运用CDH5.15离线搭建简易版集群
关于CDH和Cloudera
CDH(Cloudera的发行版,包括Apache Hadoop),是Hadoop众多分支中的一种,由Cloudera维护,基于稳定版本的Apache Hadoop构建,并集成了很多补丁,可直接用于生产环境.Cloudera Manager则是为了便于在集群中进行的Hadoop等大数据处理相关的服务安装和监控管理的组件,对集群中主机,Hadoop的,蜂巢,星火等服务的安装配置管理做了极大简化。
安装说明
官方共给出了3中安装方式:第一种方法必须要求所有机器都能连网,由于最近各种国外的网站被墙的厉害,我尝试了几次各种超时错误,巨耽误时间不说,一旦失败,重装非常痛苦。第二种方法下载很多包。第三种方法对系统侵入性最小,最大优点可实现全离线安装,而且重装什么的都非常方便。后期的集群统一包升级也非常好。这也是我之所以选择离线安装的原因
系统环境
-
实验环境:windows10下的VMware虚拟机
-
操作系统:CentOS 7.2 x64(至少内存2G以上,这里内存不够的同学建议还是整几台真机配置比较好,将CDH的所有组件全部安装会占用很多内存,我一开始设置的虚拟机内存是1G ,安装过程中直接卡死了),本人采用分配方案为:三台虚拟机分别分别作为主站(主节点),SLAVE1,SLAVE2,配置分别为主内存为16G,SLAVE1内存为8G,SLAVE2内存为8G ,根据个人情况来进行配置但是掌握分配内存过小的话会出现内存不足等问题。
-
Cloudera Manager:5.15.0
-
CDH:5.15.0
相关包的下载地址
Cloudera Manager下载地址:http://archive.cloudera.com/cm5/redhat/5/x86_64/cm/5.15.0/RPMS/x86_64/
CDH安装包地址:http://archive.cloudera.com/cdh5/parcels/latest/,由于我们的操作系统为CentOS7.2,需要下载以下文件:
-
CDH-5.15.0-1.cdh5.15.0.p0.21-el7.parcel
-
CDH-5.15.0-1.cdh5.15.0.p0.21-el7.parcel.sha1
-
manifest.json
注意:与CDH4的不同,原来安装CDH4的时候还需要下载IMPALA,Cloudera Search(SOLR),CDH5中将他们包含在一起了,所以只需要下载一个CDH5的包就可以了
准备工作:系统环境搭建
以下操作均用根用户操作。
1.网络配置(所有节点都要执行以下操作)
1.1 修改主机名:
#编辑目录/etc/sysconfig/network
vi /etc/sysconfig/network
#添加以下内容
NETWORKING=yes
HOSTNAME=master通过服务网络重启重启网络服务生效。
1.2修改ip与主机名的对应关系
#编辑文件
vi /etc/hosts
#将其中的内容改为你自己的信息
192.168.153.132 master
192.168.153.133 slave1
192.168.153.134 slave2注意:这里需要将每台机器的IP及主机名对应关系都写进去,本机的也要写进去,否则启动代理的时候会提示主机名解析错误。
2.打通SSH,设置SSH无密码登陆
-
在主节点上执行以下代码一路回车,生成无密码的密钥对。
[root@master ~]# ssh-keygen -t rsa-
将公钥添加到认证文件中,并设置authorized_keys文件的访问权限:
#将公钥添加到认证文件中
[root@master ~]# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
#设置authorized_keys的访问权限
[root@master ~]# chmod 600 ~/.ssh/authorized_keys
-
SCP文件到所有datenode节点:
#将文件拷到slave1中
[root@master ~]# scp ~/.ssh/authorized_keys root@slave1:~/.ssh/
#将文件拷到slave2中
[root@master ~]# scp ~/.ssh/authorized_keys root@slave2:~/.ssh/测试:在主节点上ssh n2,正常情况下,不需要密码就能直接登陆进去了。
此时只是主访问SLAVE1和SLAVE2不需要密码但是SLAVE1和SLAVE2访问主还是要密码的所以此时要设置他们之间的相互免密
在SLAVE1和SLAVE2中分别执行以下代码(以下以SLAVE1为例)
#生成公钥
[root@slave1 ~]# ssh-keygen -t rsa
[root@slave1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@master
[root@slave1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@slave23.安装甲骨文的Java的(所有节点)
CentOS,自带OpenJdk,不过运行CDH5需要使用Oracle的Jdk,需要Java 7的支持。
卸载自带的OpenJDK的
使用以下代码查询的Java相关的包,
rpm -qa | grep java使用rpm -e --nodeps 包名卸载之。
去的Oracle的官网下载JDK的转安装包。
使用并rpm -ivh 包名安装之。
由于是RPM包并不需要我们来配置环境变量,我们只需要配置一个全局的JAVA_HOME变量即可,执行命令:
echo "JAVA_HOME=/usr/java/latest/" >> /etc/environment4.安装配置的MySQL(主节点)
执行以下代码安装的MySQL
wget http://repo.mysql.com/mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
设置开机自启动
chkconfig mysqld on启动mysql的服务
service mysqld start此时输入的MySQL是进不去的MySQL的,因为MySQL的为根生成一个动态的密码我们需要设置自己的密码
首先我们需要在配置文件的/etc/my.cnf里面最后一行添加以下代码在之后修改完代码之后需要再次进入将其注释掉
skip-grant-tables之后进入mysql的输入mysql的即可
输入以下代码修改密码
update user set authentication_string=password('123456') where user='root';如果此时报错显示1819的错误需要进行以下设置
set global validate_password_policy=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=3;
set global validate_password_special_char_count=0;
set global validate_password_length=3;在MySQL的中创建表并且赋予权限
CREATE DATABASE scm DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON scm.* TO 'scm'@'%' IDENTIFIED BY 'scm';
CREATE DATABASE amon DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON amon.* TO 'amon'@'%' IDENTIFIED BY 'amon';
CREATE DATABASE rman DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON rman.* TO 'rman'@'%' IDENTIFIED BY 'rman';
CREATE DATABASE hue DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON hue.* TO 'hue'@'%' IDENTIFIED BY 'hue';
CREATE DATABASE hive DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON hive.* TO 'hive'@'%' IDENTIFIED BY 'hive';
CREATE DATABASE sentry DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON sentry.* TO 'sentry'@'%' IDENTIFIED BY 'sentry';
CREATE DATABASE oozie DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL ON oozie.* TO 'oozie'@'%' IDENTIFIED BY 'oozie';
#这是授权root用户在主节点拥有所有数据库的访问权限
grant all privileges on *.* to 'root'@'master' identified by '123456' with grant option;
flush privileges;5.安装ntp服务(所有节点)
集群中所有主机必须保持时间同步,如果时间相差较大会引起各种问题。具体思路如下:
主节点作为NTP服务器与外界对时中心同步时间,随后对所有数据节点节点提供时间同步服务。
所有数据节点节点以主节点为基础同步时间所有节点安装相关组件执行以下命令:
yum install ntp完成后配置开机启动经检验执行chkconfig ntpd on并不能使开机启动需执行以下代码主要原因是chronyd服务启动会限制ntp的自启动
#关闭chronyd服务
systemctl disable chronyd.service
#开机自启动
systemctl enable ntpd.service 主节点配置
位置/etc/ntp.conf中
ntp服务只有一个配置文件,配置好了就OK。这里只给出有用的配置,不需要的配置都用#注掉,这里就不在给出:
driftfile /var/lib/ntp/drift
restrict 127.0.0.1
restrict ::1
restrict default nomodify
restrict default nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys配置文件完成,保存退出,启动服务,执行如下命令:
systemctl start ntpd检查是否成功,用ntpstat命令查看同步状态,出现以下状态代表启动成功:
synchronised to local net at stratum 11
time correct to within 12 ms
polling server every 64 s
如果出现异常请等待几分钟,一般等待5-10分钟才能同步。
配置NTP客户端(所有数据节点节点)
driftfile /var/lib/ntp/drift
restrict 127.0.0.1
restrict ::1
restrict default nomodify notrap nopeer noquery
restrict -6 default kod nomodify notrap nopeer noquery
#这里是主节点的主机名或者ip
server master
includefile /etc/ntp/crypto/pw
keys /etc/ntp/keys注意:主节点和从节点的/etc/ntp.conf中的最后一行#disable monitor要注释掉
ok保存退出,请求服务器前,请先使用ntpdate手动同步一下时间:( ntpdate -u master 主节点ntp服务器)
这里可能出现同步失败的情况,请不要着急,一般是本地的NTP服务器还没有正常启动,一般需要等待5-10分钟才可以正常同步启动服务:service ntpd start因为是连接内网,这次启动等待的时间会比主节点快一些,但是也需要耐心等待一会儿。
6.关闭防火墙和SELinux的
关闭防火墙执行以下命令
systemctl stop firewalld
systemctl disable firewalld正式开工
安装Cloudera Manager Server和Agent
解压下载的cloudera-manager-centos7-cm5.15.0_x86_64.tar.gz:
tar xzvf cloudera-manager*.tar.gz文件名称如下所示
- Cloudera-manager-agent-5.15.0-1.cm5150.p0.62.el7.x86_64.rpm
- Cloudera-manager-daemons-5.15.0-1.cm5150.p0.62.el7.x86_64.rpm
- Cloudera-manager-server-5.15.0-1.cm5150.p0.62.el7.x86_64.rpm
将以下包放入主自己创建的一个目录中,位置为/选择/ cloudera_macnage
- Cloudera-manager-agent-5.15.0-1.cm5150.p0.62.el7.x86_64.rpm
- Cloudera-manager-daemons-5.15.0-1.cm5150.p0.62.el7.x86_64.rpm
- Cloudera-manager-server-5.15.0-1.cm5150.p0.62.el7.x86_64.rpm
将以下包放入SLAVE1和SLAVE2自己创建的一个目录为/选择/ cloudera_manage中
- Cloudera-manager-agent-5.15.0-1.cm5150.p0.62.el7.x86_64.rpm
- Cloudera-manager-daemons-5.15.0-1.cm5150.p0.62.el7.x86_64.rpm
执行代码
yum localinstall *.rpm在所有节点上安装对应的rpm包,包管理器会自动解决依赖问题
所有节点需安装的MySQL的驱动程序,地址下载 http://dev.mysql.com/downloads/connector/j/
本人下载的驱动版本如下
MySQL的连接器的Java-5.1.46.tar.gz
将下载下来的MySQL的连接器的Java-5.1.46.tar.gz放到每个节点的/选择/ cloudera_manage中
下载下来之后执行以下命令(所有节点)
tar zxvf mysql-connector-java-5.1.46.tar.gz
mkdir -p /usr/share/java
cd mysql-connector-java-5.1.46
cp mysql-connector-java-5.1.46-bin.jar /usr/share/java/mysql-connector-java.jar在主节点为鼎晖初始化数据库执行以下命令
/usr/share/cmf/schema/scm_prepare_database.sh mysql scm scm scm
/usr/share/cmf/schema/scm_prepare_database.sh mysql amon amon amon
/usr/share/cmf/schema/scm_prepare_database.sh mysql rman rman rman
/usr/share/cmf/schema/scm_prepare_database.sh mysql hue hue hue
/usr/share/cmf/schema/scm_prepare_database.sh mysql hive hive hive
/usr/share/cmf/schema/scm_prepare_database.sh mysql sentry sentry sentry
/usr/share/cmf/schema/scm_prepare_database.sh mysql oozie oozie oozie在主主节点创建包裹回购仓库
执行以下命令
mkdir -p /opt/cloudera/parcel-repo
chown cloudera-scm:cloudera-scm /opt/cloudera/parcel-repo将以下三个文件放入/opt/ Cloudera/ percel-repo回购中
-
CDH-5.15.0-1.cdh5.15.0.p0.21-el7.parcel
-
CDH-5.15.0-1.cdh5.15.0.p0.21-el7.parcel.sha1
-
manifest.json
将CDH-5.15.0-1.cdh5.15.0.p0.21-el7.parcel.sha1重命名为CDH-5.15.0-1.cdh5.15.0.p0.21-el7.parcel.sha
修改SLAVE1和SLAVE2的/etc/cloudera-scm-agent/config.ini
将SERVER_HOST改为管理节点的网络名本例为主
在主节点启动代理和服务器执行以下命令
systemctl start cloudera-scm-agent
systemctl start cloudera-scm-server在SLAVE1和SLAVE2执行以下代码
systemctl start cloudera-scm-agentCDH5的安装配置
Cloudera Manager Server和Agent都启动以后,就可以进行CDH5的安装配置了。
这时可以通过浏览器访问主节点的7180端口测试一下了(由于CM Server的启动需要花点时间,这里可能要等待一会才能访问),默认的用户名和密码均为admin:
访问地址为主:7180
进入界面
![]()
可以看到,免费版本的CM5已经没有原来50个节点数量的限制了。
![]()

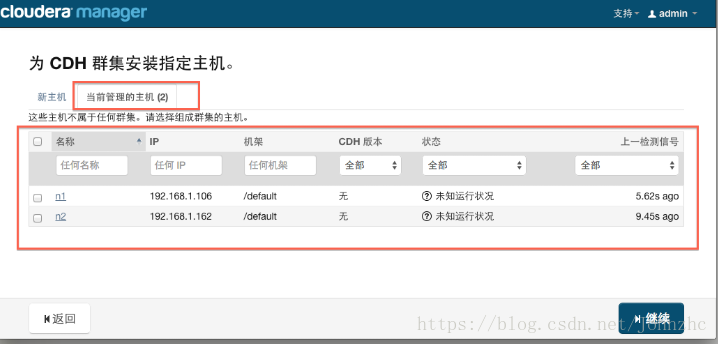
各个代理节点正常启动后,可以在当前管理的主机列表中看到对应的节点。选择要安装的节点,点继续。
![]()
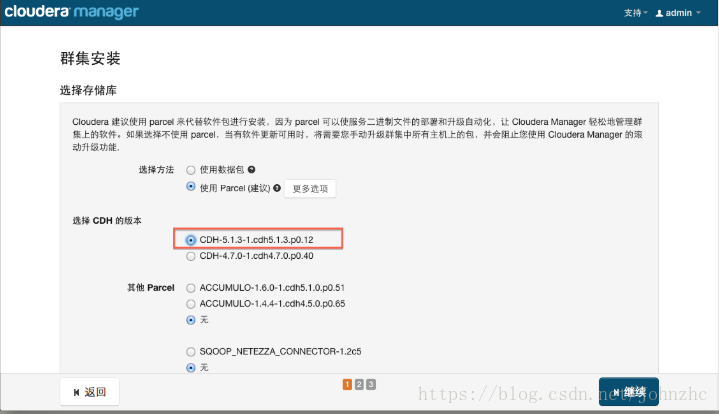
接下来,出现以下包名,说明本地包裹包配置无误,直接点继续就可以了。
![]()
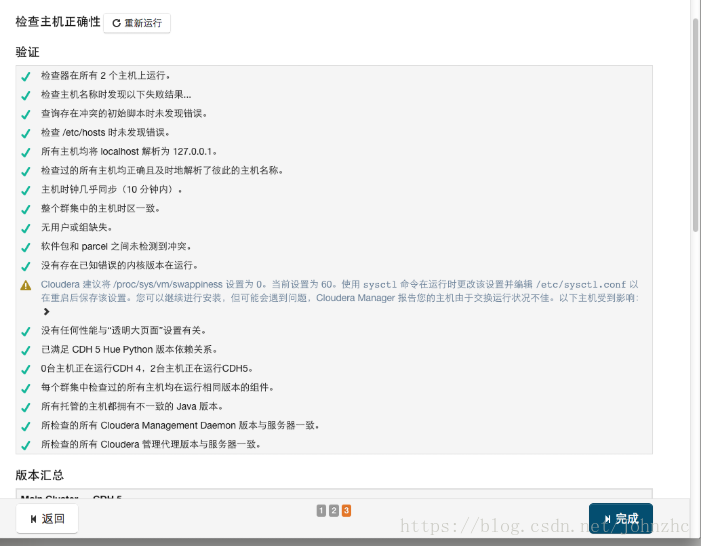
接下来是服务器检查
![]()
接下来是选择安装服务,此步骤可以跳过在之后安装,点击左上角cloudera manage图标跳过即可也可根据情况自行安装
![]()
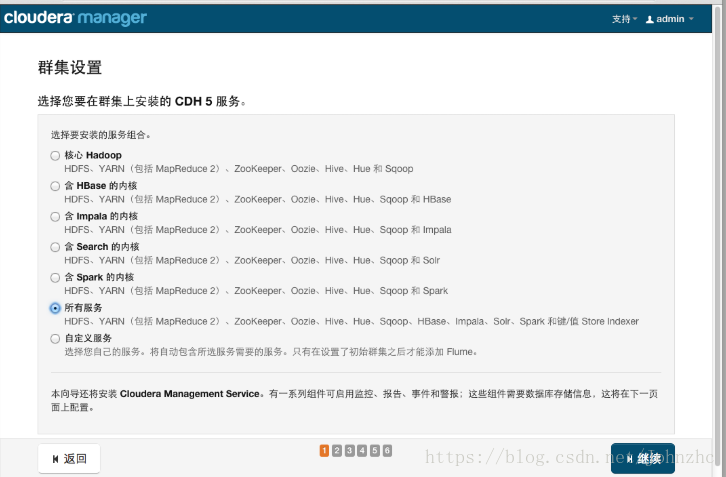
安装之后的结果如下
![]()
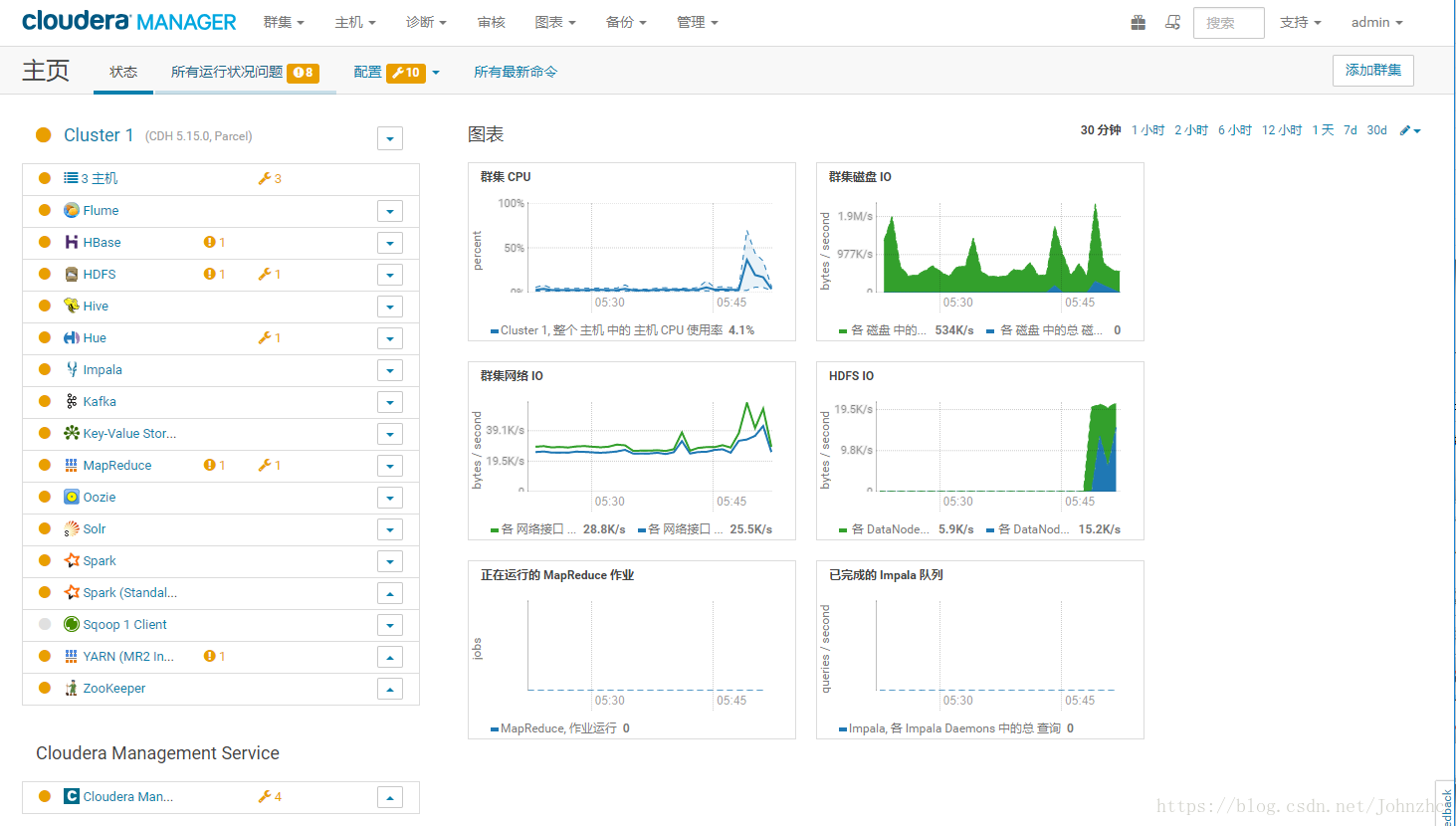
测试
在集群的一台机器上执行以下模拟皮的示例程序:
sudo -u hdfs hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 10 100MapReduce的执行过程中终端的输出如下:
Number of Maps = 10
Samples per Map = 100
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
14/10/13 01:15:34 INFO client.RMProxy: Connecting to ResourceManager at n1/192.168.1.161:8032
14/10/13 01:15:36 INFO input.FileInputFormat: Total input paths to process : 10
14/10/13 01:15:37 INFO mapreduce.JobSubmitter: number of splits:10
14/10/13 01:15:39 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1413132307582_0001
14/10/13 01:15:40 INFO impl.YarnClientImpl: Submitted application application_1413132307582_0001
14/10/13 01:15:40 INFO mapreduce.Job: The url to track the job: http://n1:8088/proxy/application_1413132307582_0001/
14/10/13 01:15:40 INFO mapreduce.Job: Running job: job_1413132307582_0001
14/10/13 01:17:13 INFO mapreduce.Job: Job job_1413132307582_0001 running in uber mode : false
14/10/13 01:17:13 INFO mapreduce.Job: map 0% reduce 0%
14/10/13 01:18:02 INFO mapreduce.Job: map 10% reduce 0%
14/10/13 01:18:25 INFO mapreduce.Job: map 20% reduce 0%
14/10/13 01:18:35 INFO mapreduce.Job: map 30% reduce 0%
14/10/13 01:18:45 INFO mapreduce.Job: map 40% reduce 0%
14/10/13 01:18:53 INFO mapreduce.Job: map 50% reduce 0%
14/10/13 01:19:01 INFO mapreduce.Job: map 60% reduce 0%
14/10/13 01:19:09 INFO mapreduce.Job: map 70% reduce 0%
14/10/13 01:19:17 INFO mapreduce.Job: map 80% reduce 0%
14/10/13 01:19:25 INFO mapreduce.Job: map 90% reduce 0%
14/10/13 01:19:33 INFO mapreduce.Job: map 100% reduce 0%
14/10/13 01:19:51 INFO mapreduce.Job: map 100% reduce 100%
14/10/13 01:19:53 INFO mapreduce.Job: Job job_1413132307582_0001 completed successfully
14/10/13 01:19:56 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=91
FILE: Number of bytes written=1027765
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2560
HDFS: Number of bytes written=215
HDFS: Number of read operations=43
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=118215
Total time spent by all reduces in occupied slots (ms)=11894
Total time spent by all map tasks (ms)=118215
Total time spent by all reduce tasks (ms)=11894
Total vcore-seconds taken by all map tasks=118215
Total vcore-seconds taken by all reduce tasks=11894
Total megabyte-seconds taken by all map tasks=121052160
Total megabyte-seconds taken by all reduce tasks=12179456
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=340
Input split bytes=1380
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=340
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=1269
CPU time spent (ms)=9530
Physical memory (bytes) snapshot=3792773120
Virtual memory (bytes) snapshot=16157274112
Total committed heap usage (bytes)=2856624128
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 262.659 seconds
Estimated value of Pi is 3.14800000000000000000柯林斯也。参考以下地址 https://www.cnblogs.com/CaptainLin/p/7089766.html