分析函数的应用场景:
(1)用于分组后组内排序
(2)指定计算范围
(3)Top N
(4)累加计算
(5)层次计算
分析函数的一般语法:
分析函数的语法结构一般是:
分析函数名(参数) over (子partition by 句 order by 字句 rows/range 字句)
1、分析函数名:sum、max、min、count、avg等聚合函数
lead、lag等比较函数
rank 等排名函数
2、over:关键字,表示前面的函数是分析函数,不是普通的聚合函数
3、分析字句:over关键字后面括号内的内容为分析子句,包含以下三部分内容
-
- partition by :分组子句,表示分析函数的计算范围,各组之间互不相干
- order by:排序子句,表示分组后,组内的排序方式
- rows/range:窗口子句,是在分组(partition by)后,表示组内的子分组(也即窗口),是分析函数的计算范围窗口
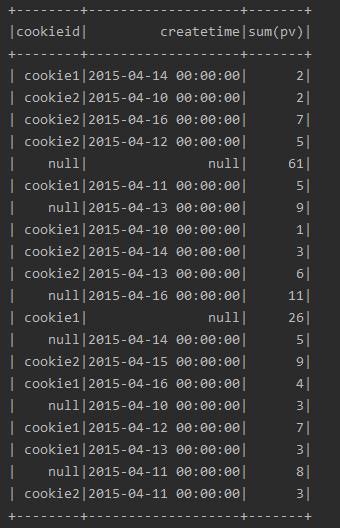
数据准备:
cookieid,createtime,pv cookie1,2015-04-10,1 cookie1,2015-04-11,5 cookie1,2015-04-12,7 cookie1,2015-04-13,3 cookie1,2015-04-14,2 cookie1,2015-04-15,4 cookie1,2015-04-16,4 cookie2,2015-04-10,2 cookie2,2015-04-11,3 cookie2,2015-04-12,5 cookie2,2015-04-13,6 cookie2,2015-04-14,3 cookie2,2015-04-15,9 cookie2,2015-04-16,7
val conf = new SparkConf()
val ssc = new SparkSession.Builder()
.appName(this.getClass.getSimpleName)
.master("local[2]")
.config(conf)
.getOrCreate()
val sc = ssc.sparkContext
sc.setLogLevel("WARN")
val df = ssc.read
.option("header", "true")
.option("inferschema", "true")
.csv("file:///E:/TestFile/analyfuncdata.txt")
df.show(false)
df.printSchema()
df.createOrReplaceTempView("table")
val sql = "select * from table"
ssc.sql(sql).show(false)
测试需求:
1、按照cookid进行分组,createtime排序,并前后求和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
|from table
""".stripMargin).show
运行结果:

2、与方式1 等价的写法
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
| sum(pv) over(partition by cookieid order by createtime
| rows between unbounded preceding and current row) as pv2
|from table
""".stripMargin).show
注:这里涉及到窗口子句,后面详细叙述。
运行结果:
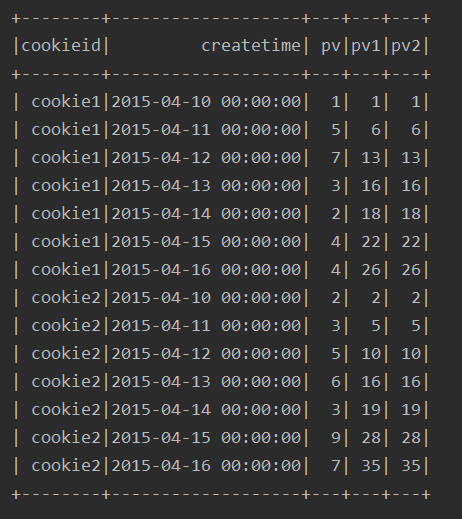
可以看到方式1的写法其实是方式2的一种默认形式
3、按照cookieid分组,不进行排序,求和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid) as pv1
|from table
""".stripMargin).show
运行结果:

可以看出,在不进行排序的情况下,最终的求和列是每个分组的所有值得和,并非前后值相加
4、不进行分组,直接进行排序,求和(有问题)
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(order by createtime) as pv1
|from table
""".stripMargin).show
运行结果:
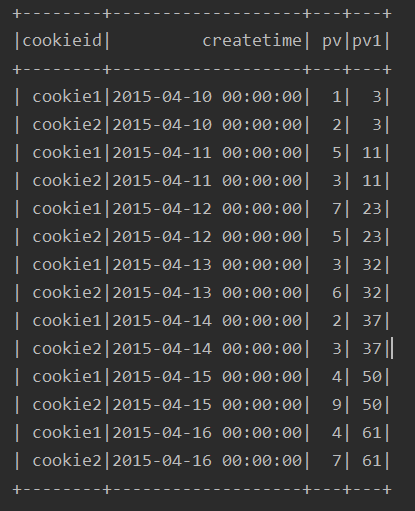
由结果可以看出,如果只是按照排序,不进行分区求和,得出来的结果好像乱七八糟的,有问题,所以我一般不这么做
5、over子句为空的情况下
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over() as pv1
|from table
""".stripMargin).show
运行结果:
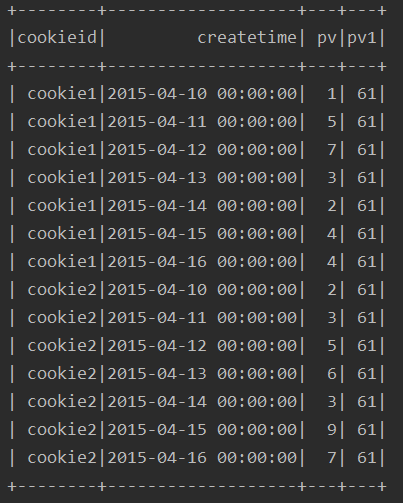
由结果看出,该种方式,其实就是对所有的行进行了求和
window子句
前面一开始执行了一个关于窗口子句:
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by createtime) as pv1,
| sum(pv) over(partition by cookieid order by createtime
| rows between unbounded preceding and current row) as pv2
|from table
""".stripMargin).show
同一个select查询中存在多个窗口函数时,他们相互之间是没有影响的,每个窗口函数应用自己的规则
rows between unbounded preceding and current row:
-
- rows between ... and ...(开始到结束,位置不能交换)
- unbounded preceding :从第一行开始
- current row:到当前行
当然,上述的从第几行开始到第几行是可以自定义的:
-
- 首行:unbounded preceding
- 末行:unbounded following
- 前 n 行:n preceding
- 后 n 行:n following
示例需求:
pv:原始值
pv1:起始行到当前行的累计值
pv2:等同于pv1,语法不同
pv3:仅有一个合计值
pv4:前三行到当前行的累计值
pv5:前三行到后一行的累计值
pv6:当前行到最后一行的累计值
注:这里所指的前三行,并不包含当前行本身
运行结果:

row & range
range:是逻辑窗口,是指定当前行对应值的范围取值,列数不固定,只要行值在范围内,对应列都包含在内
rows:是物理窗口,根据order by子句排序后,取前n行的数据以及后n行的数据进行计算(与当前行的值无关,至于排序由的行号有关)
需求案例:
1、对pv进行排名,求前一名到后两名的和
ssc.sql(
"""
|select cookieid,createtime,pv,
| sum(pv) over(partition by cookieid order by pv
| range between 1 preceding and 2 following) as pv1
|from table
""".stripMargin).show
运行结果:
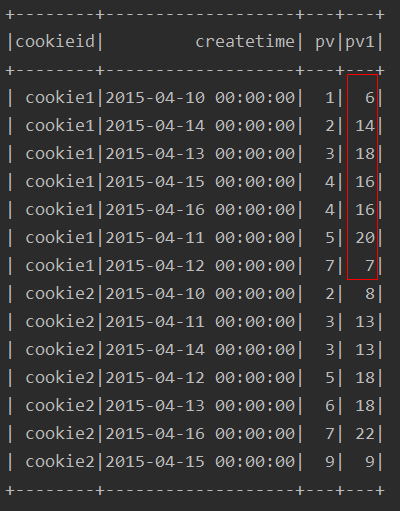
解释:

其他的聚合函数,用法与sum类似,比如:avg,min,max,count等
排名函数
排序方式:
-
- row_number() :顺序排,忽略 并列排名
- dense_rank() :有并列,后面的元素接着排名
- rank() :有并列,后面的元素跳着排名
- ntile(n) :用于将分组数据按照顺序切分成n片
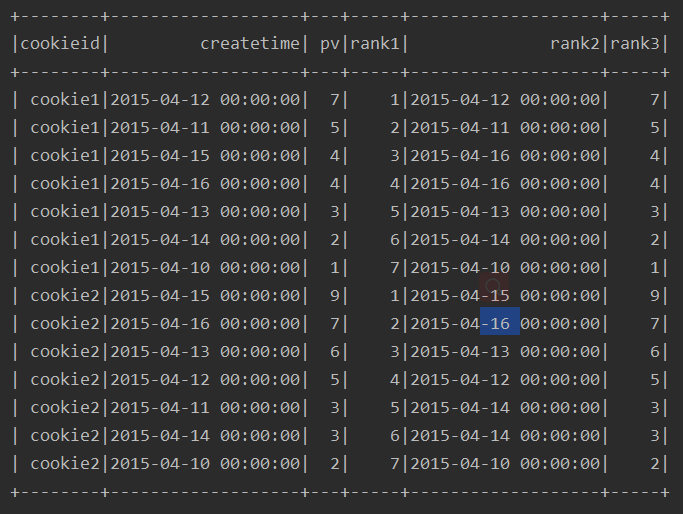
例:
ssc.sql(
"""
|select cookieid,createtime,pv,
| row_number() over(partition by cookieid order by pv desc) rank1,
| rank() over(partition by cookieid order by pv desc) rank2,
| dense_rank() over(partition by cookieid order by pv desc) rank3,
| ntile(3) over(partition by cookieid order by pv desc) rank4
|from table
""".stripMargin).show
运行结果:

lag & lead
lag(field,n):取前 n 行的值
lead(field n):取后 n 行的值
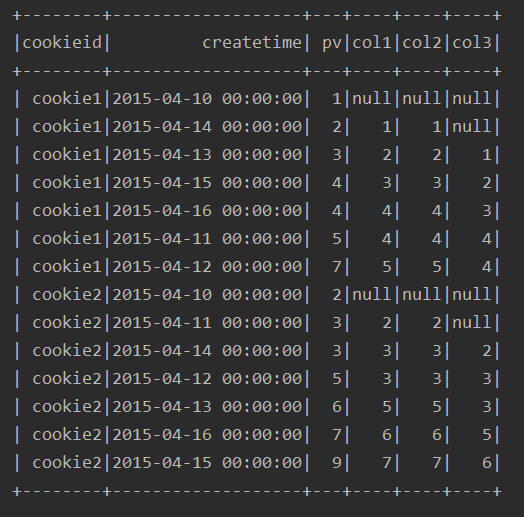
例:
ssc.sql(
"""
|select cookieid,createtime,pv,
|lag(pv) over(partition by cookieid order by pv) as col1,
|lag(pv,1) over(partition by cookieid order by pv) as col2,
|lag(pv,2) over(partition by cookieid order by pv) as col3
|from table
""".stripMargin).show
运行结果:
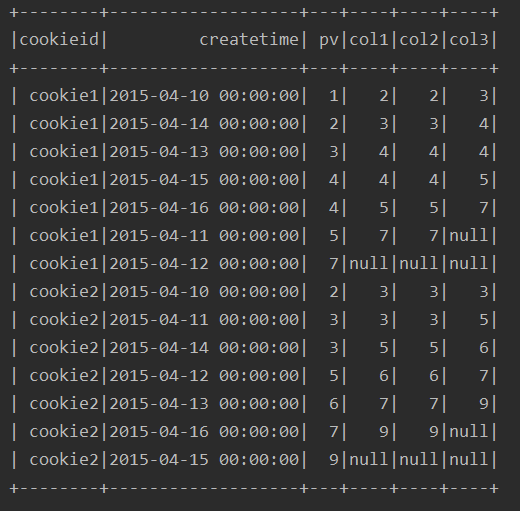
ssc.sql(
"""
|select cookieid,createtime,pv,
|lead(pv) over(partition by cookieid order by pv) as col1,
|lead(pv,1) over(partition by cookieid order by pv) as col2,
|lead(pv,2) over(partition by cookieid order by pv) as col3
|from table
""".stripMargin).show
运行结果:
ssc.sql(
"""
|select cookieid,createtime,pv,
|lead(pv,-2) over(partition by cookieid order by pv) as col1,
|lag(pv,2) over(partition by cookieid order by pv) as col2
|from table
""".stripMargin).show
运行结果:

first_value & last_value
first_value(field) :取分组内排序后,截止到当前行的第一个值
last_value(field) :取分组内排序后,截止到当前行的最后一个值
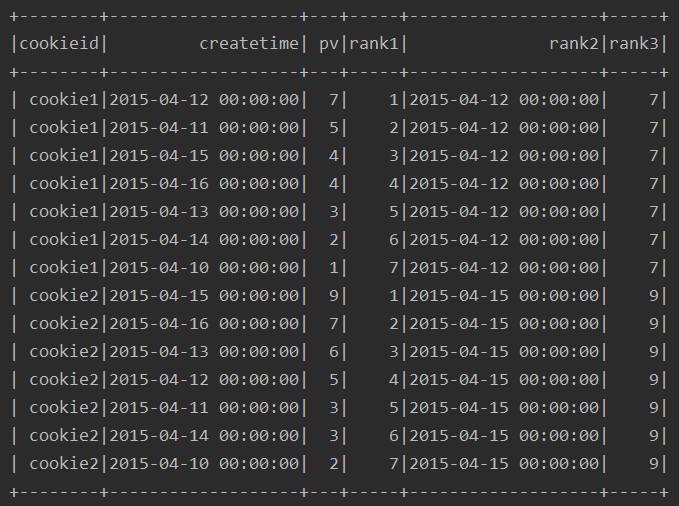
例:
ssc.sql(
"""
|select cookieid,createtime,pv,
|row_number() over(partition by cookieid order by pv desc) as rank1,
|first_value(createtime) over(partition by cookieid order by pv desc) as rank2,
|first_value(pv) over(partition by cookieid order by pv desc) as rank3
|from table
""".stripMargin).show
运行结果:
ssc.sql(
"""
|select cookieid,createtime,pv,
|row_number() over(partition by cookieid order by pv desc) as rank1,
|last_value(createtime) over(partition by cookieid order by pv desc) as rank2,
|last_value(pv) over(partition by cookieid order by pv desc) as rank3
|from table
""".stripMargin).show
运行结果:
cube & rollup
cube:根据group by维度的所有组合进行聚合
rollup:是cube的自己,以左侧的维度为主,进行层级聚合
例:
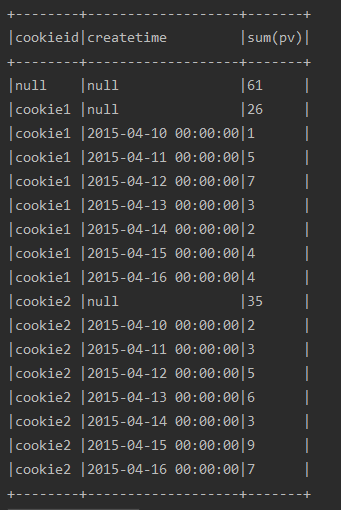
ssc.sql(
"""
|select cookieid,createtime,sum(pv)
|from table
|group by cube(cookieid,createtime)
|order by 1,2
""".stripMargin).show(100,false)
运行结果:

ssc.sql(
"""
|select cookieid,createtime,sum(pv)
|from table
|group by rollup(cookieid,createtime)
|order by 1,2
""".stripMargin).show(100,false)
运行结果:
DSL
import org.apache.spark.sql.expressions.Window
import ssc.implicits._
import org.apache.spark.sql.functions._
val w1 = Window.partitionBy("cookieid").orderBy("createtime")
val w2 = Window.partitionBy("cookieid").orderBy("pv")
//聚合函数
df.select($"cookieid", $"pv", sum("pv").over(w1).alias("pv1")).show()
//排名
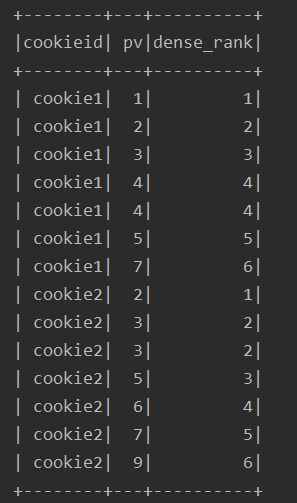
df.select($"cookieid", $"pv", rank().over(w2).alias("rank")).show()
df.select($"cookieid", $"pv", dense_rank().over(w2).alias("dense_rank")).show()
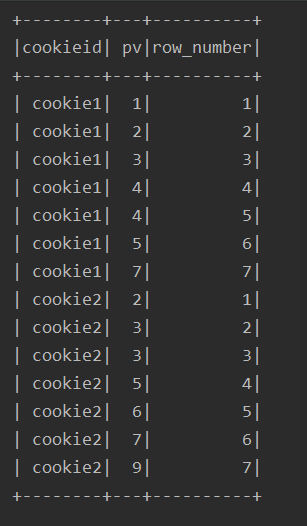
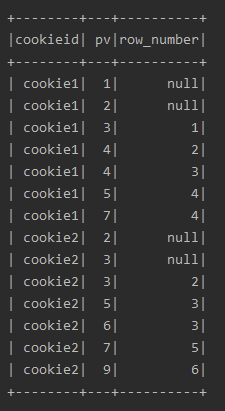
df.select($"cookieid", $"pv", row_number().over(w2).alias("row_number")).show()
//lag、lead
df.select($"cookieid", $"pv", lag("pv", 2).over(w2).alias("row_number")).show()
df.select($"cookieid", $"pv", lag("pv", -2).over(w2).alias("row_number")).show()
//cube、rollup
df.cube("cookieid", "createtime").agg(sum("pv")).show()
df.rollup("cookieid", "createtime").agg(sum("pv")).show()
运行结果:
1、聚合函数

2、排名函数:

lag、lead

cube、rollup