使用 pip 安装 requests_html 库
pip install requests_html
根据你的网络情况,通常需要几分钟时间。
在你的电脑任意位置,新建一个 crawler.py 文件。输入并执行以下 4 行代码:
from requests_html import HTMLSession session = HTMLSession() r = session.get('https://movie.douban.com/subject/1292052/') print(r.text)
运行
你将会看到如下输出:
<!DOCTYPE html> <html lang="zh-cmn-Hans" class="ua-mac ua-webkit"> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <meta name="renderer" content="webkit"> <meta name="referrer" content="always"> <meta name="google-site-verification" content="" /> <title> 肖申克的救赎 (豆瓣) </title> ... 以下省略 3000 行
提取网页中所需内容
你将使用强大的 CSS 选择器 来提取网页中有价值的信息。
CSS 选择器可以从结构化的网页中选择一个特定的元素。
大多数浏览器都提供了获得页面上特定元素 CSS 选择器的功能。
先查看一段内容的代码,在代码上点击右键,选择 Copy -> Copy Selector (或者 Copy CSS Selector、复制 CSS 选择器),就能将这段内容对应的 CSS 选择器复制到剪贴板。
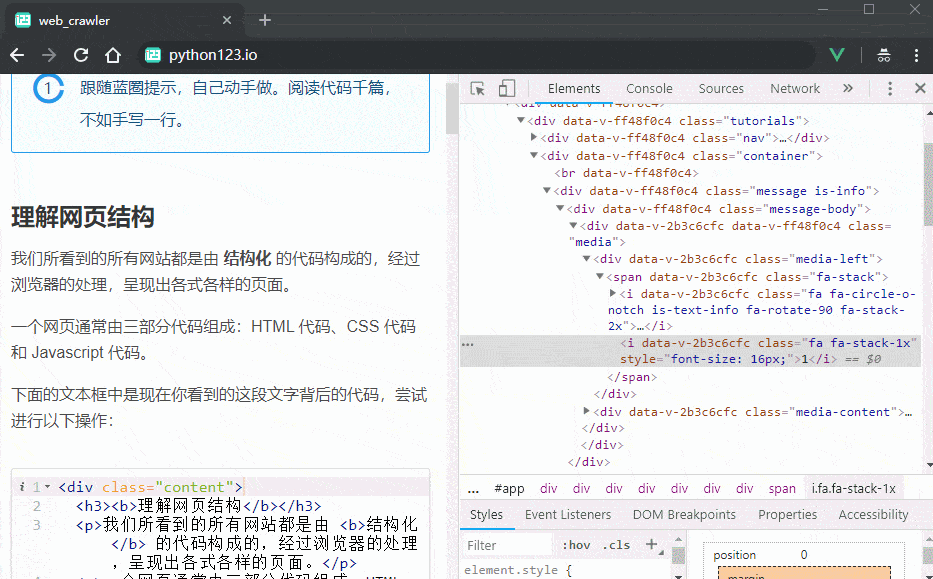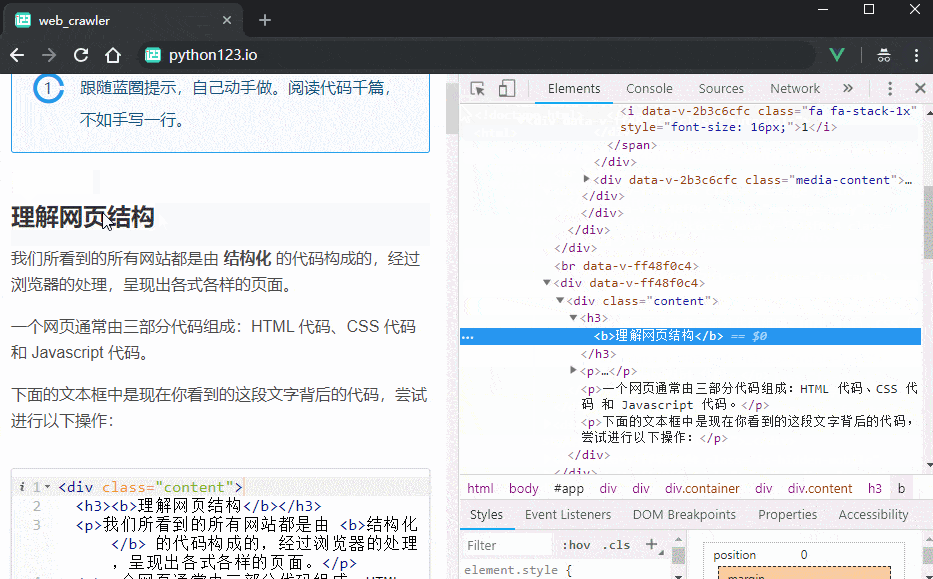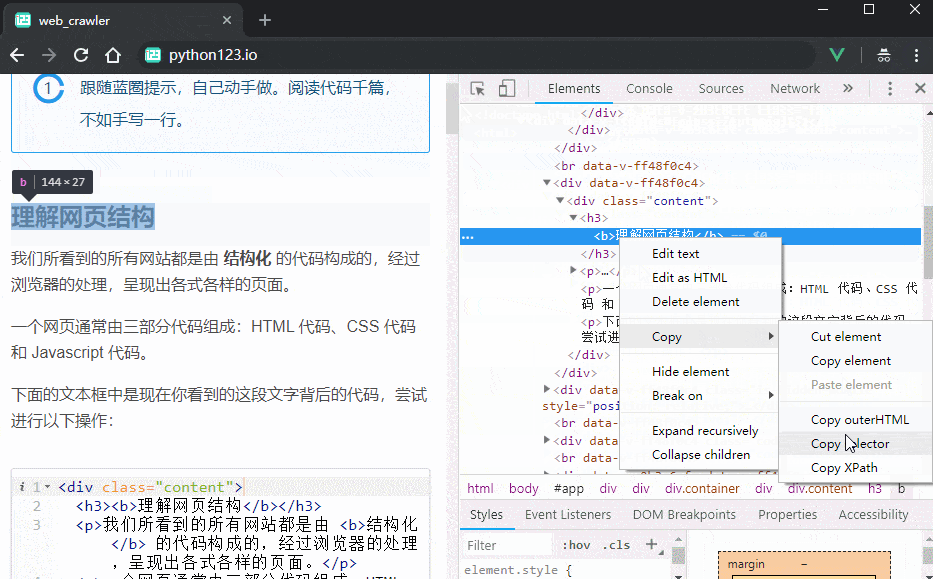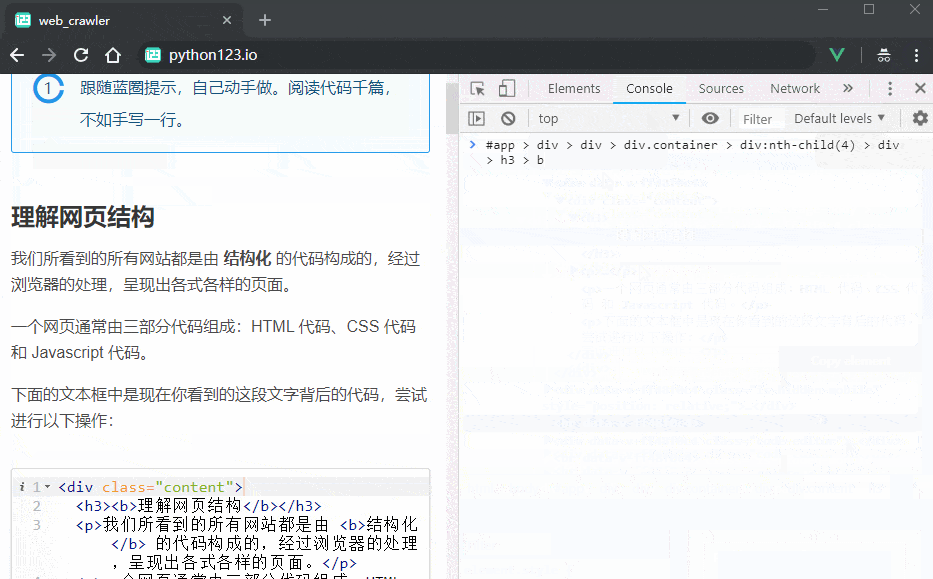
现在你需要访问 这个 页面。按照上面的介绍,把电影名称对应的选择器复制上
回到之前创建的 crawler.py 文件,使用 Python 和 CSS 选择器来提取网页内容。
from requests_html import HTMLSession session = HTMLSession() r = session.get('https://movie.douban.com/subject/1292052/') title = r.html.find('用你的选择器替换这里的内容', first=True) # r.html.find() 接受一个 CSS 选择器(字符串形式)作为参数 # 返回在网页中使用该选择器选中的内容。 print(title.text)
运行看看,你是否把电影名称从网页中提取出来了呢?如果成功了,试试提取其它你感兴趣的内容吧!
