统计分组函数
之前介绍了count()函数,他的作用是统计数据量,它是统计函数的一员,常用的统计函数有:
count()求数据量
sum()数学求和
avg()求平均值
max()求最大值
min()求最小值
测试:求公司所有员工的总薪资和每个员工的平均薪资
select avg(sal) 平均薪资, sum(sal) 总工资 from EMP
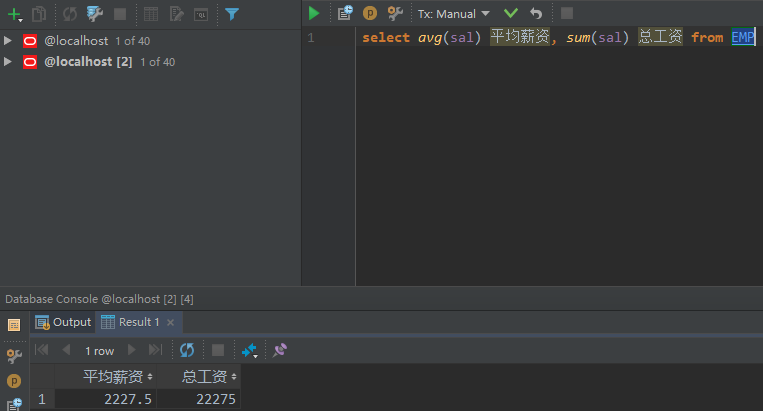
注意 count()函数的返回值永远是数字,其他的统计函数可能会存在返回值为null的情况 但是count()返回得最起码也是0(永远是确切数字)
分组查询
当数据重复出现的时候,我们在有分组的必要。例如一群人,按照年龄可以分为18以上和18以下,按性别可以分男女,即为只有数据重复的时候,才分组。
基本语法:
select ~ from ~ where ~ group by ~ order by~;
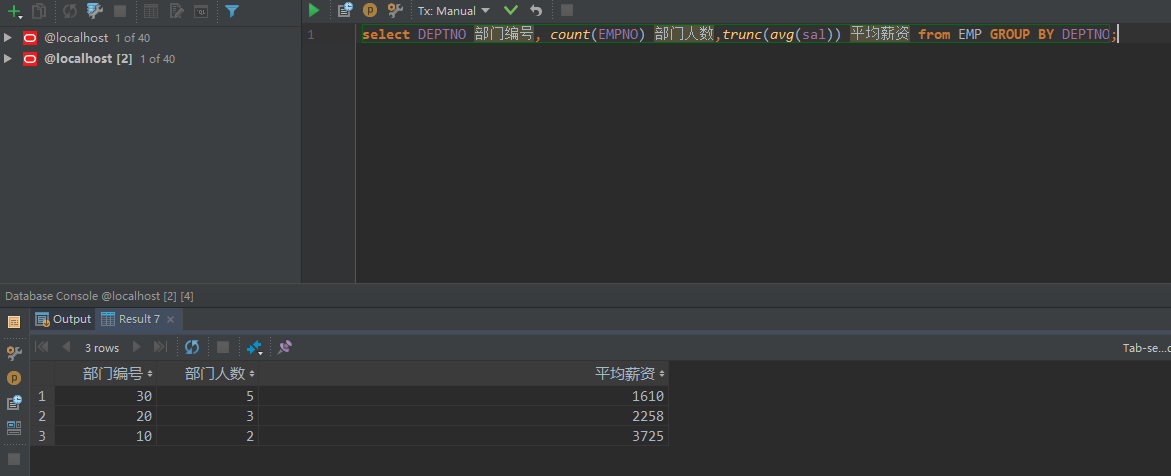
范例:按照部门编号分组,求出每个部门的人数,平均工资
select DEPTNO 部门编号, count(EMPNO) 部门人数,trunc(avg(sal)) 平均薪资 from EMP GROUP BY DEPTNO
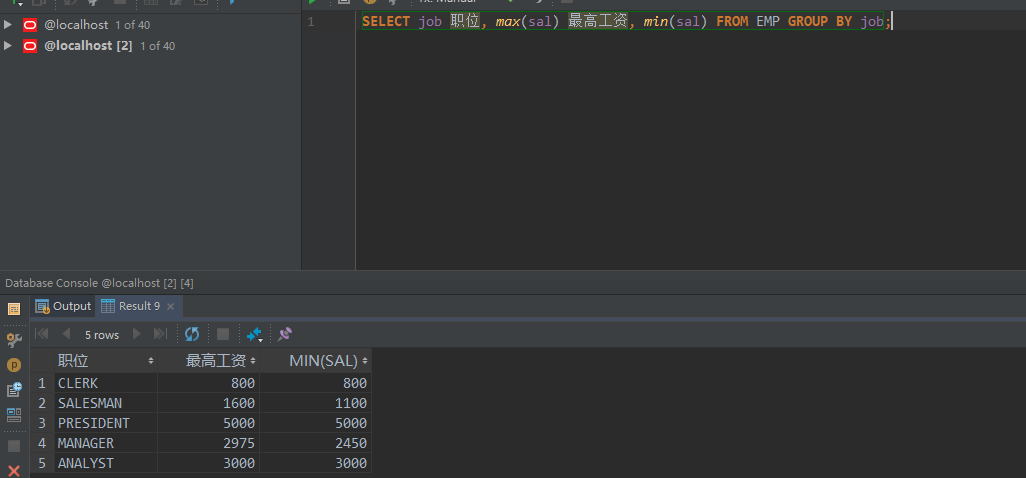
范例:按照职位分组,求出每个职位的最高和最低工资
SELECT job 职位, max(sal) 最高工资, min(sal) FROM EMP GROUP BY job;
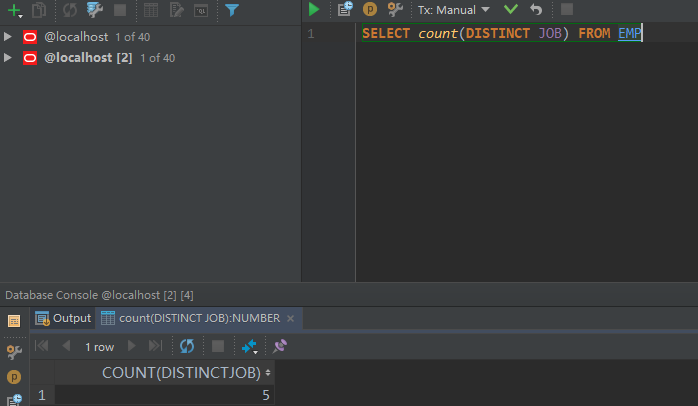
这里需要注意,分组函数可以不加group by单独使用,但是此时便不允许同时查询其他的属性,例如,我们查询一共有几种工作:
SELECT count(DISTINCT JOB) FROM EMP
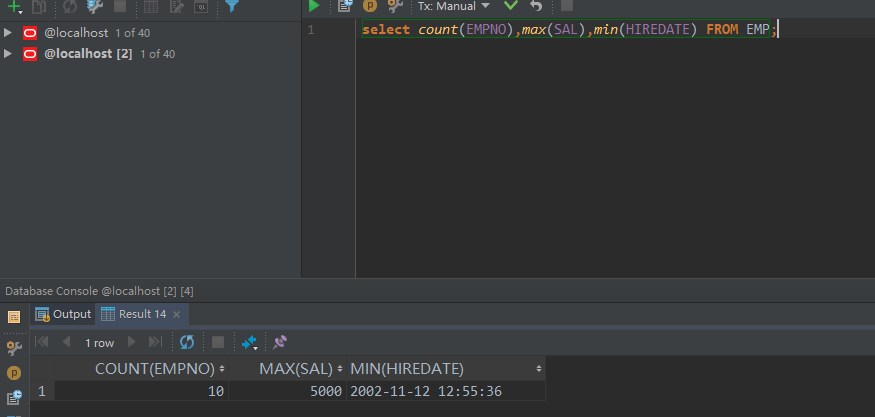
如果单纯只是多个分组函数的累计也是可以的,例如我们查询一共有多少员工,员工的最高工资,公司第一个员工入职时间:
select count(EMPNO),max(SAL),min(HIREDATE) FROM EMP;
但是如果我们要查询,员工的平均工资,所有员工的姓名,这时....
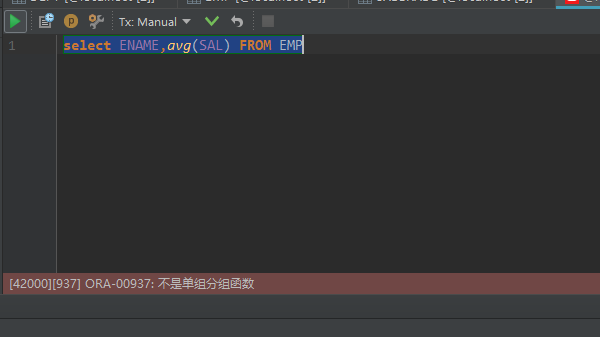
如果要使用分组函数,那么“select”后面只能追加分组条件的列以及分组函数。
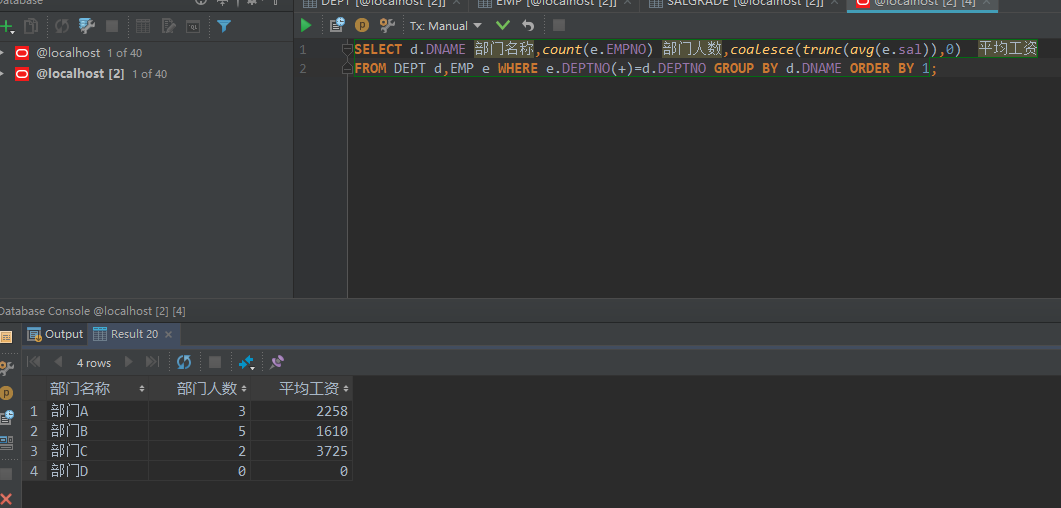
范例:查询出每个部门的名称、部门的人数、平均工资
SELECT d.DNAME 部门名称,count(e.EMPNO) 部门人数,coalesce(trunc(avg(e.sal)),0) 平均工资
FROM DEPT d,EMP e WHERE e.DEPTNO(+)=d.DEPTNO GROUP BY d.DNAME ORDER BY 1;
范例:要求显示每个部门的编号、名称、位置、部门的人数、平均工资
SELECT d.DEPTNO 部门编号,d.DNAME 部门名称,d.LOC 部门位置,count(e.EMPNO) 部门员工,coalesce(trunc(avg(e.SAL)),0) 平均工资
FROM EMP e, DEPT d WHERE e.DEPTNO(+)=d.DEPTNO GROUP BY d.DEPTNO,d.DNAME,d.LOC order by 1;
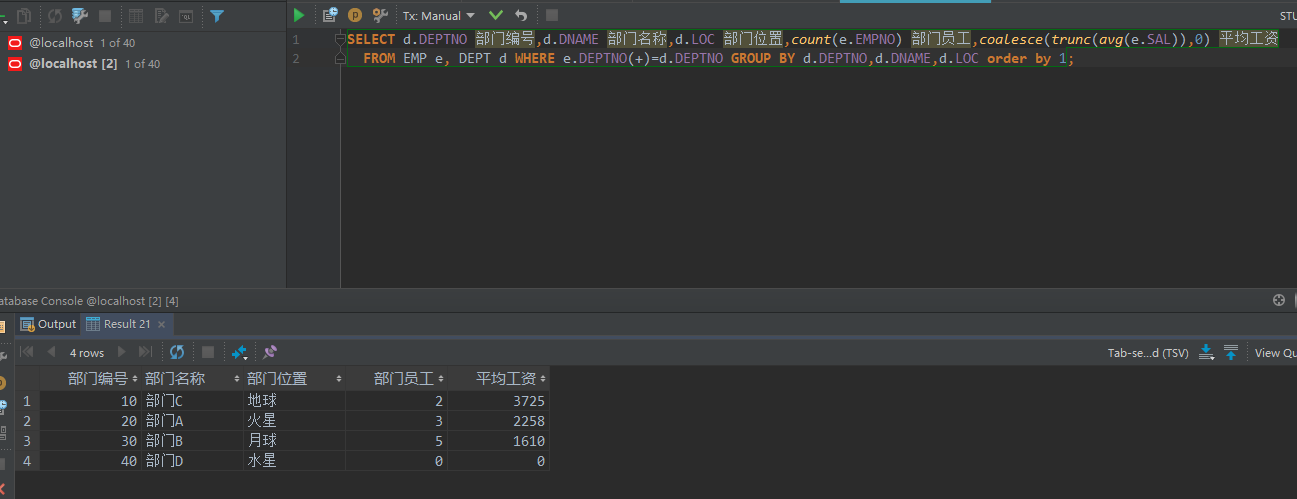
由此我们发现,分组条件可以不止一个列,其实 只要部门编号是10的,部门名称一定是C,部门位置一定是地球,由此我们可以把他们三个列看作一个整体进行分组操作