正则表达式:匹配文本片段的模式。
- 通配符:匹配多于一个的字符串。如‘.’可以匹配除换行符之外所有字符,只能匹配一个字符。
- 对特殊字符进行转义:假如要对字符串‘Python.org’进行匹配,如果直接使用‘python.org’进行匹配,则不仅会匹配到'python.org',还会有'pythoniorg'等其他字符串,此时需要对‘'.'进行转义,使用‘python\.org’或者r'python.org'进行匹配。
- 字符集:使用中括号来创建字符集,其中包括所有你想要匹配到的字符,如‘[pj]ython’可以匹配到'python'和'jython','[a-zA-Z0-9]'能匹配任意大小写字母和数字,字符集只能匹配一个字符。反转字符集,如'[^abc]'表示可以匹配除a、b、c之外的所有字符。
- 选择符和子模式:管道符号‘|',用于选择,如只匹配‘Python’和‘jython’,则使用‘Python|jython进行匹配,或者只对模式的一部分使用选择运算符,如'(P|j)ython',使用圆括号括起需要的部分,称子模式,
- 可选项和重复子模式:在子模式后面加上问号就变成了可选项,如r‘(http://)?(www.)?python.org’可匹配到以‘http://www.’、‘‘http:’、‘www.’开头以及'python.org'这些字符串。问号表示允许子模式出现0次或一次。
(pattern)*:允许子模式出现0次或多次
(pattern)+:允许子模式出现1次或多次
(pattern){m,n}:允许模式重复m到n次
- 字符串的开始和结尾:前面的都是针对整个字符串进行匹配,如果要针对字符串开始或者结尾进行匹配则需要使用‘^’标记,如‘^ht+p’只匹配字符串开始的'ht+p'字符,限定字符串结尾匹配则使用‘$’标识
re模块的常用函数
| 函数 | 描述 |
| compile(pattern[,flags]) |
根据包含正则表达式的字符串创建模式对象 |
| search(pattern,string[,flags]) |
在字符串中寻找模式 |
| match(pattern,string[,flags]) |
在字符串开始处匹配模式 |
| split(pattern,string[,maxsplit = 0]) |
根据模式的匹配项来分割字符串 |
| findall(pattern,string) |
列出字符串中模式的所有匹配项 |
| sub(pat,repl,string[,count = 0]) |
将字符串中所有pat的匹配项用repl替换 |
| escape(string) |
将字符串中所有特殊正则表达式字符转义 |
对于re模块中的匹配函数而言,匹配成功则返回MatchObject对象,这些对象包括匹配模式的子字符串信息,还包含了哪个模式匹配了哪部分的信息,这些“部分”叫做组,组就是放置在元组括号内的子模式。
模式‘there (was a (wee) (cooper)) who (lived in fyfe)’包含以下组:
0 there was a wee cooper who lived in fyfe
1 was a wee cooper
2 wee
3 cooper
4 lived in fyfe
re匹配对象的重要方法:
| 方法 |
描述 |
| group([group1,……]) |
获取给定子模式(组)的匹配项 |
| start([group]) |
返回给定组的匹配项的开始位置 |
| end([group]) |
返回给定组的匹配项的结束位置 |
| span([group]) |
返回一个组的开始和结束位置 |
>>> import re >>> m = re.match('www.(.*)..{3}','www.python.org') >>> g1 = m.group(1) >>> m.group(1) 'python' >>> m.end(1) 10 >>> m.span(1) (4, 10) >>> m.group(0) 'www.python.org'
在重复运算符后增加一个‘?’就把重复运算变成非贪婪版本
re.split()函数进行切割时,如果模式中含有小括号,那么小括号中内容将会在每一个子字符串之间存在。
re.split(pattern,string[,maxsplit = 0])
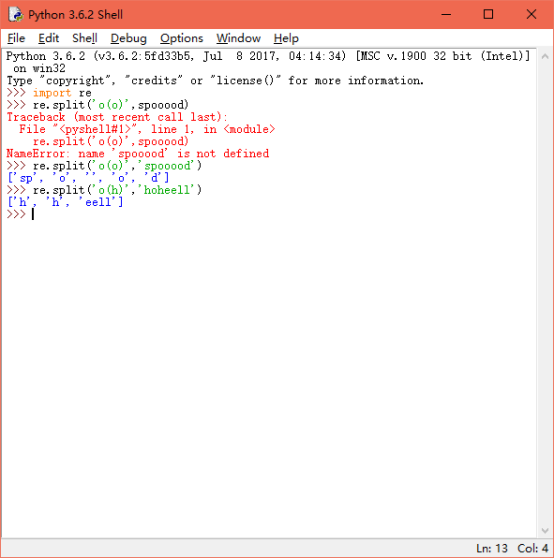
split函数还有一个限制分割次数的参数maxsplit
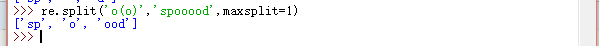
re.findall函数以列表形式返回给定模式的所有的匹配项。
re.findall(pattern,str)

对于findall函数,有一个小坑,在提取数据时注意括号的使用。
#findall函数的提取数据内容实际是模式内括号的内容 >>> re.findall(r'hello(.*?)world',"hello xyz world") [' xyz '] >>> re.findall(r'hello .*? world',"hello xyz world") ['hello xyz world']
re.sub()函数使用指定内容替换匹配到的最左端并且非重叠的子字符串。
re.sub(pat,repi,str[,count = 0])

sub()函数可以通过组来替换,在替换内容中使用‘\n’形式出现的任何转义序列都会被模式中与组n匹配的字符串替换掉。
例如将文本中的*something*替换成<em>something</em>
>>> pat = r'*([^*]+)*' >>> re.sub(pat,r'<em>1</em>','hello *world*!') 'hello <em>world</em>!' >>> pat =re.compile(r'*([^*]+)*') >>> re.sub(pat,r'<em>1</em>','hello *world*!') 'hello <em>world</em>!'
重复运算符是贪婪的,它会进行尽可能多的匹配。
>>> pat = r'*(.+)*' >>> re.sub(pat,r'<em>1</em>','hello *world*!') 'hello <em>world</em>!' >>> re.sub(pat,r'<em>1</em>','*hello* *world*!') '<em>hello* *world</em>!'
此时就需要用到非贪婪模式,即在重复匹配符后面增加一个‘?’
>>> pat = r'*(.+?)*' >>> re.sub(pat,r'<em>1</em>','hello *world*!') 'hello <em>world</em>!' >>> re.sub(pat,r'<em>1</em>','*hello* *world*!') '<em>hello</em> <em>world</em>!'
点击查看re.sub()函数详解
re.escape函数是一个是一个将所有可能被解释为正则运算符的字符进行转义的函数。
>>> re.escape('hello.python') 'hello\.python'
正则从暑假看到现在,断断续续,不要放弃啊