1.概述
(1)单核CPU实现多任务原理:操作系统轮流让各个任务交替执行,qq执行2us,切换到微信,再执行2us,再切换到陌陌执行2us。。。表面上是看,每个任务反复执行下去,但是CPU执行速度太快了,导致我们感觉就像所有任务都在同时执行一样。
(2)多核CPU实现多任务原理:真正并行执行多任务只能在多核CPU上实现,但是因为任务数量远远多于CPU的核心的数量,所以操作系统也会自动把很多任务轮流调度到每个核心上执行
(3)并发(concurrency)
当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其他线程处于挂起状态,这种方式我们称之为并发
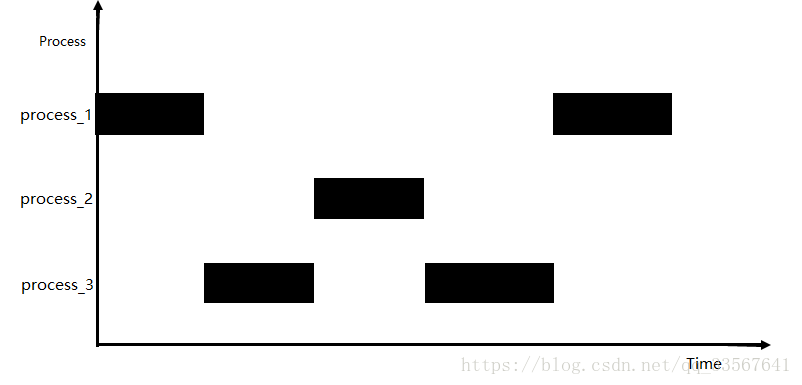
(4)并行(parallelism)
当系统有一个以上CPU时,则线程的操作有可能并非并发。当一个CPU执行一个线程时,另一个CPU执行另一个线程,两个线程互不抢占CPU资源,可以同时运行,我们称之为并行

(5)实现多任务的方式
- 多进程模式
- 多线程模式
- 协程
进程 > 线程 > 协程
一个进程中包含多个线程
一个线程中包含多个协程
2.进程
import os
from multiprocessing import Process
from time import sleep
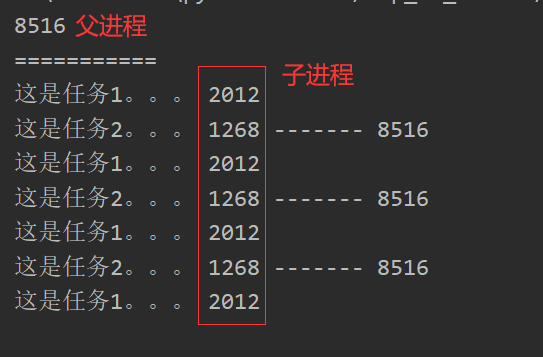
def task1():
while True:
sleep(1)
print('这是任务1。。。', os.getpid())
def task2():
while True:
sleep(1)
print('这是任务2。。。', os.getpid(), '-------', os.getppid())
if __name__ == '__main__':
print(os.getpid())
# 子进程
p = Process(target=task1, name='任务1')
p.start()
p = Process(target=task2, name='任务1')
p.start()
print('===========')
创建进程的方法:
from multiprocessing import Process
process = Process(target=函数, name=进程的名字, args=(给函数传递的参数))
process --- 对象
对象调用方法:
process.start() --- 进程启动,并执行任务
process.run() --- 只是执行了任务,但是没有启动进程
terminate() --- 终止进程
使用terminate()函数
from multiprocessing import Process
from time import sleep
def task1(s):
while True:
sleep(s)
print('这是任务1...')
def task2(s):
while True:
sleep(s)
print('这是任务2...')
number = 0
if __name__ == '__main__':
# 子进程
p1 = Process(target=task1, args=(1, ))
p1.start()
p2 = Process(target=task2, args=(2, ))
p2.start()
while True:
number += 1
sleep(0.2)
if number == 15:
p1.terminate()
p2.terminate()
break
else:
print('----->number:', number)
print('******************')
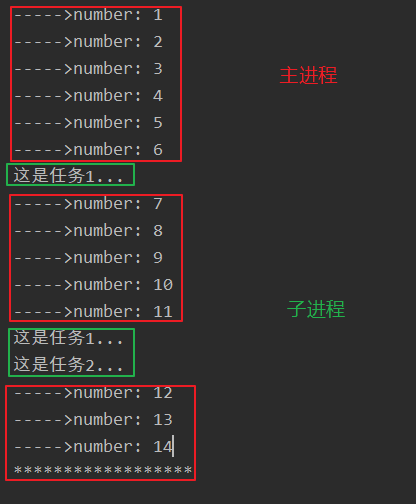
这些代码的执行都是主进程完成的。
进程的执行顺序是由CPU控制调度的
多进程对于全局变量访问,在每一个全局变量里面都放了一个m变量,保证每个进程访问变量互不干扰
from multiprocessing import Process
from time import sleep
m = 1
def task1(s):
global m
while True:
sleep(s)
m += 1
print('这是任务1...', m)
def task2(s):
global m
while True:
sleep(s)
m += 1
print('这是任务2...', m)
if __name__ == '__main__':
# 子进程
p1 = Process(target=task1, args=(1, ))
p1.start()
p2 = Process(target=task2, args=(2, ))
p2.start()
while True:
sleep(1)
m += 1
print('******************main:', m)

注意:每个函数里面对全局变量的修改,都需要global m
3.自定义进程
为什么要自定义进程?
在原来的task函数中如果想调用进程的方法,就需要自定义进程,继承父类Process,这样就可以把父类里面的东西都拿到子类里面
from multiprocessing import Process
class MyProcess(Process):
def __init__(self, name):
# 将父类里面所有的东西都拿过来
super(MyProcess, self).__init__()
self.name = name
# 重写run方法
def run(self):
n = 1
while True:
print('{} -----> 自定义进程,n:{}'.format(n, self.name))
n += 1
if __name__ == '__main__':
p = MyProcess('小米')
# 只有调用start,就会调用自定义的run
p.start()
只要创建对象,就会去找init,再去找父类的init
p.start()做两件事:1.开新的进程,2.调用run()