Aggregate函数
一、源码定义
/**
* Aggregate the elements of each partition, and then the results for all the partitions, using
* given combine functions and a neutral "zero value". This function can return a different result
* type, U, than the type of this RDD, T. Thus, we need one operation for merging a T into an U
* and one operation for merging two U's, as in scala.TraversableOnce. Both of these functions are
* allowed to modify and return their first argument instead of creating a new U to avoid memory
* allocation.
*
* @param zeroValue the initial value for the accumulated result of each partition for the
* `seqOp` operator, and also the initial value for the combine results from
* different partitions for the `combOp` operator - this will typically be the
* neutral element (e.g. `Nil` for list concatenation or `0` for summation)
* @param seqOp an operator used to accumulate results within a partition
* @param combOp an associative operator used to combine results from different partitions
*/
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U): U = withScope {
// Clone the zero value since we will also be serializing it as part of tasks
var jobResult = Utils.clone(zeroValue, sc.env.serializer.newInstance())
val cleanSeqOp = sc.clean(seqOp)
val cleanCombOp = sc.clean(combOp)
val aggregatePartition = (it: Iterator[T]) => it.aggregate(zeroValue)(cleanSeqOp, cleanCombOp)
val mergeResult = (index: Int, taskResult: U) => jobResult = combOp(jobResult, taskResult)
sc.runJob(this, aggregatePartition, mergeResult)
jobResult
}
首先,大致解释一下源码中的定义:
因为通常为我们的spark程序计算是分布式的,所以我们通常需要聚合的数据都分部在不同的分区,不同的机器上。
该函数它会首先对每个分区内的数据基于初始值进行一个首次聚合,然后将每个分区聚合的结果,通过使用给定的聚合函数,再次基于初始值进行分区之间的聚合,并且最终干函数的返回结果的类型,可以是与该RDD的类型相同。什么意思呢,其实这样说,还是有点蒙圈的,下面详细道来。
从源码中可以看出,该函数是一个柯里化函数,它需要接受一共三个参数,分别是:
- zeroValue:U
这个值代表的是我们需要设置的初始值,该初始值可以是不与原RDD的元素的类型相同,可以是Int,String,元组等等任何我们所需要的类型,根据自己的需求来,为了方便后面的表示,假设我把它定义为数值类型的元组(0,0),注意,这里必须是具体的值,并非函数
- seqOp: (U, T) => U
这里需要定义一个函数,注意,是函数,U的类型与我们在第一步中定义的初始值得类型相同,所以,这里的U指的就是(Int,Int)类型
这里的T代表的即为RDD中每个元素的值。
该函数的功能是,在每个分区内遍历每个元素,将每个元素与U进行聚合,具体的聚合方式,我们可以自定义,不过有一点需要注意,这里聚合的时候依然要基于初始值来进行计算
- combOp: (U, U) => U
这里同样需要定义一个函数,这里的U即为每个分区内聚合之后的结果,如上,上一步中的U为(Int,Int)类型,则这里的U也为该类型
该函数的主要作用就是对每个分区聚合之后的结果进行再次合并,即分区之间的合并,但是,同样,在合并的开始,也是要基于初始进行合并,其实这里我们可以发现,这里U的类型是与初始值的类型是相同的。
上面啰里啰嗦的说了这么所,感觉还是不太直观,上代码瞧瞧:
案例1:求取给定RDD的平均数
object TestAggreate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("warn")
val rdd1 = sc.parallelize(Seq(("a", 2), ("a", 5), ("a", 4), ("b", 5), ("c", 3), ("b", 3), ("c", 6), ("a", 8)), 1)
val r1 = rdd1.aggregate((0, 0))(
(u, c) => (u._1 + 1, u._2 + c._2),
(r1, r2) => (r1._1 + r2._1, r1._2 + r2._2)
)
println(r1)
sc.stop()
}
}
这里先给出运行结果,再来解释:

首先我们需要确定,该RDD的分区数为1,也就是说所有的数据都是在一个分区内进行计算,其次该RDD的类型是RDD[(String,Int)],我的目标是求该RDD总个数以及第二个值得总和
1、首先定义初始值,该例子中我定义为了(0,0),是一个(Int,Int)类型的,我准备第一个0代表计数,第二个0代表对每个元素进行求和
2、(u,c),这个函数,这里的u类型就是(Int,Int)类型,c指的就是RDD中的每个元素,每遍历一个元素c,u的第一个元素就会加1,也就是u._1 + 1,同时u的第二个元素会对c的第二个元素进行累加,也就是u._2 + c._2,不过这里的累加都是要基于初始值进行累加的,顺序是这样的:
第一次 0+1,0+2
第二次 1+1,2+5
第三次 2+1,7+4
第四次 3+1,11+5
第五次 4+1,16+3
第六次 5+1,19+3
第七次 6+1,22+6
第八次 7+1,28+8
最终结果就是(8,36)
3、(r1.r2),该函数是实现每个分区内的数据进行合并,因为这里只有一个分区,所以只是分区0与另外一个空分区进行合并。
这里如果我们将分区数设置为超过1个的情况下,会怎样呢,来看下:
bject TestAggreate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("warn")
val rdd1 = sc.parallelize(Seq(("a", 2), ("a", 5), ("a", 4), ("b", 5), ("c", 3), ("b", 3), ("c", 6), ("a", 8)), 4)
val r1 = rdd1.aggregate((0, 0))(
(u, c) => (u._1 + 1, u._2 + c._2),
(r1, r2) => (r1._1 + r2._1, r1._2 + r2._2)
)
println(r1)
sc.stop()
}
}
这种情况下,我们将RDD分在了四个分区内,每个分区内分配两个数据,具体每个分区内有哪几个元素,可以这样查看:
rdd1.foreachPartition(part => {
val partitionId = TaskContext.getPartitionId()
part.foreach(x => {
println((partitionId, x._1, x._2))
})
})

从上面可以看出,分区数据分别是存在了part0((a,2),(a,5)),part1((a,4),(b,5)),part1((c,3),(b,3)),part3((c,6),(a,8)),这种情况下的合并过程是这样的:
1、每个分区内合并,结果就是 part0(0+1+1,0+2+5) part1(0+1+1,0+4+5) part2(0+1+1,0+3+3) part3(0+1+1,0+6+8)
2、(part0,part1) => (part0._1 + part1._1,part0._2+part1._2),然后使用该结果,在依次与part2,part3进行合并,结果就为(0+2+2+2+2,0+7+9+6+14),结果(8,36)
这里我在测试的过程中发现一个问题,就是说在分区数大于1的情况下,当我最后将分区合并的函数中的聚合过程,相互颠倒过来的话,也就是,正常,我应该得到(8,36),但是我聚合的时候想得到(36,8)这个结果,下面这段代码:
val r1 = rdd1.aggregate((0, 0))(
(u, c) => (u._1 + 1, u._2 + c._2),
(r1, r2) => (r1._2 + r2._2, r1._1 + r2._1)
)
上面标红的代码,我颠倒了顺序,我的预期的得到(36,8),但是结果却是随机产生的结果,像这样:


接下来解释一下其中缘由:
之所以发生这种错误的结果,是因为我是把最终的聚合方式想当然的理解成了类似reduceBykey的方式,相当然的认为,(r1, r2) => (r1._2 + r2._2, r1._1 + r2._1) 这段代码就会是两个元祖进行对应位置的元素进行加和,然而并不是。我打印每一步的操作看一下:
val r1 = rdd1.aggregate((0, 0))(
(u, c) => {
val pid = TaskContext.getPartitionId()
println(s"----分区${pid}聚合前:u:${u},c:${c}")
val t = (u._1 + 1, u._2 + c._2)
println(s"----分区${pid}聚合后:${t}")
t
},
(r1, r2) => {
val pid = TaskContext.getPartitionId()
println(s"--------分区${pid}间聚合前:r1:${r1},r2:${r2}")
val t = (r1._2 + r2._2, r1._1 + r2._1)
println(s"--------分区${pid}间聚合后:t:${t}")
t
}
)
打印结果如下图:
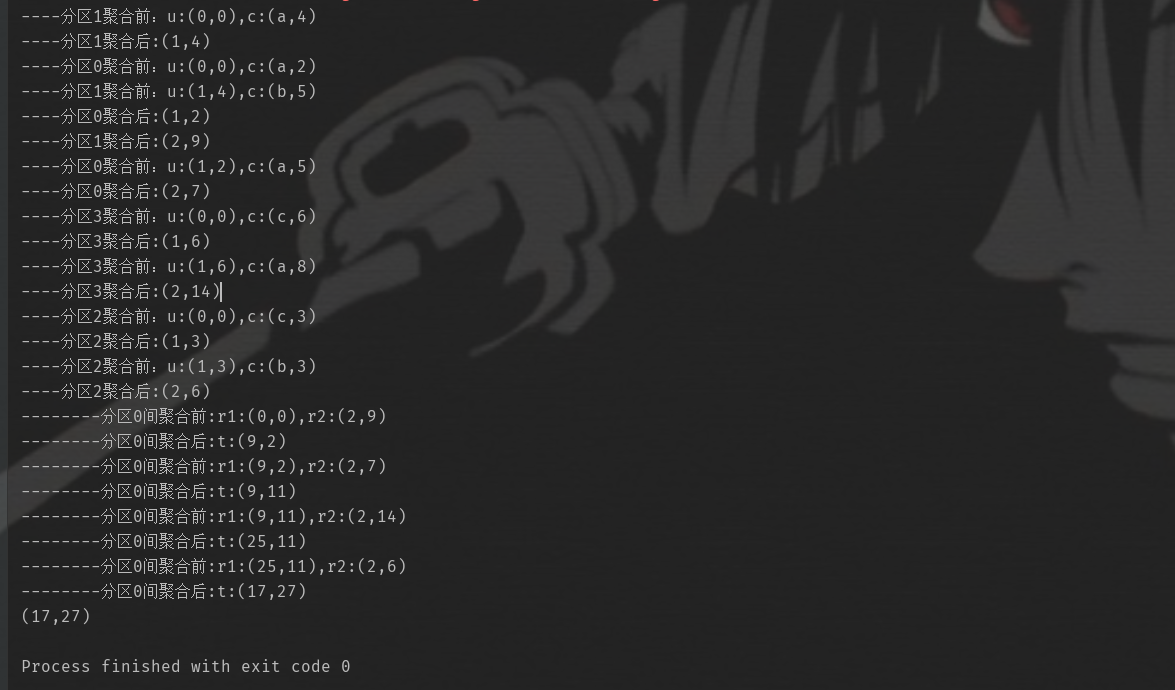
从上面可以看出,程序在执行 (r1, r2) => (r1._2 + r2._2, r1._1 + r2._1) 之前是没问题的,是按照我们的预期来执行的,但是在具体执行这行代码,也就是在进行分区间的聚合的时候,并非按照我们初始的意愿执行,具体的逻辑如下:
分区间进行聚合的初始数据为:
分区0:(2,7)
分区1:(2,9)
分区2:(2,6)
分区3:(2,14)
从结果中可以看到分区间聚合的第一个结果为:(9,2),前面说过,aggregate该算子不管是在分区内聚合还是最终在分区间进行聚合,都会拿初始值作为第一个元素进行加和,也就是我们定义的(0,0)
(0,0) + (2,9) => (2,9) => (9,2)
(9,2) + (2,7) => (11,9) => (9,11)
(9,11) + (2,14) => (11,25) => (25,11)
(25,11) + (2,6) => (27,17) => (17,27)
通过该种方式获取到最终结果,第一次相加的时候(2,9)为分区1中的数据,但是并不是说每次计算的时候都是从分区1开始,这个是不确定的,再次计算的时候也有可能拿分区0为第一个计算,所以会发生每次计算的结果会不一样。
案例2:求和
该案例主要是测试一下初始值的变化对结果产生的影响,进一步证明,不管是在分区内进行聚合还是分区之间进行聚合的时候,都会使用到初始值,案例1中的初始值我们都设置的是0,此时我将其设置成2在来看看结果,测试代码:
object TestAggreate {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
val sc = new SparkContext(conf)
sc.setLogLevel("warn")
val rdd1 = sc.parallelize(Seq(("a", 2), ("a", 5), ("a", 4), ("b", 5), ("c", 3), ("b", 3), ("c", 6), ("a", 8)), 4)
val r1 = rdd1.aggregate((0))(
(u, c) => (u + c._2),
(r1, r2) => (r1 + r2)
)
println(r1)
sc.stop()
}
}
结果:(46),但是实际之和加起来是36,显然多出了10,这个10是怎么来的呢?
计算方式如下:
1、首先这里是4个分区,每个分区进行聚合,而之前说过,分区内聚合都是要以初始值为基准的,也就是说要在初始值得基础上进行相加:
part0 (2+2+5)
part1(2+4+5)
part2(2+3+3)
part3(2+6+8)
2、其次是分区之间的聚合,分区之间的聚合也是要在初始值的基础上相加的,即
2+part0+part1+part2+part3
结果即为46,
所以说,如果我们想要得到预想的结果,对于该函数生成的结果还要减去如下数:
result-initValue*(partitions+1)
总结一下:
该函数是spark中的一个高性能的算子,它实现了先进性分区内的聚合之后在进行了对每个分区的聚合结果再次进行聚合的操作,这样的在大数据量的情况下,大大减少了数据在各个节点之间不必要的网络IO,大大提升了性能,相比于groupBy的函数,在特定情况下,性能提升数十倍不止,不过在使用的过程中一定要对该函数所对应的每个参数的含义了如指掌,这样运用起来才能得心应手。