数据源
数据来源
User Behavior Data from Taobao for Recommendation
UserBehavior是阿里巴巴提供的一个淘宝用户行为数据集,用于隐式反馈推荐问题的研究。
该数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:

数据集大小说明
| 维度 | 数量 |
|---|---|
| 用户数量 | 987,994 |
| 商品数量 | 4,162,024 |
| 商品类目数量 | 9,439 |
| 所有行为数量 | 100,150,807 |
数据获取及处理
分析工具
分析工具:Python + MySQL + Tableau
首先使用 Python 截取 300 万条淘宝用户行为数据,接下来在 MySQL 环境中使用 SQL 语句对数据进行清洗和查询,并结合 Tableau 绘制可视化图表。
获取数据
使用 Python 导数
先将一亿多条数据全部加载到 Python 中。为了方便分析以及考虑执行效率,使用 Python 将数据顺序打乱后,随机获取 300 万条数据,并将数据存入 MySQL 数据库中。
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
# 使用pandas迭代获取数据
df = pd.read_csv('C:\Users\Qingmu\Desktop\UserBehavior.csv',header=None,iterator=True,encoding='utf-8')
head_data = df.get_chunk(100150807) # 读入全部数据
# 加入列名
head_data.columns = ['user_id','items_id','category_id','behavior','timestamp']
# 打乱数据框的顺序
head_data = head_data.reindex(np.random.permutation(head_data.index))
# 截取300万条数据来做分析
userbehavior = head_data[:3000000]
# engine = create_engine('dialect+driver://username:password@host:port/database')
# dialect -- 数据库类型、driver -- 数据库驱动选择、username -- 数据库用户名、password -- 用户密码
# host 服务器地址、port 端口、database 数据库
engine = create_engine("mysql+pymysql://root:123456@localhost:3306/taobao?charset=utf8")
userbehavior.to_sql(name='userbehavior', con=engine, if_exists='append',index=False) # index_label='id'
#root是用户名,123456是密码,localhost是指本地服务器,port 端口是3306,taobao是在mysql上创建的表。
数据清洗
数据类型修改
导入的数据中用户ID、商品ID、商品所属类目ID都变成了整型,需要转换为字符串类型。
#这一步开始在sql上进行
ALTER TABLE userbehavior MODIFY user_id VARCHAR(8);
ALTER TABLE userbehavior MODIFY items_id VARCHAR(8);
ALTER TABLE userbehavior MODIFY category_id VARCHAR(8);
重复值检查
该数据表中存在很多用户id一样的记录,但不影响分析,因为一个用户可能在同一时段或不同时段出现重复浏览商品或购买商品等的行为,因此这里就不对此部分的数据进行处理。
一致性处理
由于 timestamp 列为时间戳格式,我们需要使用 from_unixtime()函数将数据转换为日期格式,为了方便后期的分析,可以添加一列数据,将时间戳格式转换为小时列。
# 添加两个字段
ALTER TABLE userbehavior ADD DATE VARCHAR(10);
ALTER TABLE userbehavior ADD HOUR VARCHAR(4);
# 将时间戳转换为日期格式
UPDATE userbehavior
SET DATE=FROM_UNIXTIME(TIMESTAMP,'%Y-%m-%d');
# 将时间戳转换为小时格式
UPDATE userbehavior
SET HOUR=SUBSTR(FROM_UNIXTIME(TIMESTAMP,'%Y-%m-%d-%H'),-2);
# 删除timestamp字段
ALTER TABLE userbehavior
DROP TIMESTAMP;
数据过滤
通过按日期进行排序,可以发现,数据集中存在很多异常时间,故需要将这部分时间剔除掉。
SELECT DATE
FROM userbehavior
WHERE DATE IS NOT NULL
GROUP BY DATE
ORDER BY DATE;

因为数据是 2017 年 11 月 25 日- 2017 年 12 月 3 日之间的数据,所以我们需要将异常时间的数据清洗掉。这里采用的是新创建一个 user 表,将查询得到的数据插入新表中。
CREATE TABLE user
SELECT * FROM userbehavior
WHERE date BETWEEN '2017-11-25' AND '2017-12-03';
#这里已经代表date不为空,故不再加is not null
基于AARRR(海盗模型)框架的产品分析
AARRR是Acquisition、Activation、Retention、Revenue、Referral,这个五个单词的缩写,分别对应产品生命周期中的五个阶段,简称获客、促活、留存、创收和传播。由于数据集的限制,只进行促活、留存、创收这三个阶段的产品分析。
促活(Activation)
PV、UV和平均访问深度
总访问量(Page View,简称 PV),指用户访问页面的总数,用户每访问一个网页,就算一个访问量,同一个页面刷新一次也算一个访问;
访客数(Unique Visitor,简称 UV),一台电脑为一个独立访客;
平均访问深度,也称为平均访问量,指用户每次浏览的页面的平均值,即平均每个 UV 访问了多少个 PV。
SELECT a.pv AS '总访问量', a.uv AS '总访问用户数', a.pv/a.uv AS '平均访问深度'
FROM(
SELECT COUNT(behavior) AS 'pv',(SELECT COUNT(DISTINCT user_id) FROM USER) AS 'uv'
FROM USER
WHERE behavior='pv'
) AS a;
| 总访问量 | 总访问用户数 | 平均访问深度 |
|---|---|---|
| 2685879 | 802417 | 3.34 |
从整体数据来看,淘宝在这一周内的总访问次数为2685879次,总访问用户数为802417人,平均访问深度为3.34,即每个人一周内大概会访问3个页面。
日均PV和日均UV
日均PV:以天为单位展示商品的浏览量
日均UV:以天为单位展示用户数的变化趋势
SELECT date,
SUM(IF(behavior='pv',1,0)) AS 'PV',
COUNT(DISTINCT user_id) AS 'UV'
FROM user
GROUP BY date
ORDER BY date;
#求pv也可以这样求,但是这个不好与uv合并,若有更好方法麻烦评论一下
select count(behavior)
from user
where behavior='pv'
group by date
order by date;

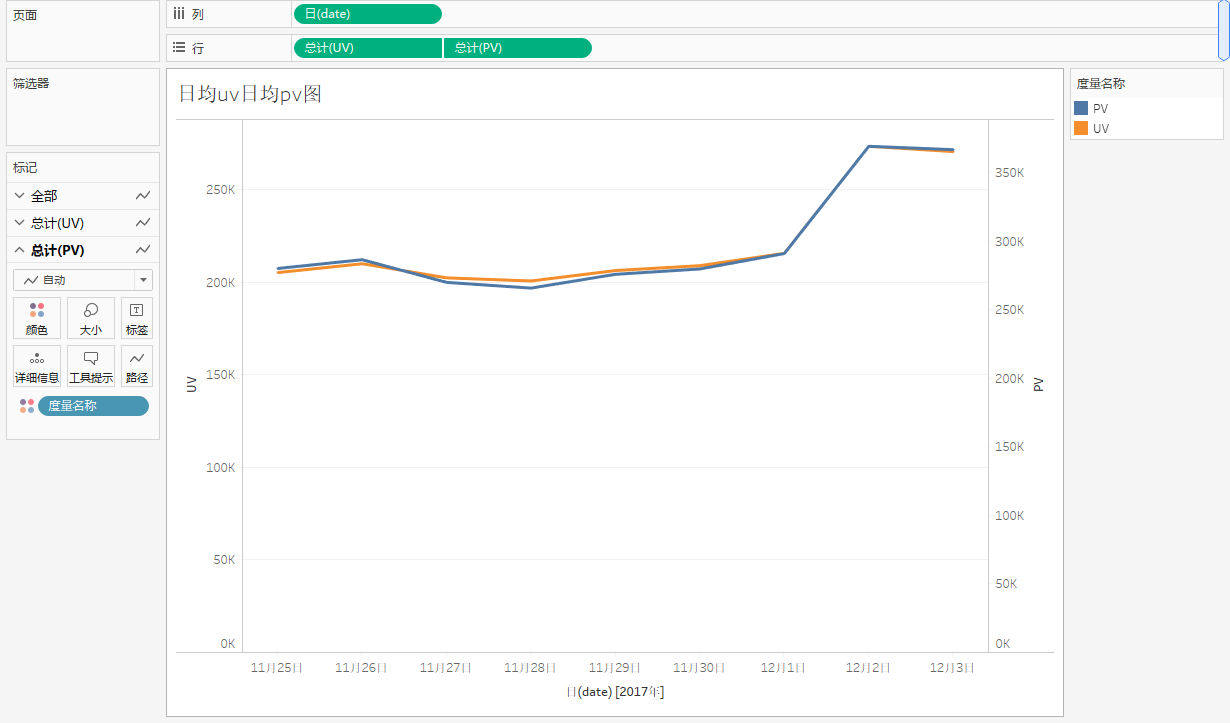
从上图可以看出,PV、UV 这两个指标的变化趋势几乎保持一致。在2017年11月25日-12月 1日之间,都是较为稳定的,而在2017年12月2日这天开始,PV 和 UV 都不断增加。这有可能是由于12月2日接近双十二,有双十二预热活动导致访问量增加。
这在当中还可以初步看出非工作日(11 月 25 日和 11 月 26 日)对于访问量没有明显的提升。
时均PV和时均UV
以小时为单位展示商品的浏览量和用户数的变化趋势
SELECT hour,
SUM(IF(behavior='pv',1,0)) AS 'PV',
COUNT(DISTINCT user_id) AS 'UV'
FROM `user`
GROUP BY hour
ORDER BY hour

从上图中可看出,时均uv和时均pv的整体趋势是相近的。从0点到4点这段时间趋势都是向下,这也符合人们在这一时间段休息的生活习惯。从6点开始uv和pv逐渐上升,在10点-16点期间也有上下浮动。最为突出的是18点-21点uv和pv急速上升,21点达到顶峰。
从中可以得出结论:用户活跃程度最高是在19点-23点这段时间,这段时间是黄金时段,淘宝应在这段时间加大营销力度。
制图问题
- 若出现这种情况,是因为轴没同步,右击右边的轴,同步轴即可。

- 注意:当轴数不为数字(十进制)时,无法进行同步轴
- 参考:《使用度量值作为轴时无法同步轴》
日新增用户数和新用户占比
日新增用户是指客户端首次访问页面的用户数,这里用最小日期当做用户首次访问APP的日期,将新增用户数和总用户数对比就是新用户占比。
CREATE VIEW re_view AS #视图
SELECT user_id,date,MIN(date) OVER(PARTITION BY user_id) AS 'first_date'#开窗函数只能在mysql8以上才能使用
FROM user;
开窗函数 over ( partition by)介绍及其与group by区别
#以下的代码在sql中运行后可在Tableau中作图(不加分号;)
SELECT a.date AS '日期',
a.total AS '总访客数',
b.new AS '日新增访客数',
ROUND((b.new/a.total),2) AS '新访客占比' #round(,2)返回两位数
FROM(
SELECT date,COUNT(DISTINCT user_id) AS 'total'
FROM user
GROUP BY date
) AS a
LEFT JOIN(
SELECT date,COUNT(DISTINCT user_id) AS 'new'
FROM re_view
WHERE date=first_date
GROUP BY date
) AS b
ON a.date=b.date
GROUP BY a.date
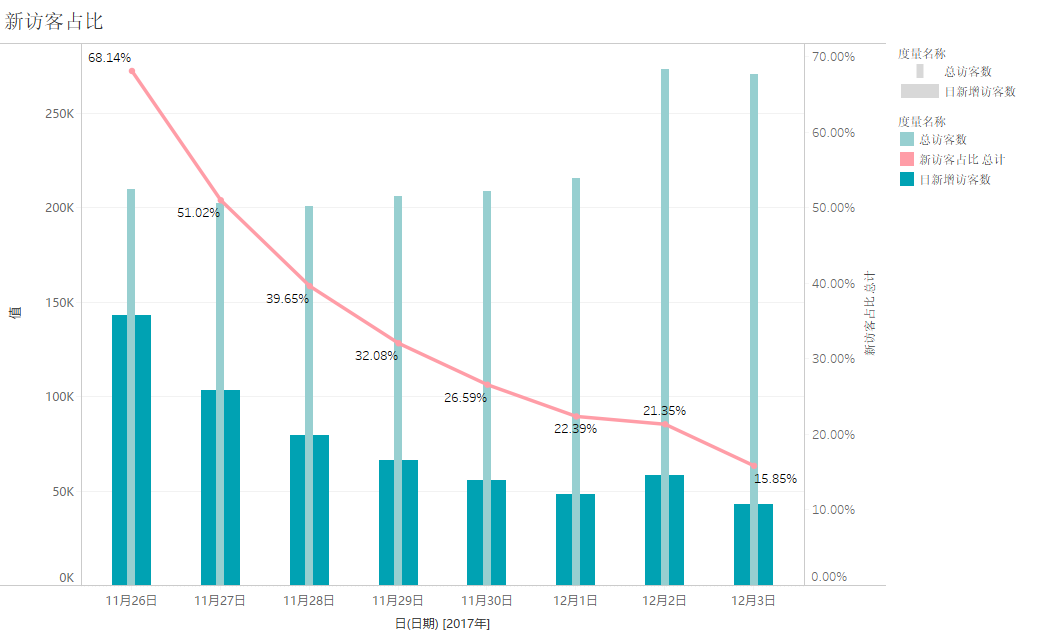
从上图可以看出,11月26日达到了将近68.14%的新访客占比,但这应该是受到双十一活动的影响。随着活动结束,日新增用户数是不断在下降,在12月2日出现轻微的上升,但日新增用户数占比是在不断下降的,表明这段时间的日活跃用户大部分来自留存用户。
跳出率
跳出率,也叫跳失率,就是只浏览了一个页面就离开的访问次数除以该页面的全部访问次数,可以反映页面内容受欢迎的程度,跳失率越大,页面内容越需要调整。
SELECT COUNT(a.ct) AS '只浏览一次的访问总数',
(SELECT COUNT(behavior) FROM user WHERE behavior='pv') AS '总访问次数',
CONCAT(ROUND((COUNT(a.ct)/(SELECT COUNT(behavior) FROM user WHERE behavior='pv'))*100,2),'%') AS '跳出率'
FROM
(SELECT user_id,COUNT(behavior) AS ct
FROM user
WHERE behavior='pv'
GROUP BY user_id
HAVING ct<=1) AS a;
| 只浏览一次的访问总数 | 总访问次数 | 跳出率 |
|---|---|---|
| 212108 | 2685879 | 7.90% |
从上图可以看出,用户跳失率为7.88%,相对于淘宝整体而言,该用户跳失率是较低的。但该指标应用到不同的店铺页面上会更为具体有效。
留存(Retention)
AIPL模型
AIP转化漏斗
阿里推出了一个可以把品牌在阿里系的人群资产定量化运营的模型,这个模型叫做:A-I-P-L。
- A(Awareness),品牌认知人群。包括被品牌广告触达和品类词搜索的人;
- I(Interest),品牌兴趣人群。包括广告点击、浏览品牌/店铺主页、参与品牌互动、浏览产品详情页、品牌词搜索、领取试用、订阅/关注/入会、加购收藏的人;
- P(Purchase),品牌购买人群,指购买过品牌商品的人;
- L(Loyalty),品牌忠诚人群,包括复购、评论、分享的人。
AIPL中的“L”为会员复购行为,在后面单独计算。这里仅对A、I、P 阶段的行为进行统计

SELECT behavior AS '用户行为类型',
COUNT(behavior) AS '用户行为次数'
FROM `user`
GROUP BY behavior
ORDER BY 用户行为次数 DESC

从用户的购买行为转化漏斗图来看,用户在浏览商品后,进入到加入购物车或收藏商品环节的比例为9.38%,而在加入购物环节/收藏商品后进入购买商品的转化率为24.04%。相对于第二环节来说,第一环节的转化率较低,这表明用户在浏览商品后,较少选择加入购物车或收藏商品,部分用户对该商品并不是很满意,或者没有收藏和加购的习惯,一方面需要提高商品的吸引力,或从商品图片或从标题、质量和排版等方面优化。另一方面是有意识引导消费者加入收藏或购物车从而提高转化率。
L(Loyalty):复购率
复购率,是指在某段时间内产生二次或二次以上购买的用户占购买用户的总数。
SELECT COUNT(DISTINCT a.user_id) AS '总购买用户数',
SUM(IF(a.ct>=2,1,0)) AS '购买两次以上的用户数',
CONCAT(ROUND((SUM(IF(a.ct>=2,1,0))/COUNT(DISTINCT a.user_id))*100,2),'%') AS '复购率'
FROM
(SELECT user_id,COUNT(behavior) AS 'ct'
FROM user
WHERE behavior='buy'
GROUP BY user_id) AS a
| 总购买用户数 | 购买两次以上的用户数 | 复购率 |
|---|---|---|
| 56648 | 3548 | 6.26% |
从上表中可看出,在2017年11月25日至2017年12月3日期间的复购率为6.26%。这是体现上文提到的用户黏性的指标之一,如制定了增加用户黏性的策略,可观察该复购率指标从而判断策略是否起效。
以下分析以天为时间段的复购率:
SELECT COUNT(DISTINCT a.user_id) AS '总购买用户数',
SUM(IF(a.ct>=2,1,0)) AS '购买两次以上的用户数',
ROUND((SUM(IF(a.ct>=2,1,0))/COUNT(DISTINCT a.user_id)),4) AS '复购率',
DATE
FROM
(SELECT user_id,COUNT(behavior) AS 'ct',DATE
FROM USER
WHERE behavior='buy'
GROUP BY user_id
) AS a
GROUP BY DATE;
在这里要理解mysql的执行顺序:
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left table>
(3) <join_type> JOIN <right_talbe>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
FORM: 对FROM的左边的表和右边的表计算笛卡尔积。产生虚表VT1
ON: 对虚表VT1进行ON筛选,只有那些符合<join-condition>的行才会被记录在虚表VT2中。
JOIN: 如果指定了OUTER JOIN(比如left join、 right join),那么保留表中未匹配的行就会作为外部行添加到虚拟表VT2中,产生虚拟表VT3, rug from子句中包含两个以上的表的话,那么就会对上一个join连接产生的结果VT3和下一个表重复执行步骤1~3这三个步骤,一直到处理完所有的表为止。
WHERE: 对虚拟表VT3进行WHERE条件过滤。只有符合<where-condition>的记录才会被插入到虚拟表VT4中。
GROUP BY: 根据group by子句中的列,对VT4中的记录进行分组操作,产生VT5.
CUBE | ROLLUP: 对表VT5进行cube或者rollup操作,产生表VT6.
HAVING: 对虚拟表VT6应用having过滤,只有符合<having-condition>的记录才会被 插入到虚拟表VT7中。
SELECT: 执行select操作,选择指定的列,插入到虚拟表VT8中。
DISTINCT: 对VT8中的记录进行去重。产生虚拟表VT9.
ORDER BY: 将虚拟表VT9中的记录按照<order_by_list>进行排序操作,产生虚拟表VT10.
LIMIT:取出指定行的记录,产生虚拟表VT11, 并将结果返回。
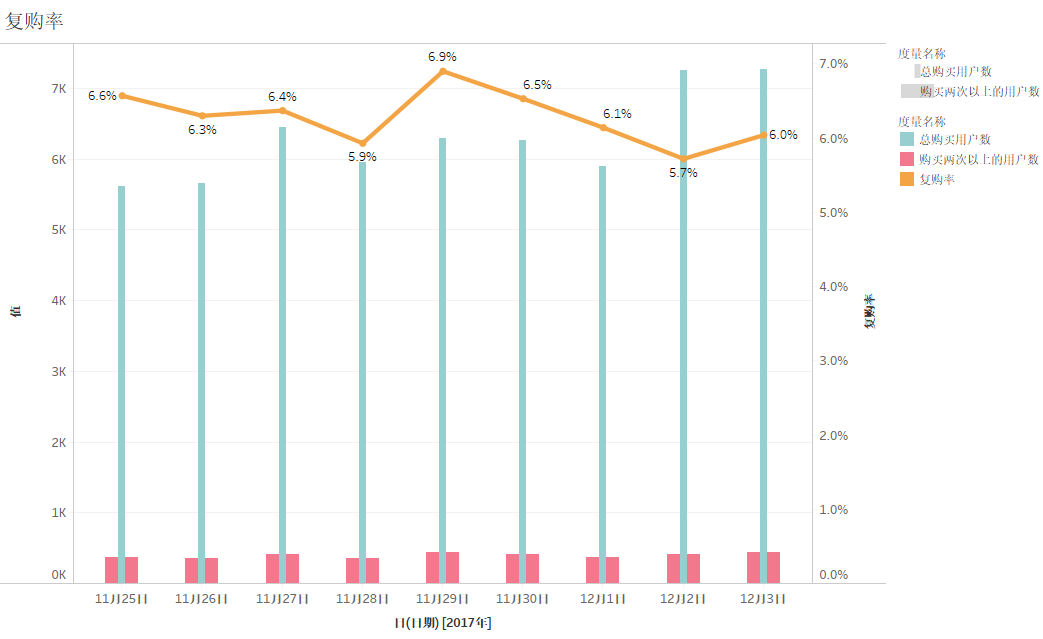
从上图中可看出,每天的复购率都较为稳定,趋近于6%左右。但是从11月29日到12月2日的复购率持续下降,这一反常趋势需要找出其原因,避免复购率继续下降。此处限于数据集指标有限,未能进一步分析。
日均转化率分析
select DATE,round(加入购物车量/访问量,4) as '加购转化率',round(购买量/加入购物车量,4) as '下单转化率',round(购买量/访问量,4) as '点击转化率'
from (SELECT date,
SUM(IF(behavior='pv',1,0)) AS '访问量',
SUM(IF(behavior='fav',1,0)) AS '收藏量',
SUM(IF(behavior='cart',1,0)) AS '加入购物车量',
SUM(IF(behavior='buy',1,0)) AS '购买量'
FROM user
GROUP BY date
ORDER BY date)as a;
#需要注意的是,在使用子查询的表的时候需要加别名,即使a不用上也需要加
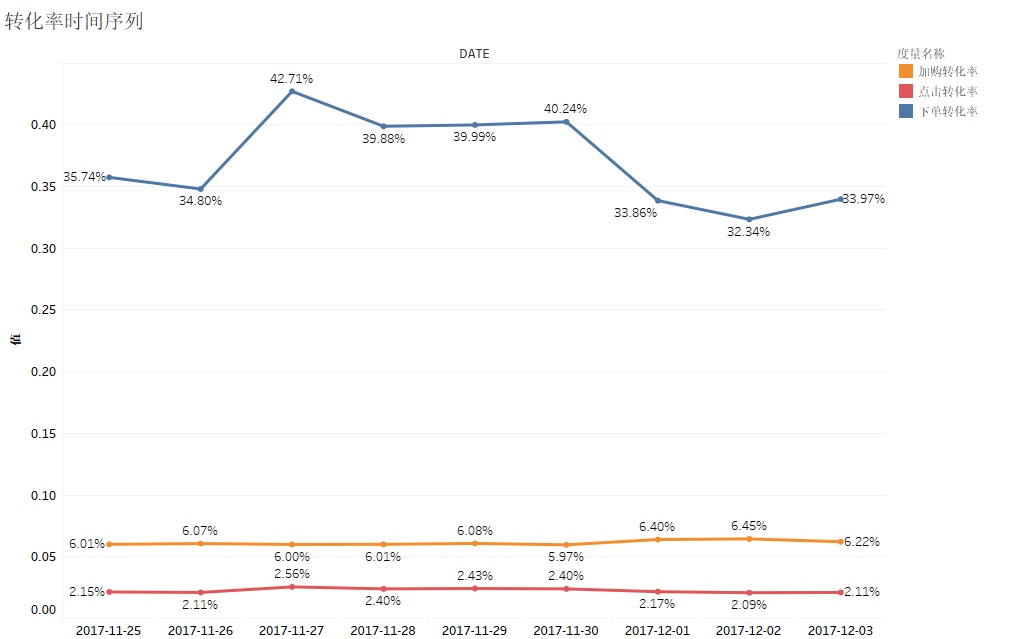
从上图中可看出,加购转化率和点击转化率都较为平稳,基本趋向于一个数值轻微波动,而下单转化率波动较大,并且12月1日开始转化率开始急速下降,需要寻找出下降的原因,比如比较不同渠道的下单转化率、分析用户画像等方法。从图中也可以看出下单转化率远超于加购转化率和点击转化率,因此需要提升加购转化率,进一步提升下单转化率。
创收(Revenue)
每日购买情况
由于数据集缺失金额数据,主要从每日访问用户数,每日购买次数,每日购买人数,每日购买人数比率,每日人均购买次数这几个指标来分析。
SELECT
a.*
,b.每日购买人数
,b.每日购买人数 / a.每日访问用户数 AS '每日购买人数比率'
,ROUND(a.每日购买次数 / b.每日购买人数, 2) AS '每日人均购买次数'
FROM (
SELECT `date`
,COUNT(DISTINCT user_id) AS '每日访问用户数'
,SUM(IF(behavior='buy',1,0)) AS '每日购买次数'
FROM USER
GROUP BY `date`
) a
LEFT JOIN (
SELECT `date`
,COUNT(DISTINCT user_id) AS '每日购买人数'
FROM USER
WHERE behavior = 'buy'
GROUP BY `date`
) b
ON a.date = b.date;
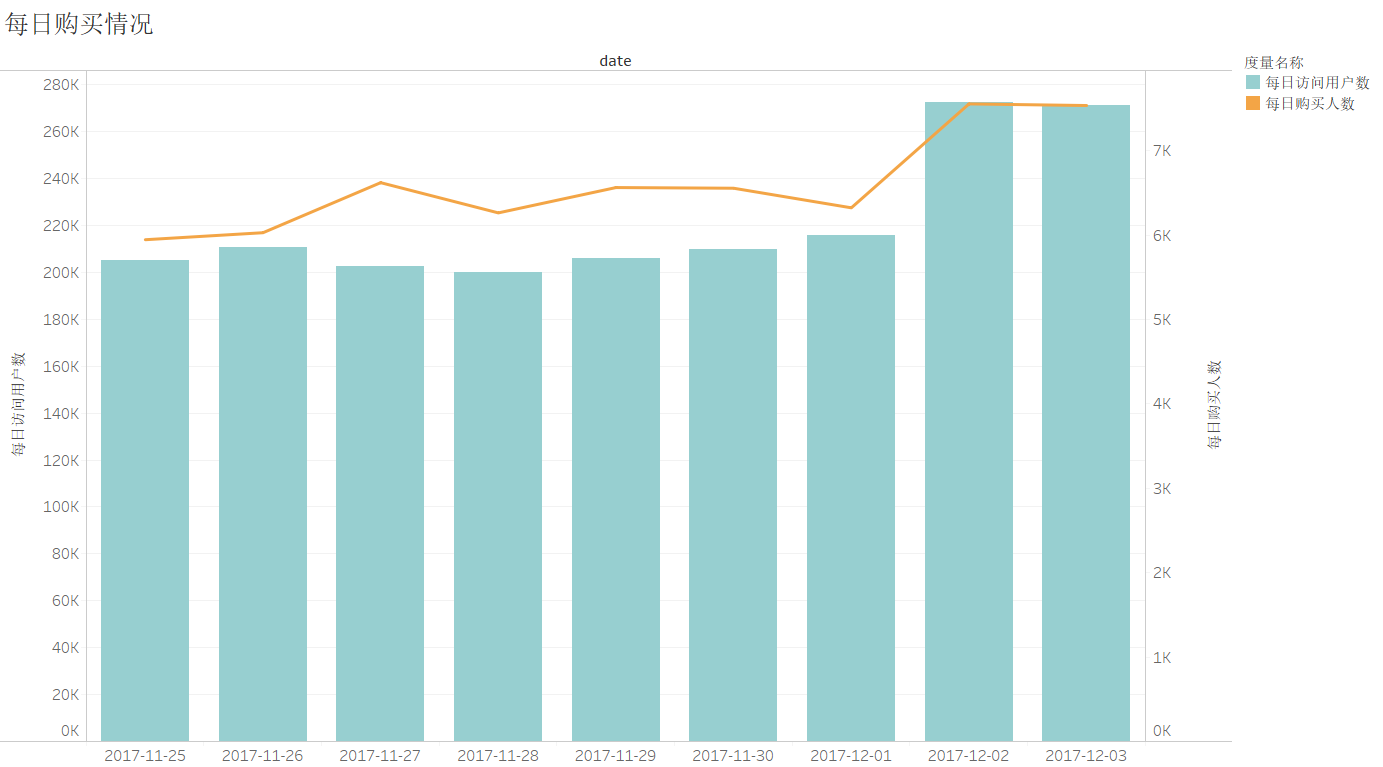

如上图所示,每日购买人数比例大致稳定在3%左右,2月2日和12月3日访问人数大幅增加,购买人数也随之增加,但是购买人数比例却有所下降,访问人数和购买人数的上升又可能是由于双十二的预热环节,而购买人数比例的下降也同样是由于预热环节,人们倾向于在双十二活动中进行购买活动。
基于商品维度分析用户的行为习惯
商品浏览量最高的前 10 种商品类目(热搜商品)
SELECT category_id,COUNT(behavior) AS '访问量'
FROM user
WHERE behavior='pv'
GROUP BY category_id
ORDER BY 访问量 DESC
LIMIT 10;
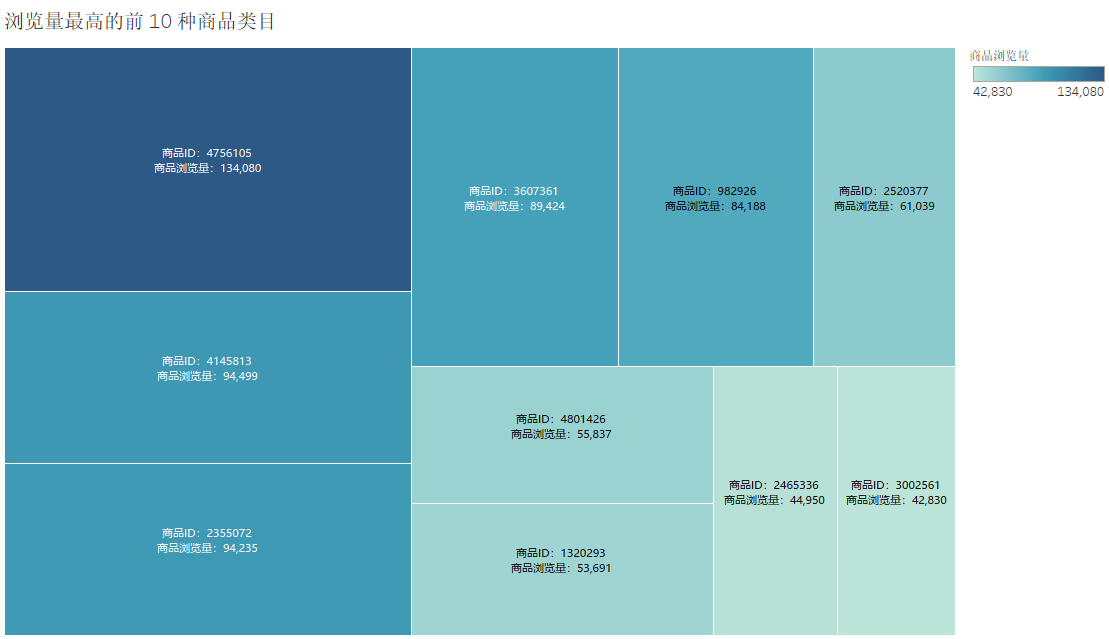
从图中可看出商品ID为4756105的商品浏览量最大,有134080次浏览量。其次是商品ID为4145813和商品ID为2355072的商品。浏览量高可能代表其商品质量、图片、标题和宣传等比较符合消费者需求。但其购买量却未必高。因此下面进行购买量分析。
商品购买量最高的前 10 种商品类目(热购商品)
SELECT category_id,COUNT(behavior) AS '商品购买量'
FROM user
WHERE behavior='buy'
GROUP BY category_id
ORDER BY 商品购买量 DESC
LIMIT 10;

从上图中可以看出排名前三的分别是商品ID为1464116、2735466和4145813的商品,与上文的浏览量最高的前三的商品对比,只有商品ID为4145813的商品都位于前三,可看出浏览量最多并不代表购买量最多。热搜商品未能成功吸引消费者购买,浏览量未能很好地转化为销量。
因此下文结合漏斗模型分析浏览量前三的商品在哪些环节下出现了差异,以便针对性地调整。
转化率对比分析
select category_id,round((加入购物车量+收藏量)/访问量,4) as '加购转化率',round(购买量/(加入购物车量+收藏量),4) as '下单转化率',round(购买量/访问量,4) as '点击转化率'
from
(SELECT
SUM(IF(behavior='pv',1,0)) AS '访问量',
SUM(IF(behavior='fav',1,0)) AS '收藏量',
SUM(IF(behavior='cart',1,0)) AS '加入购物车量',
SUM(IF(behavior='buy',1,0)) AS '购买量',
category_id
FROM user
GROUP BY category_id
ORDER BY 访问量 desc) as a
limit 3;
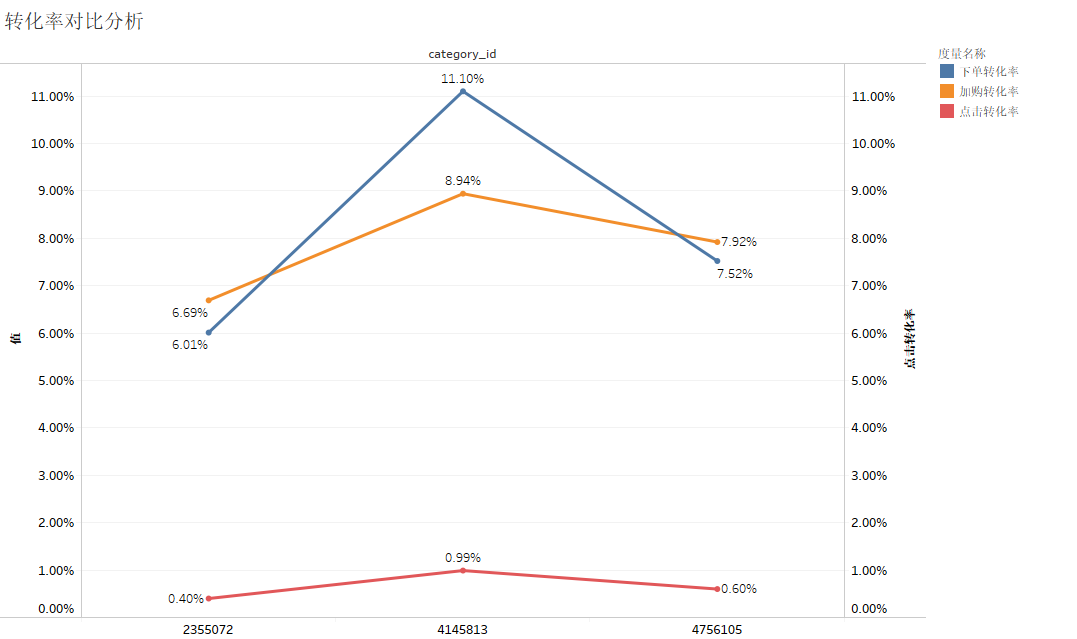
从上图中可以看出,三个商品的加购转化率相差并不悬殊,但是下单转化率上商品ID为4145813的商品很明显远远超过了其余两个商品,可见商品ID为4145813的商品之所以能够在商品浏览量和商品购买量中都位于前三,主要在于其下单转化率较高,而其余两个商品若想提高购买量,应提高其下单转化率。
基于 RFM 模型进行用户分层
RFM 模型是衡量客户价值和客户创利能力的重要工具,是按照 R(Recency-近度)、F(Frequency-频度)、M(Monetary-额度)三个维度进行细分客户群体。
近度R(Recency):R代表客户最近的活跃时间距离数据采集点的时间距离。R越大,表示客户越久未发生交易,R越小,表示客户越近有交易发生。R越大则客户越困难会“沉睡”,流失的可能性越大。在这部分客户中,可能有些优质客户,值得公司通过一定的营销手段进行激活。
频度F(Frequency):F代表客户过去某段时间内(如一年、半年、30天等)的活跃频率。F越大,则表示客户同本公司的交易越频繁,不仅仅给公司带来人气,也带来稳定的现金流,是非常忠诚的客户;F越小,则表示客户不够活跃,且可能是竞争对手的常客。针对F较小、且消费额较大的客户,需要推出一定的竞争策略,将这批客户从竞争对手中争取过来。
额度M(Monetary):表示客户每次消费金额的多少。可以用最近一次消费金额,也可以用过去的平均消费金额,根据分析的目的不同,可以有不同的标识方法。一般来讲,单次交易金额较大的客户,支付能力强,价格敏感度低,是较为优质的客户,而每次交易金额很小的客户,可能在支付能力和支付意愿上较低。当然,也不算绝对的。
通过RFM分析将客户群体划分成一般保持客户、一般发展客户、一般价值客户、一般挽留客户、重要保持客户、重要发展价值客户、要挽留客户等八个级别。
| 类别 | 最近一次消费时间间隔(R) | 最近一段时间消费频率(F) | 最近一段时间消费金额(M) | 运营策略 |
|---|---|---|---|---|
| 重要价值用户 | 高 | 高 | 高 | 保持现状 |
| 重要发展用户 | 高 | 低 | 高 | 刺激消费频率 |
| 重要保持用户 | 低 | 高 | 高 | 要留住用户,防止流失 |
| 重要挽留用户 | 低 | 低 | 高 | 留存客户并刺激消费频率 |
| 一般价值用户 | 高 | 高 | 低 | 忠诚用户,要刺激消费力度 |
| 一般发展用户 | 高 | 低 | 低 | 刺激消费频率和力度 |
| 一般保持用户 | 低 | 高 | 低 | 留存客户并刺激消费 |
| 一般挽留用户 | 低 | 低 | 低 | 各方面刺激 |
一般发展用户不应该包含新注册用户,因为新用户可能最近注册,但是购买频率和购买金额还是处于比较低的,做分析时应该把这部分用户过滤掉。
由于数据集没有给出用户的购买金额,故这里按照 RFM 模型的计算流程,仅采用 R 和 F来对用户群体进行细分。
计算 R、F 值
近度R的计算
由于该数据集是2017年11月25日至2017年12月3日之间的数据集,时间相差较远,这里的近度R将使用这个数据数据集最大的时间减去用户最近一次购买的时间。
频度 F的计算
针对每位用户在这段时间的购买频率进行计算
create or replace view RF_model AS #创建视图,方便后续的分析
SELECT user_id,
if(behavior='buy',DATEDIFF('2017-12-03',MAX(date)),9) AS 'R',
sum(if(behavior='buy',1,0)) AS 'F'
FROM user
GROUP BY user_id
ORDER BY user_id;
根据业务标准,给 R、F 打分
R、F打分标准随着不同的业务有所不同,这里由于数据集的有限只能进行粗略的打分。
计算R范围
select R
from RF_model
group by R
order by R;
这里计算得出R的范围为:0-9,9代表就是这段时间段从未购买过。
计算F范围
select F
from RF_model
group by F
order by F;
这里计算得出F的范围为:0-6
制定打分表
通过计算可得出,R的范围是0-9,F的范围是0-6。根据这两个指标制定一个粗略的打分表。
| 分值 | 最近一次消费时间间隔(R) | 这段时间的消费频率(F) |
|---|---|---|
| 0 | 9天 | 0次 |
| 1 | [7,8]天 | 1次 |
| 2 | [5,6]天,含天 | 2次 |
| 3 | [3,4] | 3次 |
| 4 | [1,2] | 4次 |
| 5 | 0天 | [5,6]次 |
根据打分表打分:
CREATE VIEW RF_score AS
SELECT user_id,
CASE WHEN R = 0 THEN 5
WHEN R BETWEEN 1 AND 2 THEN 4
WHEN R BETWEEN 3 AND 4 THEN 3
WHEN R BETWEEN 5 AND 6 THEN 2
WHEN R BETWEEN 7 AND 8 THEN 1
ELSE 0 END AS 'R_score',
CASE WHEN F =0 THEN 0
WHEN F= 1 THEN 1
WHEN F =2 THEN 2
WHEN F =3 THEN 3
WHEN F =4 THEN 4
ELSE 5 END AS 'F_score'
FROM RF_model
ORDER BY user_id
计算 R、F 的平均值和标签
CREATE OR REPLACE VIEW RF_class AS #replace便于更改视图内容
SELECT user_id,
R_score AS 'R值打分',
F_score AS 'F值打分',
CASE WHEN R_score>(SELECT AVG(R_score) FROM RF_score) THEN '高' ELSE '低' END AS 'R_class',
CASE WHEN F_score>(SELECT AVG(F_score) FROM RF_score) THEN '高' ELSE '低' END AS 'F_class'
FROM RF_score
GROUP BY user_id
根据用户分类细则表,对用户进行分层
CREATE OR REPLACE VIEW RF_label AS
SELECT user_id,
R值打分,
F值打分,
R_class,
F_class,
CASE WHEN R_class='高' AND F_class='高' THEN '价值用户'
WHEN R_class='高' AND F_class='低' THEN '发展用户'
WHEN R_class='低' AND F_class='高' THEN '保持用户'
WHEN R_class='低' AND F_class='低' THEN '挽留用户'
END AS 'label'
FROM RF_class
GROUP BY user_id
#将视图转换成表,加快查询效率
create table rf_labeltable as
select *
from rf_label;
根据RFM模型分层结果,得出各用户群所占的比例
SELECT a.label AS '用户类别',
a.ct AS '用户数',
a.ct/(SELECT COUNT(DISTINCT user_id) FROM RF_labeltable) AS '用户占比'
FROM
(SELECT label,
COUNT(DISTINCT user_id) AS 'ct'
FROM RF_labeltable
GROUP BY label) AS a
GROUP BY a.label
基于 RFM 模型进行用户分层
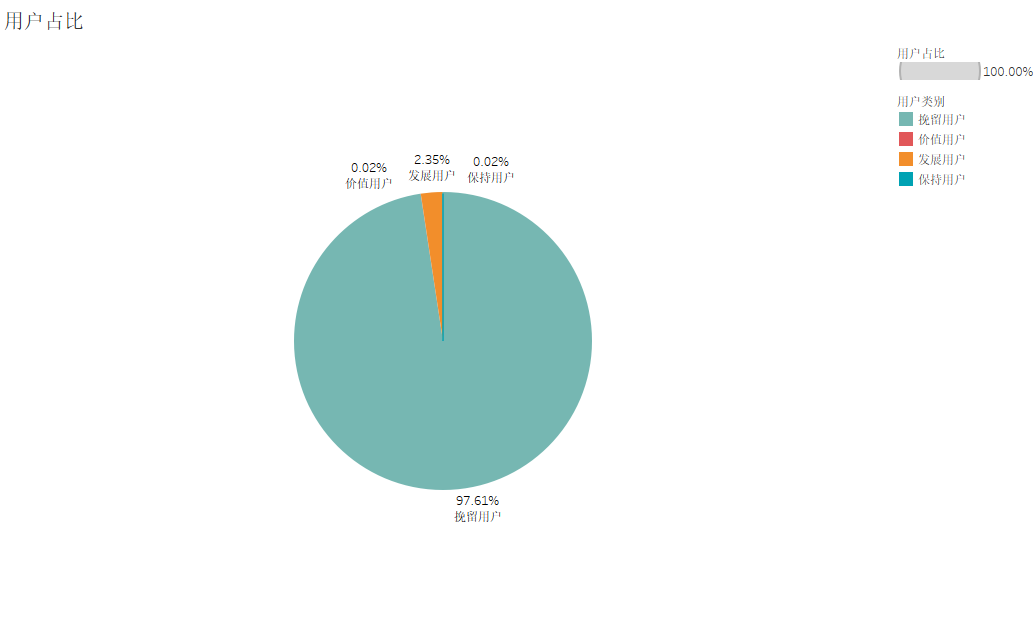
从上图我们可以看出,挽留用户占了大部分,为97.61%,发展用户次之,为2.35%,而价值用户占比和保持用户占比仅为 0.02%。