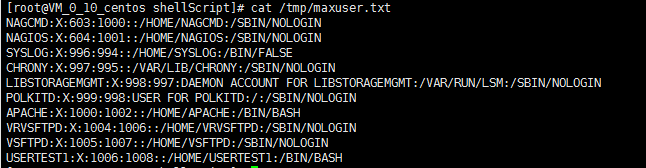
9)将/etc/passd中的第三个字段设置最大的后10个用户的信息全部改为大写保存至/tmp/maxuser.txt文件中(-k 指定取的列)
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | sort -t ':' -k 3 -n | tail -n 10 | tr '[a-z]' '[A-Z]' > /tmp/maxuser.txt
或取出/etc/group第三个字段数值最小的10个组的名字
[root@VM_0_10_centos shellScript]# cat /tmp/group | sort -t ":" -k 3 -n | head -n 10 | cut -d ":" -f 1

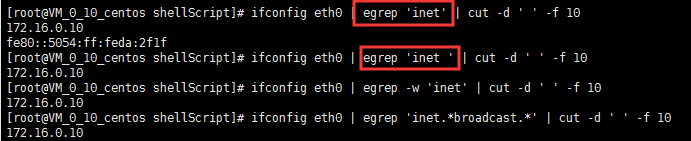
10)取出当前主机的IP地址
[root@VM_0_10_centos shellScript]# ifconfig eth0 | sed -n '2p' | sed 's/.*inet//g' | sed 's/netmask.*//g'
172.16.0.10
或(一下这些方法均可实现)
11)列出/etc目录下所有已.conf结尾的文件的文件名,并将其名字转换为大写后保存至/tmp/etc.conf文件中

七、wc命令
wc命令用于文本行数统计。
格式:
Usage: wc [OPTION]... [FILE]...
选项:
-c 统计字节数。
-l 统计行数。
-m 统计字符数。这个标志不能与 -c 标志一起使用。
-w 统计字数(字符串)。一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L 打印最长行的长度。
实例:
1)统计当前系统中有多少个用户
[root@VM_0_10_centos shellScript]# wc -l /etc/passwd
35 /etc/passwd
八、stat命令
stat命令英语查看文件的具体存储和时间等信息。会显示出三种状态(Access、Modify、Change)分别对应atime、mtime、ctime
借网友一张图

格式:
stat 文件名称
参数:
-f 不显示文件本身的信息,显示文件所在文件系统的信息
-L 显示符号链接
-C 文件权限
-t 简洁模式,只显示摘要信息
事实上,stat命令显示的是文件的I节点信息。Linux文件系统以块为单位存储信息,为了找到某一个文件所在存储空间的位置,用I节点对每个文件进行索引。
所谓的I节点,是文件系统管理的一个数据结构,是一个64字节长的表,包含了描述文件所必要的全部信息,其中包含了文件的大小,类型,存取权限,文件的所有者
实例:
1)查看文件的信息
[root@VM_0_10_centos shellScript]# stat users.txt
File: ‘users.txt’
Size: 68 Blocks: 8 IO Block: 4096 regular file
Device: fd01h/64769d Inode: 794494 Links: 1
Access: (0755/-rwxr-xr-x) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-10-10 09:44:56.660101721 +0800
Modify: 2019-10-10 09:44:56.660101721 +0800
Change: 2019-10-14 09:16:33.175799491 +0800
Birth: -
PS:使用ls也可以达到上面的效果
[root@VM_0_10_centos shellScript]# ls -l users.txt ==》mtime最后修改时间(偏向文件内容改变)
-rwxr-xr-x 1 root root 68 Oct 10 09:44 users.txt
[root@VM_0_10_centos shellScript]# ls -lc users.txt ==》ctime最后更改时间(偏向修改属性。如用户,组,权限,属性,内容)
-rwxr-xr-x 1 root root 68 Oct 14 09:16 users.txt
[root@VM_0_10_centos shellScript]# ls -lu users.txt ==》atime最后访问时间
-rwxr-xr-x 1 root root 68 Oct 10 09:44 users.txt
比如,vi 修改文件保存退出,mtime、atime、ctime都会修改,但是通过chown、chmod修改文件,ctime会改变。mtime不会改变。
修改属性之前:
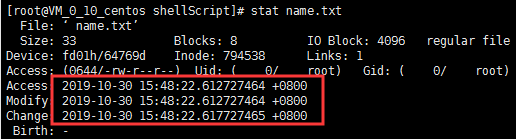
修改属性之后:
[root@VM_0_10_centos shellScript]# chmod +x name.txt
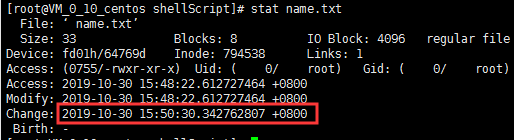
IO Block:逻辑块的大小为4096个字节
Blocks:物理最小块是512,而IO Block为4096,所以这里就占用了8个物理块的意思
补充:
1)stat除了查看文件,还能查看硬盘,文件系统的信息

2)touch命令能更改atime、ctime、mtime(时间戳)
用法:
-a 或--time=atime或--time=access或--time=use 只更改访问时间。
-m 或--time=mtime或--time=modify 只更改修改时间
-d、-t 指定的日期时间,现在的时间
修改访问时间atime:(ctime时间也改变了,这是由于文件的状态发生了变化,所以ctime自动也更新了时间)

修改时间:

通过-m选项改了文件的修改时间,ctime依然更新了。touch指令依然只是修改了修改时间,而状态时间是系统自己更新的。
九、cut命令
cut命令按“列”提取文本字符。经常与awk连用
格式:
cut [参数] 文件
cut [-bn] [file]
cut [-c] [file]
cut [-df] [file]
参数:
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。
-c :以字符为单位进行分割。
-d :自定义分隔符,默认为制表符。
-f :与-d一起使用,指定显示哪个区域。
-n :取消分割多字节字符。仅和 -b 标志一起使用。如果字符的最后一个字节落在由 -b 标志的 List 参数指示的
范围之内,该字符将被写出;否则,该字符将被排除
PS:"-":在index前,表示从字串头开始;放在index后,表示从index开始到字串末尾;在两个index之间,表示从index1到index2。还有这个“,”可以选择的不连续的域。

实例:
现在我们就来尝试一下cut这个命令吧。文件内容为“abc:def:hij”
1)截取第三个字符
[root@VM_0_10_centos shellScript]# cut -c 3 cut.txt
c
2)截取第3到第6之间的字符
[root@VM_0_10_centos shellScript]# cut -c 3-6 cut.txt
c:de
3)截取从第3个字符开始到最后一个字符
[root@VM_0_10_centos shellScript]# cut -c 3- cut.txt
c:def:hij
4)截取前3个字符
[root@VM_0_10_centos shellScript]# cut -c -3 cut.txt
abc
5)连续截取指定字符
[root@VM_0_10_centos shellScript]# cut -c 3-5,8-9 cut.txt
c:d:h
PS:这里我尝试使用-3-5,会出现报错情况,猜想是格式不支持。
6)使用cut命令提取passwd中的用户名信息(-d指定分隔符,-f指定提取第几列的内容)
[root@VM_0_10_centos shellScript]# head -n 5 /tmp/passwd | grep -v "^$" | cut -d : -f 1
libstoragemgmt
rpc
7)取出当前系统上被用户当做其默认shell最多的那个shell(sort -n 按数值大小排序,uniq -c 统计不重复的匹配字符)
[root@VM_0_10_centos shellScript]# cut -d ':' -f 7 /tmp/passwd | uniq -c | sort -n | tail -n 1 | cut -d ' ' -f 7
/sbin/nologin
或
[root@VM_0_10_centos shellScript]# cat /tmp/passwd | awk -F : '{print $7}' | uniq -c | sort -n | tail -n 1 | awk -F " " '{pr
int $2}'/sbin/nologin


十、diff命令
diff目录名用于比较多个文本文件的差异(一行一行的比较)。如果指定要比较目录,则diff会比较目录中相同文件名的文件,但不会比较其中子目录。在使用diff命令时,可以使用--brief参数来确认两个文件是否不通,还可以使用-c参数来详细比较多个文件之间的差异。
diff工具标记出来的不同之处并不会以颜色区分开来,这时可以使用colordiff命令,系统默认是没有安装的。直接安装即可(yum -y install colordiff)
格式:
Usage: diff [OPTION]... FILES
选项:
-<行数> 指定要显示多少行的文本。此参数必须与-c或-u参数一并使用。
-a或--text diff预设只会逐行比较文本文件。
-b或--ignore-space-change 不检查空格字符的不同。
-B或--ignore-blank-lines 不检查空白行。
-c 显示全部内文,并标出不同之处。
-C<行数>或--context<行数> 与执行"-c-<行数>"指令相同。
-d或--minimal 使用不同的演算法,以较小的单位来做比较。
-D<巨集名称>或ifdef<巨集名称> 此参数的输出格式可用于前置处理器巨集。
-e或--ed 此参数的输出格式可用于ed的script文件。
-f或-forward-ed 输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处。
-H或--speed-large-files 比较大文件时,可加快速度。
-l<字符或字符串>或--ignore-matching-lines<字符或字符串> 若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异。
-i或--ignore-case 不检查大小写的不同。
-l或--paginate 将结果交由pr程序来分页。
-n或--rcs 将比较结果以RCS的格式来显示。
-N或--new-file 在比较目录时,若文件A仅出现在某个目录中,预设会显示:
Only in目录:文件A若使用-N参数,则diff会将文件A与一个空白的文件比较。
-p 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称。
-P或--unidirectional-new-file 与-N类似,但只有当第二个目录包含了一个第一个目录所没有的文件时,才会将这个文件与空白的文件做比较。
-q或--brief 仅显示有无差异,不显示详细的信息。
-r或--recursive 比较子目录中的文件。
-s或--report-identical-files 若没有发现任何差异,仍然显示信息。
-S<文件>或--starting-file<文件> 在比较目录时,从指定的文件开始比较。
-t或--expand-tabs 在输出时,将tab字符展开。
-T或--initial-tab 在每行前面加上tab字符以便对齐。
-u,-U<列数>或--unified=<列数> 以合并的方式来显示文件内容的不同。
-v或--version 显示版本信息。
-w或--ignore-all-space 忽略全部的空格字符。
-W<宽度>或--width<宽度> 在使用-y参数时,指定栏宽。
-x<文件名或目录>或--exclude<文件名或目录> 不比较选项中所指定的文件或目录。
-X<文件>或--exclude-from<文件> 您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件。
-y或--side-by-side 以并列的方式显示文件的异同之处。
--left-column 在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容。
--suppress-common-lines 在使用-y参数时,仅显示不同之处。
比较结果说明:
"|"表示前后2个文件内容有不同
"<"表示后面文件比前面文件少了1行内容
">"表示后面文件比前面文件多了1行内容
实例:
先准备好两个文件
[root@VM_0_10_centos shellScript]# more file1.txt file2.txt
::::::::::::::
file1.txt
::::::::::::::
1234567890
1234567890
qwertyuiop
1234567890
asdfghjkl;
::::::::::::::
file2.txt
::::::::::::::
1234567890
qwertyuiop
1234567890
asdfghjkl
1234567890
1)首先比较他们的不同(等价于--normal参数)
[root@VM_0_10_centos shellScript]# diff file1.txt file2.txt
2d1
< 1234567890
5c4,5
< asdfghjkl;
---
> asdfghjkl
> 1234567890
PS:5c4,5中的5代表第一个文件中的行,字母c表示需要在第一个文件上做的操作(a=add,c=change,d=delete),后面的4,5表示第二个文件中的行。
2d1含义:需要将第一个文件中第二行“1234567890”删除掉才能和第二个文件的内容匹配
5c4,5含义:需要将第一个文件中第五行“asdfghjkl;”内容修改才能和第二个文件的内容匹配
---含义:两个文件的分隔符
>含义:表示后面的文件(第二个文件)
<含义:表示前面的文件(第一个文件)
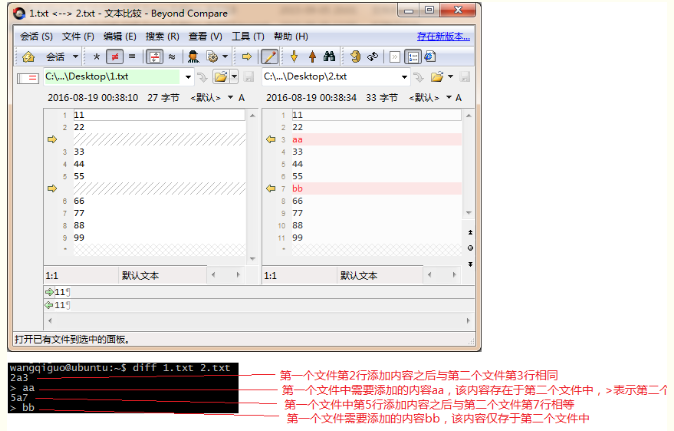
2)diff -c方式

3) 使用diff –u 比较的结果:

4)比较目录(比较两个目录的时候无非是有的文件仅仅存在于某个目录中而在另一个目录中没有,如果存在同名的文件,则比较这两个文件的不同)
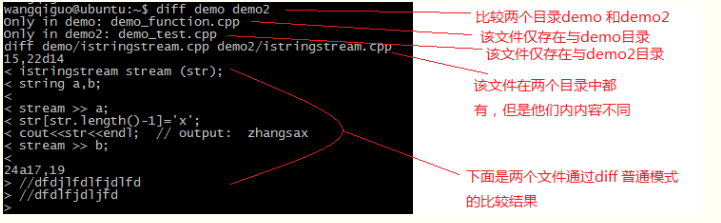
5)参数 -e 将比较的结果保存成一个ed脚本,之后ed程序可以执行该脚本文件,从而将file1修改成与file2的内容相同,这一般在patch的时候有用。
diff -e 1.txt 2.txt > script.txt
这样就是生成了一个ed可以执行的脚本文件script.txt,生成脚本文件之后我们还需要做一个操作, 在脚本文件末尾添加ed的write指令,只需要执行 echo "w" >>script.txt 将w指令附加到脚本文件的最后一行即可。
那么如何应用该脚本文件呢,可以这样使用:
ed - 1.txt < script.txt
注意中间的 – 符号表示从标准输入中读取,而 < script.txt 则重定向script.txt的内容到标准输入。这样执行之后1.txt的内容将与2.txt完全相同。
6)使用--berief参数比较两个文件是否相等
[root@VM_0_10_centos shellScript]# diff --brief file1.txt file2.txt