需求
求按一定字段进行分组之后的每组最新或者版本最大的一条数据。
假设:
如书名和书编码相同时,则获取版本号最大(或创建时间最近)的一条数据;
PS:本文就以版本号最大为例子吧。实际依葫芦画瓢就明白其他的场景了。
预热准备
定义测试“书”表的DDL
CREATE TABLE `book` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL COMMENT '书名',
`code` varchar(64) DEFAULT NULL COMMENT '书编码',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`version` int(11) DEFAULT NULL COMMENT '版本号',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
PS:简简单单的数据字段,如有不严谨的地方请不要在意,这里仅仅用于说明本文需要讲解的场景哦!!!
随便插入几条测试数据的DML
INSERT INTO `book` VALUES ('1', '小白', '0001', '2020-04-07 21:07:44', '1');
INSERT INTO `book` VALUES ('2', '小白', '0001', '2020-04-08 21:07:59', '2');
INSERT INTO `book` VALUES ('3', '小黑', '0002', '2020-04-08 21:08:16', '1');
INSERT INTO `book` VALUES ('4', '小明', '0003', '2020-04-01 21:08:28', '2');
INSERT INTO `book` VALUES ('5', '小明', '0003', '2020-04-08 21:08:40', '3');
- 1
- 2
- 3
- 4
- 5
- 6
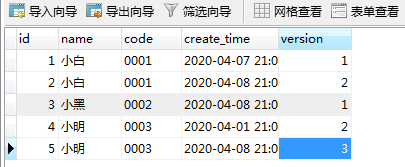
PS:瞎插几条数据,以表心意!!!!
方案设计
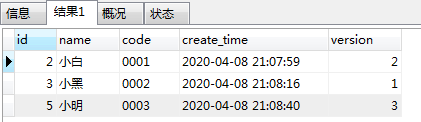
根据上面的样本数据再结合对应的需求,那么,**在理想状态下,**就是获取得到如下情况的数据: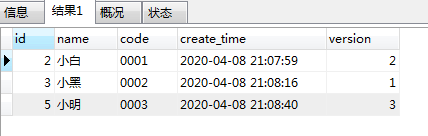
PS:为了让各位看的清楚,就特意按照id从小到大的排序了哈!!
错误方案一
采取简单直接的方式,即先分组和排序一起操作
select *
FROM
book
GROUP BY name,code
order by version desc, id asc
- 1
- 2
- 3
- 4
- 5
结果
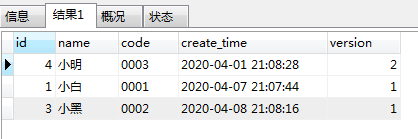
结论:这样的方案是错误的
对比,理想情况和实际情况,只能说,这种方案当然不行啦。那么为何不行呢?请继续看。。。。。
分析
- 首先,确实是将相同的name和code的内容进行了分组,即同样的name和code的数据只存在一条,说明group by没有毛病,是分组了。
- order by:其中id asc是升序,那么结果确实也是升序这个没问题;假设,觉得没用,那么大家可以试试没有加id asc的情况就如下,说明id asc 是生效了。
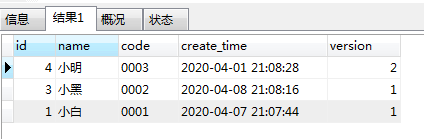
- order by:其中version desc是倒序,那么再看下实际情况,确实也是按照version倒序进行排序,那么说version desc也是有效果的。那么到底哪里有问题呢?
结论:这是因为当group by 和order by同时出现的时候,它是先执行group by 分组然后才对分组的结果进行的排序。因此,执行顺序是有问题,这样自然无法实现我们需要的取每组最大版本号的数据了。
错误方案二
经过上面错误方案的解析,那么这一种肯定可以。。自信满满!!!
select *
from
(
select *
from
book
ORDER BY version desc
)as t1
GROUP BY t1.name,t1.code
order by id asc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
结果
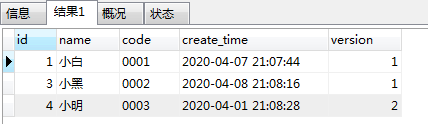
结论:这个方案结果还是不对!!!
分析
- 通过实际结果观察,id确实是升序,但是每条数据的version字段却不是最大的呀。
- 通过第一种错误方案说到,要先根据version排序,然后再group by 分组。那看看SQL,确实是先排序,再分组了。可是为什么不行?
结论:该方案还是由于排序和分组的效果被优化导致的。因为当外层存在group by语法时,会导致内层的order by 会失效,而mysql会默认采取“第一条”。关键来了,“第一条”,这个第一条并不是排序后的第一条,而是插入数据库同等分组条件下的顺序的第一条哦!
假设,我们把初始的数据变成如下,然后再执行该方案的SQL就发现结果与期望的一样啦。其原因就是在于上面说的。
=======================================
好气呀,这两种方案都不行,那到底怎么写呢。
别慌,继续往下面看
=======================================
正确方案一
select *
from
(
select *
from
book
ORDER BY version desc
limit 100000
)as t1
GROUP BY t1.name,t1.code
order by id asc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
结果
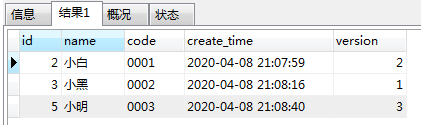
结论:哇塞,实际和预期是一样的结果了哦!!!
分析
- 我们对比一下错误方案二和现在这种方案,发现,就是因为该mysql内层采取了limit关键字进行“分页”处理。
- why?why?why?
结论: 因为在内层子查询中采取limit和order by同时作用的话,就会将子查询的结果根据对应语法进行实际的先排序后分页,而不会与外层的group by语法进行优化。因此,这样的效果就可以实现获取每组的版本号最大的数据了。
缺点: 很多朋友也应该想到了,那么就是如果子查询的结果集的条数是不知道的呢?那么limit如果小了,就会导致一些数据丢失,自然这样得到的结果就不准了。那么如何解决呢?
优化: 既然无法确定实际的查询数据条数,那么就可以先查询一下总的数据条数,然后limit就以该结果作为参数不就可以了嘛。对的,先查询子查询的总数据条数,然后limit该结果就可以了。切记,是分开两个SQL语句了哦!!!!
注意点: 这里要采取inner join而别采取left join或者right join(它们三者的区别就不多说了),除非你确定你的数据条件中,不存在null的情况,而都是一一对应而都存在,那么就没问题;
正确方案二
上面的方案存在一定的问题,那么还可以怎么做呢?
select t1.*
from
book as t1
INNER JOIN
(
SELECT name,code,max(version) as version
from
book
GROUP BY name,code
)as t2
on
t1.code = t2.code
and
t1.name = t2.name
and
t1.version = t2.version
order by id asc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
结果
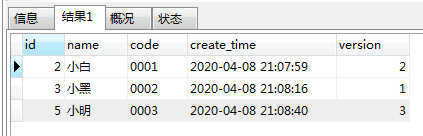
结论:实际和预期一样!
分析
该SQL实现的方式主要是用到了max函数的作用。
(1)我们逐步的拆分来看:
首先,
SELECT name,code,max(version) as version
from
book
GROUP BY name,code
- 1
- 2
- 3
- 4
我们先根据要分组的内容进行group by,注意这时候select的字段也是要将分组的字段进行获取,其次,就是采取max函数获取我们需要的version最大(同理,如果是创建时间也是一样)。那么这样处理得到的结果是什么呢?自然,这样就可以获取到每组中版本号最大的数据信息。注意,此时并没有达到我们想要的结果。因为如果我们还要获取到版本号最大的其他的字段的信息,而此时只是获取到版本号最大的,而其他字段并非就是版本号最大对应的所有字段信息。
(2)再通过inner join的语法作用。我们在(1)中已经获取到了每个分组条件以及需要版本号的最大的值,那么,通过inner join的等值连接,这样就可以根据“等值原理”获取到其对应的所有字段的信息了呀。那么就实现了我们的需求;
缺点: 可以发现在最里层的子查询中这样的效率是不好的,是走的全表扫描(PS:如果存在其他的限制条件通过有索引可以实现一点优化),那么全表扫描的效率就不够好了。
优化: 在里层的查询中,增加一定的限制条件,并且限制条件采取能够以索引处理;
正确方案三
那么还有其他的处理方案吗?
select t1.*
from
bookas t1
,
(
SELECT name,code,max(version) as version
from
book
GROUP BY name,code
)as t2
where
t1.code = t2.code
and
t1.name = t2.name
and
t1.version = t2.version
order by id asc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果