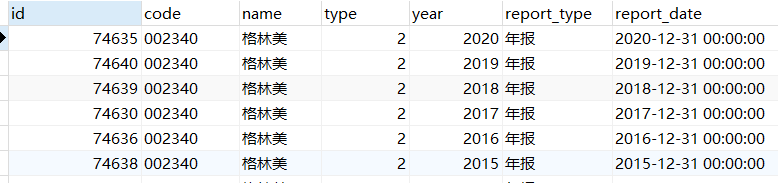最近在做一个多线程的爬虫程序,由于队列中有重复的数据,尽管程序中有判断不存在则插入,但由于多个线程并发,导致数据库中存在部分重复的数据。
程序中的bug已经修复,但重新爬一遍耗时耗力,于是就选择删除重复的数据,只保留一条有效数据
解决的思路就是根据确定其数据唯一的聚合字段进行分组,然后只保留一条有效数据
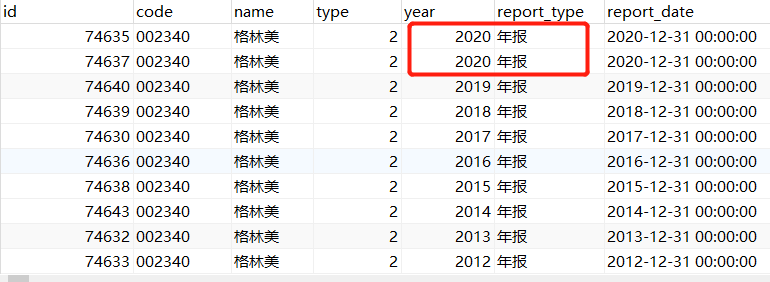
1.查询重复数据
select * FROM ZYZBBData WHERE (code,year,report_type) IN (SELECT code, year, report_type FROM (SELECT code, year, report_type FROM ZYZBBData GROUP BY code,year,report_type HAVING COUNT( * ) > 1) a)
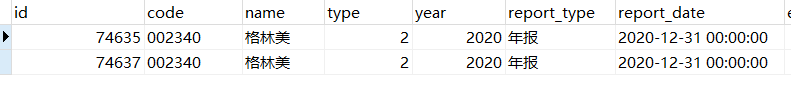
2.只保留Id最小的1条数据,过滤出要被删除的数据
select * FROM ZYZBBData WHERE (code,year,report_type) IN (SELECT code, year, report_type FROM (SELECT code, year, report_type FROM ZYZBBData GROUP BY code,year,report_type HAVING COUNT( * ) > 1) a) AND id NOT IN(SELECT id FROM (SELECT MIN(id) AS id FROM ZYZBBData GROUP BY code,year,report_type HAVING COUNT( * ) > 1) b)
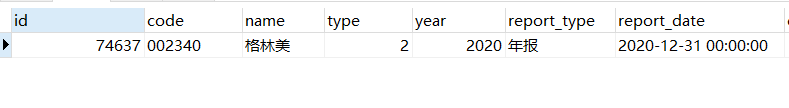
3.删除重复的数据
DELETE FROM ZYZBBData WHERE (code,year,report_type) IN (SELECT code, year, report_type FROM (SELECT code, year, report_type FROM ZYZBBData GROUP BY code,year,report_type HAVING COUNT( * ) > 1) a) AND id NOT IN(SELECT id FROM (SELECT MIN(id) AS id FROM ZYZBBData GROUP BY code,year,report_type HAVING COUNT( * ) > 1) b)
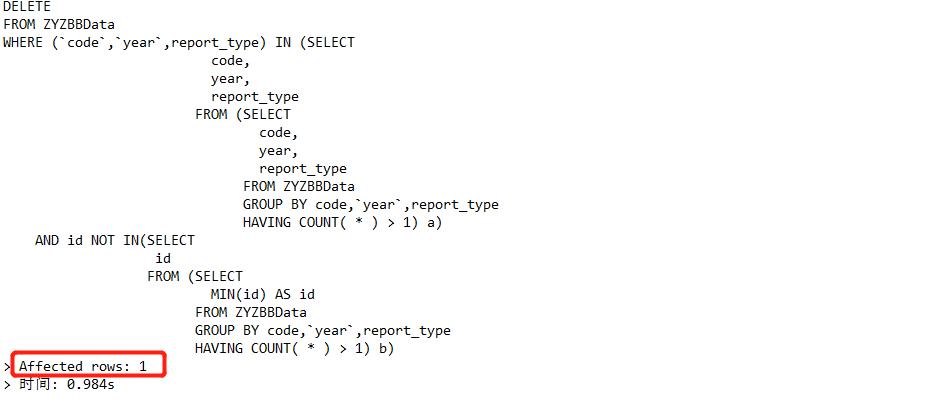
数据正常