首先来说明一下bootstraps:可以把它认为是一种有放回的抽样方法。
bagging:boostraps aggregating(汇总)
boosting:Adaboot (Adaptive Boosting)提升方法
提升(boosting):在分类问题中,通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类的性能。
思想:提升方法就是从弱学习算法出发,反复学习,得到一系列弱分类器(基分类器),然后组合这些弱分类器,构成一个强分类器。
对一份数据,建立M个模型(比如分类),一般这种模型比较简单,称为弱分类器(weak learner)每次分类都将上一次分错的数据权重提高一点再进行分类,这样最终得到的分类器在测试数据与训练数据上都可以得到比较好的成绩。
1)改变训练数据的概率分布 2)改变数据权值分布。
AdaBoost:1)提高那些未被正确分类的样本权值,降低那些被分类正确的样本权值。这样分类错误的样本就被后来的分类器更大的关注。
2)采用加权多数表决,加大准确率高的分类器权值。
算法步骤:
(1)初始化权值
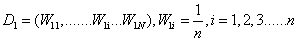
(2)使用具有权值分布的Dm的训练数据学习,得到基本分类器 Gm(x).
(3) 计算Gm(x)在训练数据集上的分类误差率
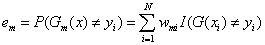
(4)计算Gm(x)的系数
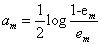
(5)更新权值分布(如果分类错误要提高权值,分类正确要降低权值(公式我就不打出来了))
不改变所给的训练数据,而是不断的改变数据的权值分布,使得训练数据在基本分类器的学习中起到不同的作用
(6)循环直到多个分类器都训练完。
(7)构建基本分类器
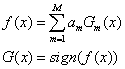
以后等我学了python,我在自己实现一遍。这是串行的,与之前的分类器的学习训练结果有关。,根据错误率采样。
bagging:
通过使用bootstrap随机选取训练数据集,分类器的训练建模师相互独立的,可以采取并行的方式。
bagging的基础是重复取样,通过产生样本的重复Bootstrap实例作为训练集,每回都是从总的样本随机选取和样本一样大小的数据(不一定一样规模),是有放回的,所以可能有的样本数据会重复出现。但其实就是利用这一点。这样通过增加训练数据的差异性生成有差异性的分类器,提高集成泛化能力。
对于这个的理论分析我就不说了,我他妈看不懂。。