要点概论:
1.掌握数据结构的概念
2.了解算法
1.数据结构:
数据结构研究各种相关的数据信息如何表示,组织,存储与加工处理。数据结构中的关系指数据间的逻辑关系,与数据的物理存储无关,是从具体问题抽象出来的数学模型。
数据结构一般有线性结构和非线性结构。
1.1 线性结构
线性结构是指元素与元素之间是一对一的关系,一般有线性表,栈和队列等结构。
1.1.1 线性表
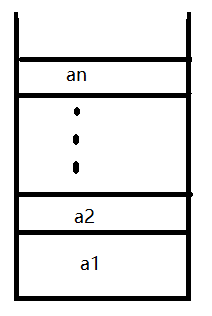
(a0,a1,......,an)(n > 0)如图所示:

1)存在唯一的“第一元素”a0
2)存在唯一的“最后元素”an
3)除最后元素an之外,各元素均有唯一的后继
4)除第一元素a0之外,各元素均有唯一的前驱
1.1.2 栈和队列
从数据结构角度讲,栈和队列均是操作受限的线性表,两者不同之处在于操作的特殊性(栈为LIFO,即后进先出:队列为FIFO,即先进先出)。
栈具有如下操作
1) 入栈(PUSH),最先插入的元素放在栈的底部
2) 出栈(POP),最后插入的元素最先出栈
队列指允许在线性表的一端进行插入,而在另一端进行删除。

1.2 非线性结构
非线性结构是至少在一个数据元素有两个或两个以上的直接后继(或直接前驱)的数据结构,一般有数和图两种。
1)在树形结构中,数据元素之间有着明显的层次关系,虽然每一层上的数据元素可能和下一层中多个元素相关,但只能和上一层中一个元素相关。例如人类的族谱。

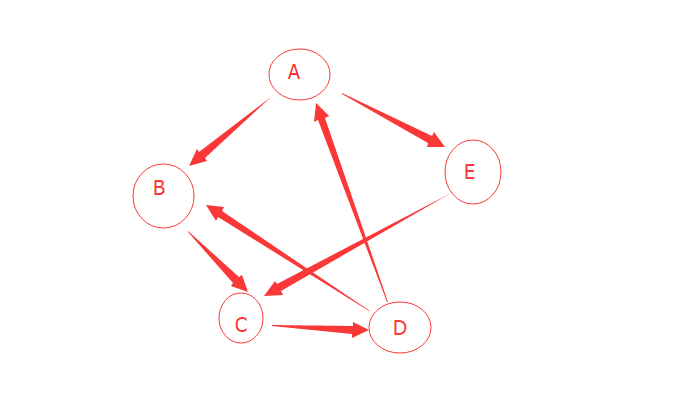
2 在图结构中,任意两个数据元素之间都可能相关,因此可用于描述多对多的关系。
2. 查找和排序
2.1 查找
1)顺序查找:
顺序查找又称线性查找,其查找方法为:从表的一端开始,向另一端逐个用给定值K与关键码进行比较,若找到,查找成功,若整个表检测完,仍未找到与K相同的关键码,则查找失败。
2)折半查找(二分查找算法)
折半查找的前提是线性表已经按照从小到打的顺序排列:
简单版:


l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] def func(l,aim): mid = (len(l)-1)//2 if l: if aim > l[mid]: func(l[mid+1:],aim) elif aim < l[mid]: func(l[:mid],aim) elif aim == l[mid]: print("bingo",mid) else: print('找不到') func(l,66) func(l,6)
升级版:
def search(num,l,start=None,end=None): start = start if start else 0 end = end if end else len(l) - 1 mid = (end - start)//2 + start if start > end: return None elif l[mid] > num : return search(num,l,start,mid-1) elif l[mid] < num: return search(num,l,mid+1,end) elif l[mid] == num: return mid
3)分块查找(研究中)
2.2 排序
排序是将一组无序的序列调整为有序的序列,排序的过程是一个逐步扩大有序子序列(对应的同步减小无序子序列)的过程:
基于不同的扩大有序子序列的方法,内部排序方法大致可分下列几种类型:插入类,交换类,选择类和归并类。
1)插入类:将无序子序列中的一个记录插入到有序子序列中,增加有序子序列的长度
1.基于顺序查找的插入类排序称为直接插入排序
2.基于折半查找的插入类排序称为折半插入排序
3.基于逐趟缩小增量的插入类排序称为希尔排序
2)交换类:交换类排序通过交换无序子序列中的元素从而得到其中关键字最小或最大的元素,并将它加入有序子序列中,以此方法增加有序子序列的长度。
交换类排序分为冒泡排序,快速排序等,这里简单说明一下冒泡排序:
冒泡排序是将待排列的数组元素看成是竖着排列的“气泡”,最小的元素为最小的“气泡”,较小的元素为较小的“气泡”。每一遍处理,就是自底而上检查一遍“气泡序列”,
并时刻注意两个相邻元素的顺序是否正确,如果发现两个相邻“气泡”的顺序不对,例如轻的“气泡”在重的“气泡”下面,则交换它们的位置。
一遍处理之后,最轻的“气泡”就浮到了最高位置;第二遍处理之后,次轻的“气泡”就浮到了次高位置。如此反复,共处理 n - 1 次,就可以完成“气泡”的有序排列。
3)选择类:选择类排序从无序子序列中选择关键字最小或最大的元素,并将它加入到有序子序列中,以此方法增加有序子序列的长度。
选择类排序分为简单选择排序,树形选择排序和堆排序。
4)归并类:归并类排序通过归并两个或两个以上的有序子序列,逐步增加有序子序列的长度。