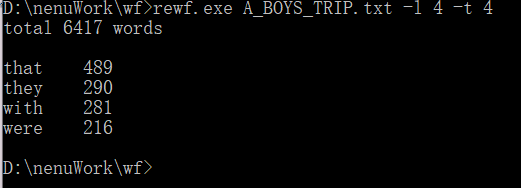此作业的要求参见[https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206]
1、功能一
程序执行结果如下图所示,

2、功能二
录入A_BOYS_TRIP测试

录入A_Year_With_A_Whaler测试
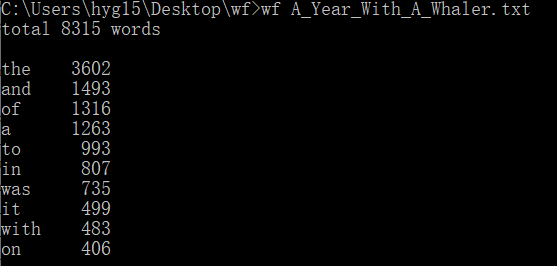
3、功能三
查看文件夹下的英文作品

输入文件名进行测试

(补充截图)

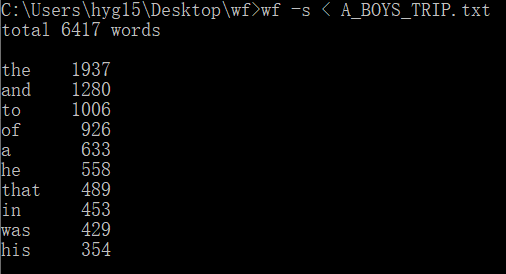
4、功能四
重定向输入测试
5、代码展示
该程序分为几个功能不同的函数,分别实现特定的操作。是我感觉自己做的比较满意的地方
1)、该函数根据输入的文件或文件夹的名称返回文件列表
'''isdir or isfile, return list'''
def filelist(filePath):
# get file list
if(os.path.isdir(filePath) == True):
# filePath is folder
return os.listdir(filePath)
elif(os.path.isfile(filePath) == True):
# filePath is file
return [filePath]
return
2)、该函数根据文件地址读取文件内容,并使用正则表达式分割文件内容为词汇列表。其中正则表达式是一大难点,也是一大亮点。
'''read file content'''
def opentxt(filePath):
with open(filePath, "r", encoding="utf-8") as file:
txtStr = file.read()
regEx = re.compile(u' |
|.|-|;|)|(|?|"') # genernal
txtStr = re.sub(regEx, '', txtStr)
return txtStr.lower().split() # translate lower
3)、该函数传入词汇列表,统计词汇出现次数并排序输出
'''word frequency statistics and print sorted'''
def printsort(strList, isfile = True):
strDict = { } # storage word dict
for str in strList:
strDict[str] = strDict.get(str, 0) + 1
strDictSort = sorted(strDict.items(), key = lambda item : item[1], reverse = True)
print("total %d words
" % len(strDictSort))
# format output
if(len(strDictSort) > 10):
for i in range(10):
print("{:5} {:5}".format(strDictSort[i][0], strDictSort[i][1]))
if(isfile == False):
print("----")
else:
for i in range(len(strDictSort)):
print("{:5} {:5}".format(strDictSort[i][0], strDictSort[i][1]))
if(isfile == False):
print("----")
return
4)、重定向执行函数,直接分割传入的保存文本的变量,使用上述printsort()函数排序输出
'''rediect word statistics'''
def redirect(strTxt):
regEx = re.compile(u' |
|.|-|;|)|(|?|"') # genernal
txtStr = re.sub(regEx, '', strTxt).lower().split()
printsort(txtStr)
return
5)、词频统计函数,其中使用上述已介绍的函数,根据传入参数为文件或是文件夹分别执行不同操作
'''word frequency statistics'''
def wordStatistics(filePath):
filePathList = filelist(filePath)
if(os.path.isfile(filePath)):
for file in filePathList:
printsort(opentxt(file))
else:
for file in filePathList:
print(file.split('.')[0])
printsort(opentxt(filePath + '\' + file), False)
return
6)、主函数
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# nargs - 命令行参数应当消耗的数目。
parser.add_argument("filePath", nargs = '?', help = "file or folder path") # filePath, file or folder
parser.add_argument('-s',nargs = '?', help = "file path")
args = parser.parse_args()
# wordStatistics(args.filePath)
if ((args.s == None) and (args.filePath == None)):
redi = sys.stdin.read() # redirect
redirect(redi)
pass
elif ((args.s == None) and (args.filePath != None)):
wordStatistics(args.filePath)
pass
elif ((args.s != None) and (args.filePath == None)):
wordStatistics(args.s)
pass
pass
6、PSP表
完成程序的四种功能的PSP表
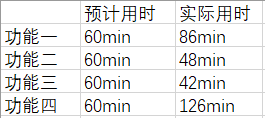
完成该博客任务所用时间的PSP表

7、代码及版本控制
GitHub中代码地址https://github.com/1501106169/nenuWork.git
coding中代码地址https://e.coding.net/nenuwork/nenuwork/nenuWork.git
8、功能五
修改源代码中的输出函数printsort(strList, isfile = True)为printsort(strList, top, leng, isfile=True)
def printsort(strList, top, leng, isfile=True):
strDict = { } # storage word dict
for str in strList:
strDict[str] = strDict.get(str, 0) + 1
strDictSort = sorted(strDict.items(), key = lambda item : item[1], reverse = True)
print("total %d words
" % len(strDictSort))
# format output
for i in range(len(strDictSort)):
if(top <= 0): break
if(len(strDictSort[i][0]) == leng or leng == -1):
print("{:5} {:5}".format(strDictSort[i][0], strDictSort[i][1]))
top -= 1
if(isfile == False):
print("----")
return
主函数修改为
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# nargs - 命令行参数应当消耗的数目。
parser.add_argument("filePath", nargs = '?', help = "file or folder path") # filePath, file or folder
parser.add_argument('-s',nargs = '?', help = "file path")
parser.add_argument('-l', nargs = '?', type = int, help = "word length", default = -1) # word length
parser.add_argument('-t', nargs = '?', type = int, help = "top number", default = 10) # top number
args = parser.parse_args()
# 输出单词长度5排名前十
# rewf test.txt -l 5 -t 10
# wordStatistics(args.filePath)
if ((args.s == None) and (args.filePath == None)):
redi = sys.stdin.read() # redirect
redirect(redi, top, leng)
pass
elif ((args.s == None) and (args.filePath != None)):
wordStatistics(args.filePath, args.t, args.l)
pass
elif ((args.s != None) and (args.filePath == None)):
wordStatistics(args.s, args.t, args.l)
pass
pass
命令行参数-l表示需要统计的单词长度,默认全部;-t表示需要输出的top单词数,默认为10个
测试结果