什么是Hive
hive是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员是用他们最为熟悉的SQL语言就可以进行海量的数据的处理、分析和统计工作,而不是必须掌握JAVA等变成语言和具备开发MapReduce程序的能力。Hive SQL实际上是先被SQL解析器进行解析然后被Hive框架解析成一个MapReduce可执行的计划,并且按照该计划生成MapReduce任务后交给Hadoop集群处理。
由于Hive SQL 是翻译为MapReduce任务后在Hadoop集群执行的,而Hadoop是一个批处理系统,所以Hive SQL是高延迟的,不但翻译成的MapReduce任务执行延迟高,而且任务的提交和处理过程也是非常的耗时。因此,Hive即使处理的数据量非常的小,在执行的过程中也会有一定的延迟现象。同时,Hive不能提供数据排序和查询缓存功能,也不提供在线事务处理,更不提供实时查询和记录的更新,因为HIVE本身被定义为处理大规模的离线数据集。如果需要实现实时查询或记录的更新,HBASE是一个不错的选择。
HIVE的基本架构
作为Hadoop的主要数据仓库解决方案,底层存储依赖于HDFS,而Hive SQL是主要交互接口,而真正的计算和执行则由MapReduce完成,它们之间的桥梁是Hive引擎。接下来,具体看下HIVE的引擎架构:
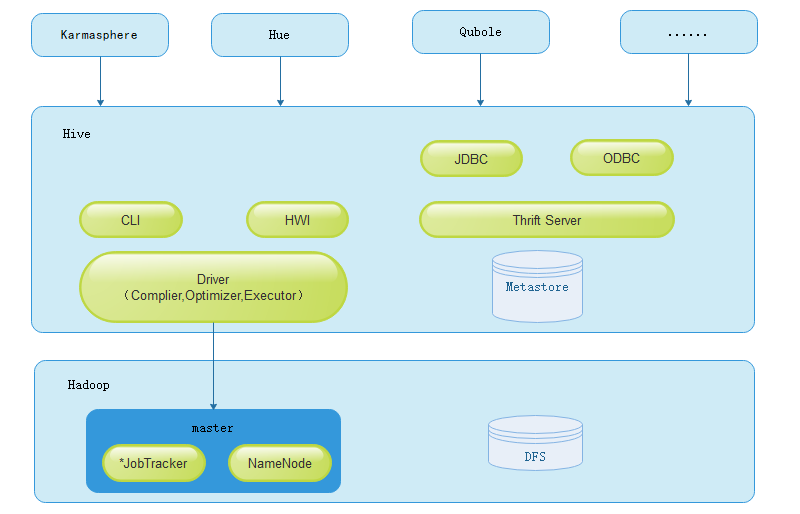
Hive的主要组件包括UI组件、Driver组件(Complier、Optimizer和Executor)、Metastore组件、CLI(Command Line Interface,命令行接口)、JDBC/ODBC、Thrift Server和Hive Web Interface(HWI)等。,接下来分别对这几个组件进行介绍。
- Drvier组件
该组件是Hive的核心组件,该组件包括Complier(编译器)、Optimizer(优化器)和Executor(执行器),它们的作用是对Hive SQL语句进行解析、编译优化、生成执行计划,然后调用底层MR计算框架。
- MetaStore组件
该组件是Hive用来负责管理元数据的组件。Hive的元数据存储在关系型数据库中,其支持的关系型数据库有Derby和mysql,其中Derby是Hive默认情况下使用的数据库,它内嵌在Hive中,但是该数据库只支持单会话,也就是说只允许一个会话链接,所以在生产中并不适用,其实其实在平时我们的测试环境中也很少使用。在我们日常的团队开发中,需要支持多会话,所以需要一个独立的元数据库,用的最多的也就是Mysql,而且Hive内部对Mysql提供了很好的支持。
- CLI
Hive的命令行接口
- Thrift Server
该组件提供JDBC和ODBC接入的能力,用来进行可扩展且跨语言的服务开发。Hive集成了该服务,能让不同的编程语言调用Hive的接口
- Hive Web Interface
该组件是Hive客户端提供的一种通过网页方式访问Hive所提供的服务。这个接口对应Hive的HWI组件
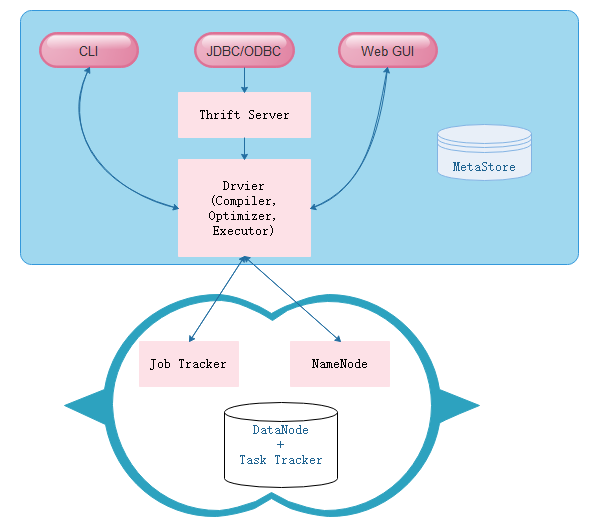
Hive通过CLI,JDBC/ODBC或HWI接受相关的Hive SQL查询,并通过Driver组件进行编译,分析优化,最后编程可执行的MapReduce任务,但是具体里面是怎么执行的,看图: