撰写本文的目的:对于sparksql,网上有大量的详细文档,本人针对常用的操作进行一个整理,当然有大多数都是从其他地方搬过来的,包括官方文档以及其他网友的一些分享,一来是通过此次整理加强自己的记忆,二来如果有幸帮到某位网友,那是本人莫大的荣幸,先感谢您的阅读,废话不多说,进入正文:
下文所涉及到的相关软件版本分别为:
spark版本:v2.2.0
hive : v1.2.1
hadoop : v2.7.6
前言:
Spark sql是spark处理结构化数据的一个模块,它的前身是shark,与基础的spark rdd不同,spark sql提供了结构化数据及计算结果等信息的接口,在内部,spark sql使用这个额外的信息去执行额外的优化,有几种方式可以跟spark sql进行交互,包括sql和dataset api,使用相同的执行引擎进行计算的时候,无论是使用哪一种计算引擎都可以一快速的计算。
Dataset and DataFrames
RDD:在spark刚开始的时候,引入RDD(弹性分布式数据集)
优点:
1)编译时类型安全,编译时就能检查出类型错误
2)面向对象的编程分格,直接通过类名点的方式来操作数据
例如:idAge.filter(_.age > "") //编译时直接报错
idAgeRDDPerson.filter(_.age > 25) //直接操作一个个的person对象
缺点:
1)序列化和反序列化的性能开销,无论是集群间的通信还是IO操作,都需要对对象的结果和数据进行序列化和反序列化
2)GC的性能开销,频繁的创建和销毁对象,势必会增加GC
DataFrame:spark1.3的时候引入了DataFrmae,是一个列方式组织的分布式数据集
优点:
1)引入了Schema,包含了一ROW位单位的每行数据的列信息,spark通过Schema就能够读懂数据,因此在通信和IO时就只需要序列化和反序列化数据,而结构的部分就可以省略了;
2)off-heap:spark能够以二进制的形式序列化数据(不包括结构)到off-heap(堆外内存),当要操作数据时,就直接操作off-heap内存,off-heap类似于地盘,schema类似于地图,Spark有了地图又有了自己地盘了,就可以自己说了算,不再受JVM的限制,也就不再受GC的困扰了,通过Schema和off-heap,DataFrame克服了RDD的缺点。对比RDD提升了计算效率,减少了数据的读取,底层计算优化
3)引入了新的引擎:Tungsten
4)引入了新的语法解析框架:Catalyst
缺点:
DataFrame客服了RDD 的缺点,但是丢失了RDD的优点,DataFrame不是类型安全的,API也不是面向对象分格的。
1)API不是面向对象的
idAgeDF.filter(idAgeDF.col("age") > 22)
2)DataFrame不是编译时类型安全的,下面这种情况下不会报错
idAgeDF.filter(idAgeDF.col("age") > "")
DataSet:到spark1.6的时候引入了DataSet,Encoder分布式数据集,是一个被添加的新接口,它提供了RDD 的优点(强类型化,能够使用强大的lambda函数)
/**
* @groupname basic Basic Dataset functions
* @groupname action Actions
* @groupname untypedrel Untyped transformations
* @groupname typedrel Typed transformations
*
* @since 1.6.0
*/
@InterfaceStability.Stable
class Dataset[T] private[sql](
@transient val sparkSession: SparkSession,
@DeveloperApi @InterfaceStability.Unstable @transient val queryExecution: QueryExecution,
encoder: Encoder[T])
extends Serializable {
DataSet是一个类,其中包含了三个参数:
- SparkSession:环境信息
- QueryExecution:包含数据和执行逻辑
- Encoder:数据结构编码信息(包含序列化,schema,数据类型)
核心:Encoder
优点:
1)一个DataSet可以从JVM对象来构造并且使用转换功能(map,flatMap,filter...)
2)编译时的类型安全检查。性能极大地提升,内存使用极大降低,减少GC。极大地较少网络数据的传输、极大地减少scala和java之间代码的差异性
3)DataFrame每一行对应一个Row。而DataSet的定义更加宽松,每一个record对应了一个任意的类型。DataFrame只是DataSet的一种特例:type DataFrame = Dataset[Row]
4)不同的Row是一个泛华的无类型的JVM object,Dataset是有一系列的强类型的JVM object组成的,Scala的case class或者java class定义。因此Dataset可以在编译时进行类型检查
5)Dataset一Catalyst逻辑执行计划表示,并且数据以编码的二进制形式被存储,不需要反序列化就可以执行sorting,shuffle等操作
6)Dataset创建需要一个显示的Encoder,把对象序列化为二进制
7)在scala API中,DataFrame仅仅是一个DataSet[Row]类型的别名,然而,在Java API中,用户需要使用Dataset<Row> 去代表一个DataFrame。
sparkSession
Spark2.0中开始引入了SparkSession的概念,它为用户提供了一个统一的切入点来使用Spark的各项功能,包括SQLContext和HiveContext的组合(未来可能会加上StreamingContext),用户不但可以使用DataFrame和Dataset的各种API,大大降低了spark的学习难度
创建sparkSession:
scala:
import org.apache.spark.sql.SparkSession
val ssc = new SparkSession
.Builder()
.appName("name_in_webUI") //这里的这个名字随便起,只要是自己能认识,最终这个是要显示在weiUI界面的
.enableHiveSupport() //如果需要访问hive,这一步不能少,如果只是读取本地文件这一句可以省去
.getOrCreate()
//创建之后可以设置运行参数
ssc.conf.set("spark.sql.shuffle.partitions",4)
ssc.conf.set("spark.executor.memory","2g")
java:
import org.apache.spark.sql.SparkSession;
SparkSession spark = SparkSession .builder() .appName("name_in_webUI") .getOrCreate();
spark.conf().set("spark.sql.shuffle.partitions",4);
spark.conf().set("spark.executor.memory","2g");
Row
Row是一个泛华的无类型的JVM object
Row的访问方式:
import org.apache.spark.sql.Row val row = Row(1,'asd',3.3) //Row的访问方式 row(0) row(1) row(2) row.getInt(0) row.getString(1) row.getDouble(2) row.getAs[Int](0) row.getAs[String](1) row.getAs[Double](2)
DataFrame:
DataFrame即是带有schema信息的RDD,spark直接可通过Schema就可以读懂信息。
schema:
DataFrame中提供了详细的数据信息,从而使得sparkSql可以清楚的知道数据集中包含了哪些列,每列的名称和类型是什么?DataFrame的结构信息即为schema。
schema的定义方式:
import org.apache.spark.sql.types._
1、来自官网文档
val schema1 = StructType( StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("height", IntegerType, false) :: Nil)
val schema2 = StructType( Seq(StructField("name", StringType, false),
StructField("age", IntegerType, false),
StructField("height", IntegerType, false)))
val schema3 = StructType( List(StructField("name", StringType, false),
StructField("age", IntegerType, false),
StructField("height", IntegerType, false)))
2、来自spark源码
val schema4 = (new StructType).
add(StructField("name", StringType, false)).
add(StructField("age", IntegerType, false)).
add(StructField("height", IntegerType, false))
val schema5 = (new StructType).
add("name", StringType, true, "comment1").
add("age", IntegerType, false, "comment2").
add("height", IntegerType, true, "comment3")
3、最便捷的方式
val schema6 = (new StructType).
add("name", "string", false).
add("age", "integer", false).
add("height", "integer", false)
RDD、DataFrame和DataSet的共性与区别
共性:
- 三者都是spark平台下的分布式弹性数据集,为处理超大型数据提供便利
- 三者都有惰性机制。在创建时、转换时(如map)不会立即执行,只有在遇到action算子的时候(比如foreach),才开始进行触发计算。极端情况下,如果代码中只有创建、转换,但是没有在后面的action中使用对应的结果,在执行时会被跳过。
- 三者都有partition的概念,都有缓存(cache)的操作,还可以进行检查点操作(checkpoint)
- 三者都有许多共同的函数(如map、filter,sorted等等)。
- 在对DataFrame和DataSet操作的时候,大多数情况下需要引入隐式转换(ssc.implicits._)
不同:
DataFrame:
DataFrame是DataSet的特例,也就是说DataSet[Row]的别名
DataFrame = RDD + schema
- DataFrame的每一行的固定类型为Row,只有通过解析才能获得各个字段的值
- DataFrame与DataSet通常与spark ml同时使用
- DataFrame与DataSet均支持sparkSql操作,比如select,groupby等,也可以注册成临时表,进行sql语句操作
- DataFrame与DateSet支持一些方便的保存方式,比如csv,可以带上表头,这样每一列的字段名就可以一目了然
DataSet:
DataSet = RDD + case class
- DataSet与DataFrame拥有相同的成员函数,区别只是只是每一行的数据类型不同。
- DataSet的每一行都是case class,在自定义case class之后可以很方便的获取每一行的信息
DataFrame和DataSet的基本操作
DataFrame和DataSet的创建
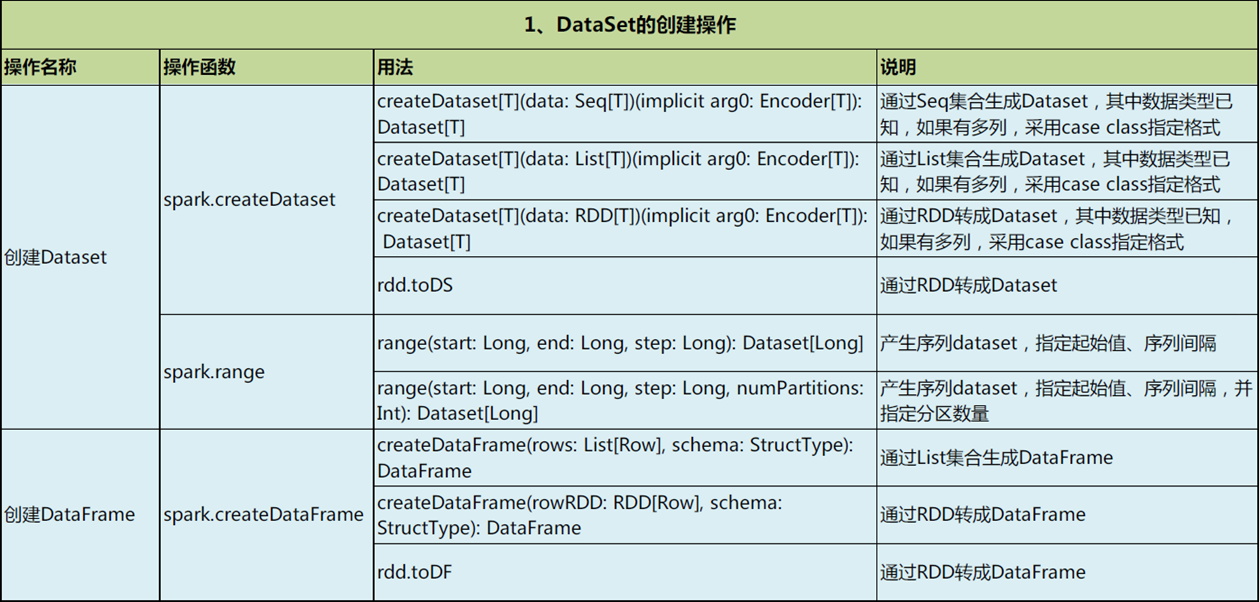
DataFrame
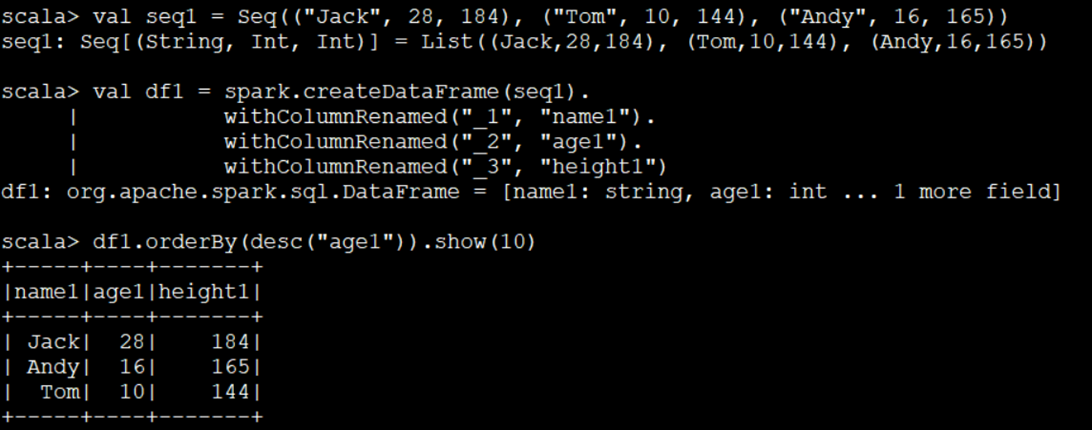
1、集合转DataFrame
val ssc = SparkSession().Builder.master("test").appName("test").getOrCreate
val seq1 = Seq(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val df1 = ssc.createDataFrame(seq1).withColumnRenamed("_1", "name1").
withColumnRenamed("_2", "age1").withColumnRenamed("_3", "height1")
df1.orderBy(desc("age1")).show(10)
import ssc.implicit._
val df2 = ssc.createDataFrame(seq1).toDF("name", "age", "height")
2、RDD转DataFrame
import org.apache.spark.sql.Row
import org.apache.spark.sql.types._
val arr = Array(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val rdd1 = sc.makeRDD(arr).map(f=>Row(f._1, f._2, f._3))
val schema = StructType( StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("height", IntegerType, false) :: Nil)
// false:说明该字段不允许为null true:说明该字段可以为null
val rddToDF = spark.createDataFrame(rdd1, schema)
rddToDF.orderBy(desc("name")).show(false)

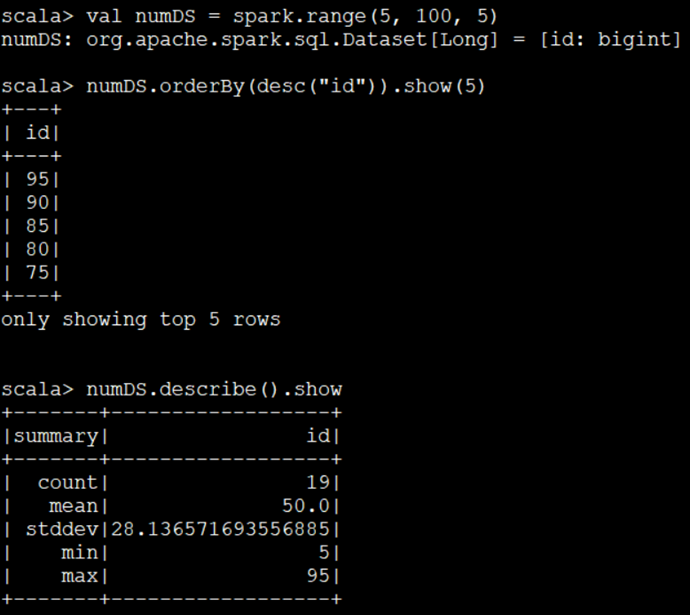
DataSet
1、由range生成DataSet
val numDS = spark.range(5,100,5)
numDS.orderBy(desc("id")).show(5)
numDS.describe().show
2、由集合生成DS
case class Person(name:String, age:Int, height:Int)
val seq1 = Seq(Person("Jack", 28, 184), Person("Tom", 10, 144), Person("Andy", 16, 165))
val spark:SparkSession = SparkSession.Builder....
val ds1 = spark.createDataset(seq1)
ds1.show
val seq2 = Seq(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val ds2 = spark.createDataset(seq2)
ds2.show
3、由RDD进行转换
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
val arr = Array(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
val rdd2 = sc.makeRDD(arr).map(f=>Row(f._1, f._2, f._3))
val rdd3 = sc.makeRDD(arr).map(f=>Person(r._1,f._2,f._3))
val ds3 = sc.createDataset(rdd2)
val ds4 = rdd3.toDS()
ds3.show(10)
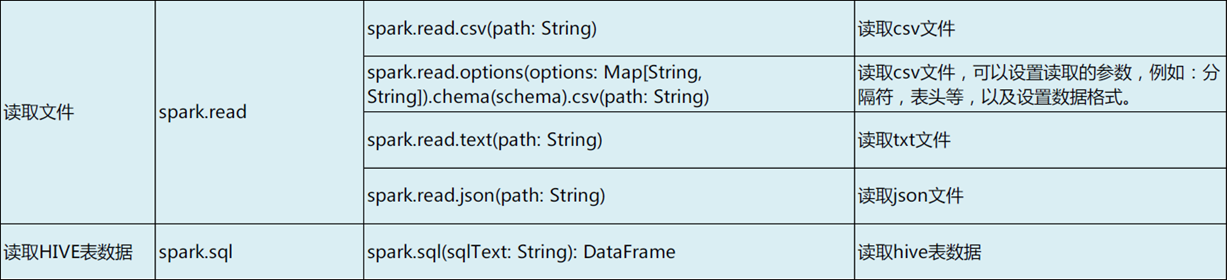
通过SparkSession读取文件
import org.apache.spark.sql.types._
val schema2 = StructType( StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("height", IntegerType, false) :: Nil)
val df7 = ssc.read.options(Map(("delimiter", ","), ("header", "false"))).schema(schema2).csv("file:///home/spark/t01.csv") // 读取本地文件
df7.show()

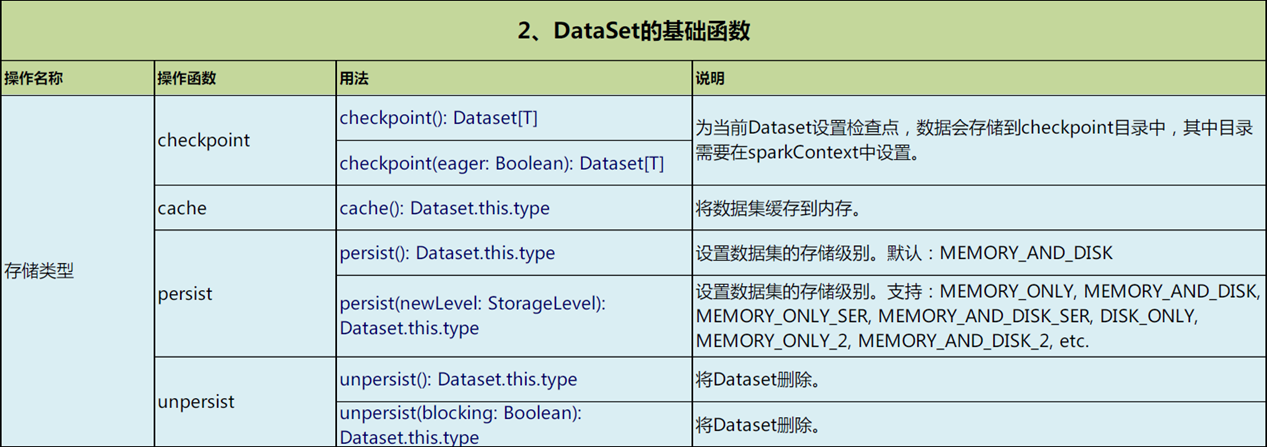
DataSet的基础函数

import org.apache.spark.storage.StorageLevel
import org.apache.spark.sql.types._
case class Person(name:String, age:Int, height:Int)
spark.sparkContext.setCheckpointDir("hdfs://node1:8020/checkpoint")
// 1 DataSet存储类型
val seq1 = Seq(Person("Jack", 28, 184), Person("Tom", 10, 144), Person("Andy", 16, 165))
val ds1 = spark.createDataset(seq1)
ds1.show()
ds1.checkpoint()
ds1.cache()
ds1.persist(StorageLevel.MEMORY_ONLY)
ds1.count()
ds1.show()
ds1.unpersist(true)
// 2 DataSet结构属性
ds1.columns
ds1.dtypes
ds1.explain()
ds1.col("name")
ds1.printSchema // 常用
// 3 DataSet rdd数据互转
val rdd1 = ds1.rdd
val ds2 = rdd1.toDS()
ds2.show()
val df2 = rdd1.toDF()
df2.show()
// 4 Dataset保存文件
ds1.select("name", "age", "height").write.format("csv").save("data/sql1/my01.csv")
// 读取保存的文件
val schema2 = StructType( StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("height", IntegerType, false) :: Nil)
val out = spark.read.
options(Map(("delimiter", ","), ("header", "false"))).
schema(schema2).csv("data/sql1/*")
out.show(10)
DataSet的Action操作


// 1 显示数据集
val seq1 = Seq(Person("Jack", 28, 184), Person("Tom", 10, 144), Person("Andy", 16, 165))
val ds1 = spark.createDataset(seq1)
// 缺省显示20行
ds1.show()
// 显示2行
ds1.show(2)
// 显示20行,不截断字符
ds1.show(20, false)
// 2 获取数据集
// collect返回的是数组
val c1 = ds1.collect()
// collectAsList返回的是List
val c2 = ds1.collectAsList()
val h1 = ds1.head()
val h2 = ds1.head(3)
val f1 = ds1.first()
val f2 = ds1.take(2)
val t2 = ds1.takeAsList(2)
ds.limit(10).show // 取10行数据生成新的DataSet
// 3 统计数据集
ds1.count()
// 返回全部列的统计(count、mean、stddev、min、max)
ds1.describe().show
// 返回指定列的统计(count、mean、stddev、min、max)
ds1.describe("age").show
ds1.describe("age", "height").show
// 4 聚集
ds1.reduce{ (f1, f2) => Person("sum", f1.age+f2.age, f1.height+f2.height) }