DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
参数
#用来指定特定的列,默认所有列
subset : column label or sequence of labels, optional
# keep='first'删除重复项并保留第一次出现的数据,#keep='first'删除重复项并保留最后出现的数据,#keep= False 删除所有重复数据
keep : {‘first', ‘last', False}, default ‘first'
是直接在原来数据上修改还是保留一个副本
True是在原数据上修改
inplace : boolean, default False
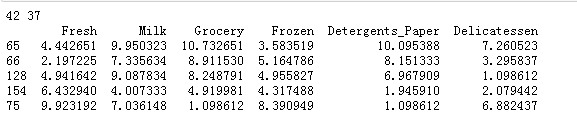
保留重复数据 思路和代码:
注意使用 inplace=False 不破坏原有数据,产生新数据。原有数据在第2步还要用到
1 #1:使用keep=‘first’参数,保留首次出现的重复项,删除后出现的。 这时数据保留了 之前不重复数据+首次出现的重复数据, 2 a=df.drop_duplicates(subset=None, keep='first', inplace=False) 3 4 #2:使用keep=‘False’参数,删除所有重复的数据。这时数据保留了 之前不重复数据。 5 b=df.drop_duplicates(subset=None, keep=False, inplace=False) 6 7 #3.把两个数据连接起来,在删除所有重复的数据,就得到了 之前重复的数据。 8 # 意思是: (之前不重复数据+首次出现的重复数据)+(之前不重复数据) - 之前不重复数据*2 =首次出现的重复数据 9 c=a.append(b).drop_duplicates(keep=False) 10 print len(a),len(b) 11 print c
输出得到结果: